Après avoir bien saisi l’analyse en composantes principales (ACP) au Chapitre 23, il importe ici de réaliser maintenant une limitation qui lui est associée. Nous avons mentionné plusieurs fois qu’une des assomptions de l’ACP est qu’elle recherche des relations linéaires. Cela fonctionne bien pour beaucoup de phénomènes, particulièrement lorsque l’on parle de variables abiotiques.
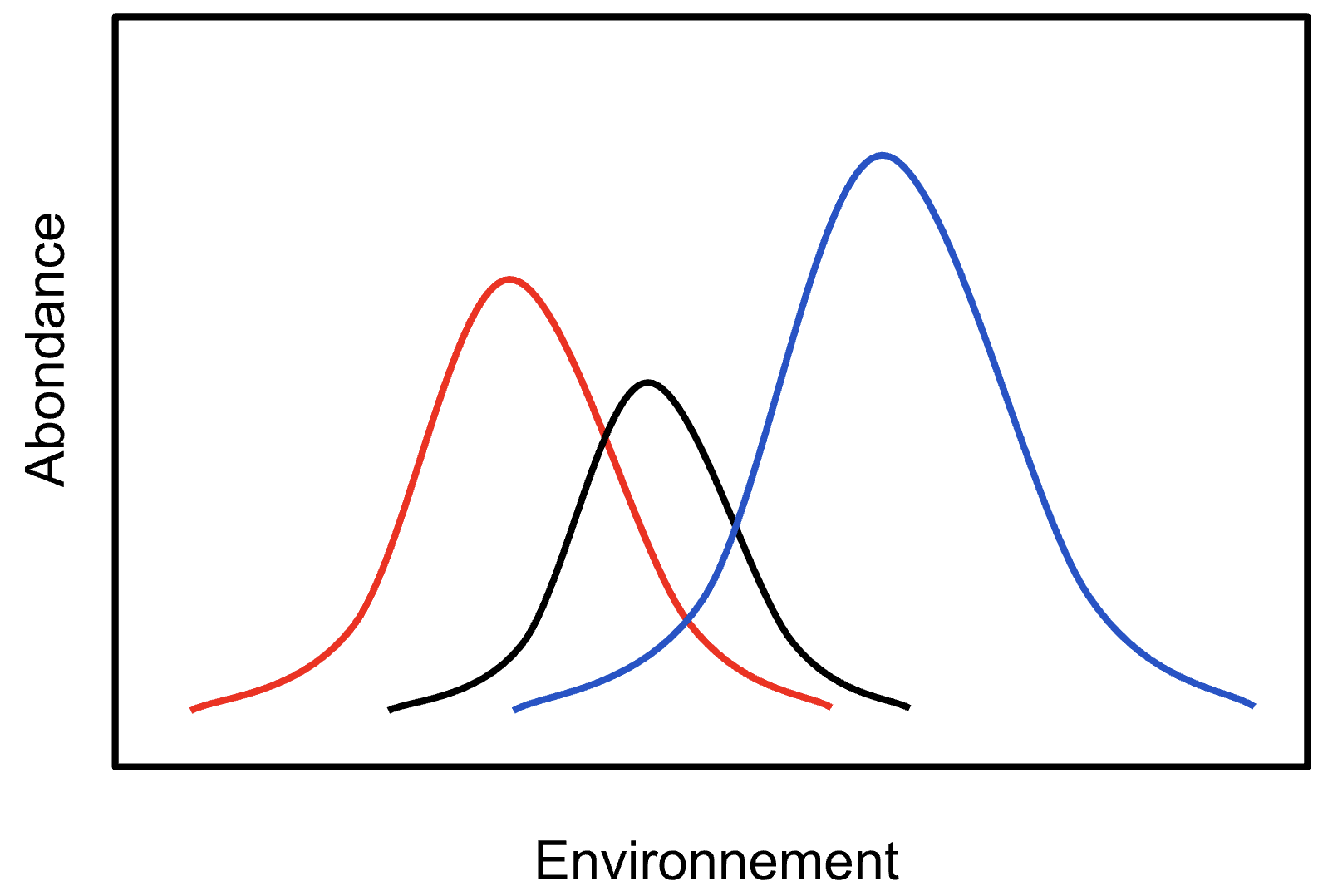
Par contre, si nos variables sont des abondances d’espèces et que l’on réfléchit un peu à leur écologie, on réalise souvent que leur réponse à l’environnement est rarement linéaire. L’évolution a plutôt tendance à créer des réponses en forme de cloche face à un gradient environnemental. Chaque espèce ayant tendance à préférer certaines valeurs, et à être moins présente lorsque l’on s’éloigne de sa valeur idéale, soit d’un côté ou de l’autre. Un peu comme nous, on est bien quand il fait 21°C, mais à 40°C ou à 0°C, on est moins confortables.
Visuellement, on peut facilement s’imaginer trois espèces, dont les abondances varient comme ceci à travers un gradient environnemental (p. ex. pH, ouverture de la canopé, etc.) :
Si l’on voulait regarder l’association entre ces trois espèces dans une ordination, l’ACP ne serait pas l’analyse appropriée, puisqu’elle ne cherche que des relations linéaires. C’est pourquoi, pour ce genre de situations, il existe un autre type d’ordination, nommé en français l’analyse factorielle des correspondances (AFC) ou correspondance analysis (CA) en anglais.
Chaque fois que les variables dans votre matrice de données seront des abondances d’espèces, il sera approprié d’utiliser cette analyse.
Notez bien que pour que l’analyse fonctionne, il n’est pas nécessaire d’avoir étudié l’ensemble de la courbe d’une espèce. L’analyse fonctionnera tout aussi bien si vous n’avez attrapé que la partie ascendante ou descendante de la courbe.
24.2 Fonctionnement de l’AFC
L’AFC est en fait une sorte de croisement entre l’ACP et l’analyse de khi-carré (voir Chapitre 19). Plutôt que d’utiliser directement la matrice de données pour créer une matrice de variance-covariance, l’AFC travaille sur une matrice des différences entre les comptes observés et ceux attendus selon une hypothèse d’indépendance entre les variables et les sites (exactement comme dans le test de khi-carré). On applique ensuite à ces différence une double-transformation sur chaque valeur, en les divisant par le produit de la racine carrée du total de la colonne et de la ligne : \[
\frac{(o_{ij}-e_{ij})}{\sqrt{r_i}\sqrt{c_j}}
\]
Comme dans les autres chapitres, il n’est pas si important de se rappeler de la formule exacte. Ce qu’il est surtout important de comprendre est que plus variables (i.e. les espèces) ou les observations (i.e. les sites) seront associés, plus les valeurs dans la matrice seront élevées. Au contraire, si nos espèces ou nos sites sont entièrement indépendants les uns des autres (i.e. si les espèces sont réparties aléatoirement dans les sites), les valeurs seront très près de zéro.
Une fois cette matrice de valeurs constituée, l’AFC applique une série d’opérations matricielles pour résumer la variation dans une série de nouvelles variables. Par contre, contrairement à l’ACP, on obtient au bout de l’opération deux séries d’eigenvectors, soit une pour les espèces et l’autre pour les sites. Tout comme dans l’ACP, le premier axe aura l’eigenvalue le plus élevé, les axes suivant se répartissant la variation restante. Au total, l’AFC produira \(min(n,p)-1\) axes différents. C’est-à-dire le plus petit nombre entre le nombre de colonnes moins 1 ou et le nombre de lignes moins 1 de la matrice de données.
Habituellement, on n’interprète qu’un ou deux axes de l’AFC, car ces axes sont censés correspondre à des gradients environnementaux et l’interprétation de trois axes indépendants peut devenir rapidement très abstraite.
Comme nous en avons déjà discuté précédemment, la chose la plus difficile avec les ordinations est probablement de maîtriser le vocabulaire et les abréviations (qui sont en plus mentionnées en anglais dans les sorties de R). Pour l’AFC, vous devrez en particulier savoir que la somme des eigenvalues (ce qui correspond au khi-carré total de la matrice divisé par le nombre d’observations) s’appelle dans cette analyse l’inertie. Il s’agit d’une mesure d’association (lack of independance) entre les lignes et les colonnes. Dans les sorties d’une AFC, vous pouvez donc lire les valeurs d’inertie comme vous liriez les eigenvalues dans l’ACP.
24.3 Assomptions
L’AFC assume deux choses importantes à propos de vos données pour faire ses calculs. Contrairement à certaines autres analyses où on peut étirer les assomptions, ici elles doivent être clairement respectées. La première est que toutes les variables doivent être mesurées dans les mêmes dimensions physiques. Vous ne pourriez PAS avoir certaines colonnes avec des dénombrement d’individus et d’autres avec des mesures de pH par exemple. L’autre condition importante est que, comme pour l’analyse de khi-carré, toutes les valeurs doivent être des entiers positifs ou des zéros. On ne peut PAS calculer une AFC sur une matrice d’abondances relatives ou avec des pourcentages.
Vous lirez aussi parfois dans des rapports ou des articles que l’AFC est une analyse qui est sensible aux espèces rares (i.e. celles ayant de très faibles abondances et apparaissant rarement dans les données). Ce qu’il est important de comprendre est que, comme le rapportent Legendre et Legendre (Numerical Ecology 1998, p. 462), cette sensibilité n’est qu’apparente. Les espèces rares, de par leurs faibles abondances, ont très peu de poids dans le calcul comme tel. Elles peuvent néanmoins apparaître à des endroits un peu extrêmes dans les graphiques. C’est pourquoi la recommandation de Legendre (et la mienne du même coup!) est de conserver toutes les espèces pour les calculs, et de simplement cacher les espèces rares au moment de la visualisation. Vous lirez néanmoins parfois dans des rapports ou des articles que les espèces rares ont été supprimées avant le calcul d’une AFC.
24.4 Labo : L’AFC
Pour essayer l’analyse factorielle des correspondances dans R, nous allons devoir charger une base de données externes, nommée oiseaux.xlsx1. Cette dernière contient l’abondance d’une dizaine d’espèces d’oiseaux notées à une dizaine de sites durant ma maîtrise au Parc national de la Mauricie.
Commençons donc par charger les librairies nécessaires et la base de données Excel. Comme pour l’ACP, nous devrons cacher la colonne contenant le nom des sites pour que l’AFC puisse s’effectuer correctement, mais garder le nom des sites dans les graphiques.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(readxl)library(vegan)
Loading required package: permute
Loading required package: lattice
This is vegan 2.6-8
Pour calculer l’AFC, il faudra utiliser la fonction de vegan nommée ca (Correspondance analysis).
afc <-ca(oiseaux)
Pour visualiser le résultats de l’AFC, la façon rapide est à l’aide de la fonction plot, appelée sur notre objet de résultats :
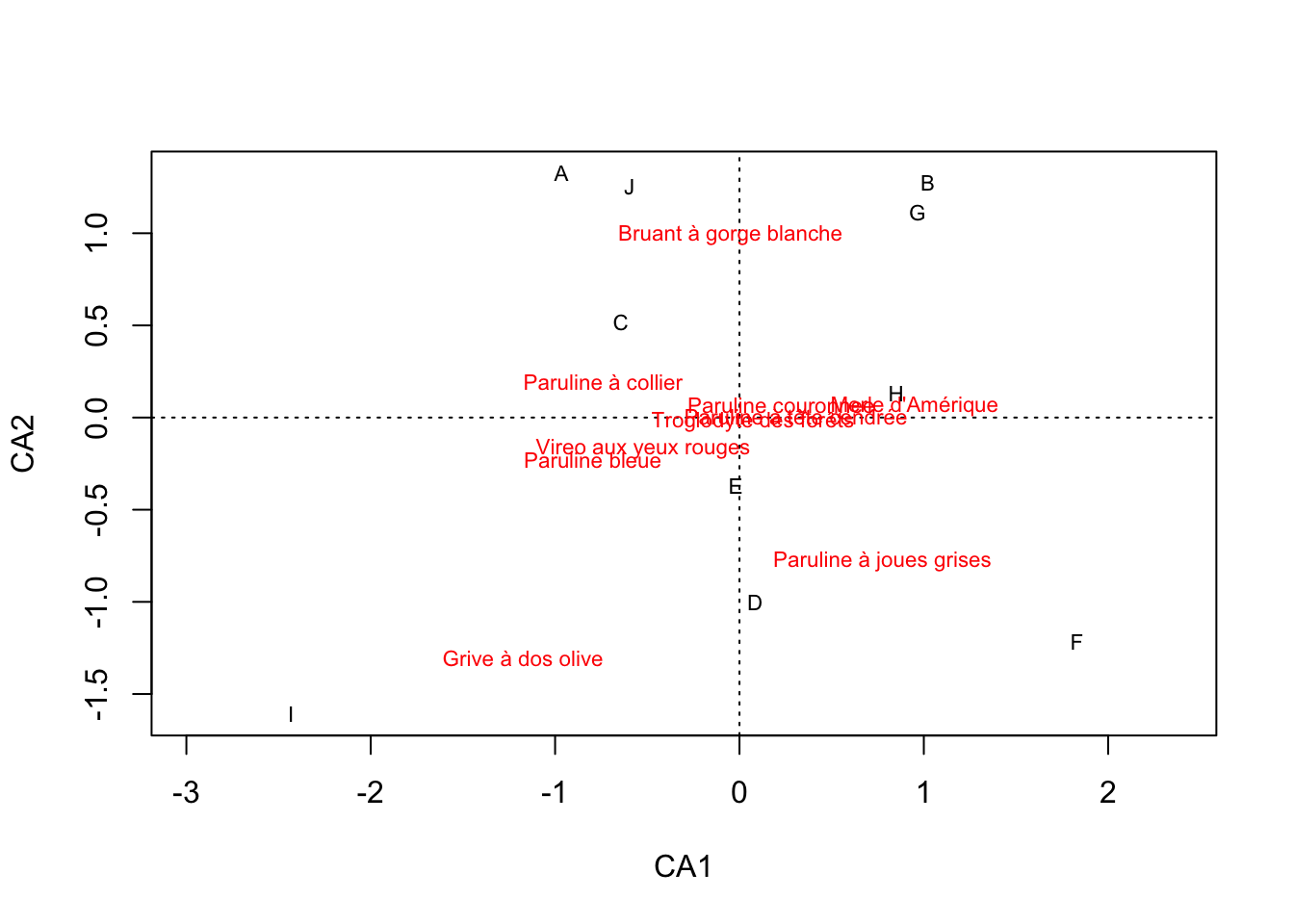
plot(afc)
Si vous voulez personnaliser ce graphique, toutes les techniques montrées avec ggplot2 au Chapitre 23 fonctionneront de façon identique, à part pour le nom des axes qui se nommeront CA1 et CA2 plutôt que PCA1 et PCA2, etc.
On peut obtenir l’ensemble des eigenvalues et eigenvectors de notre analyse à l’aide de la fonction summary, comme ceci :
En se basant sur ces sorties, on peut voir que les deux premiers axes de l’AFC expliquent ensemble 59% de la variabilité dans notre matrice d’abondances.
Dans le graphique, on peut constater que les deux espèces les plus extrêmes sur l’axe 1 sont le Merle d’Amérique d’un côté et la Grive à dos olive de l’autre. On peut donc en conclure que ces deux espèces sont rarement retrouvées ensemble. Si l’une est présente, l’autre sera presque toujours absente.
Remarquez qu’ici, l’AFC ne peut pas nous renseigner sur les causes de ce phénomène. Il pourrait être causé, entre autres, parce que ces deux espèces s’évitent parce qu’elles sont en compétition directe une avec l’autre, ou simplement parce qu’elles utilisent des milieux tellements différents qu’un site ne peut jamais correspondre en même temps aux besoins des deux espèces.
24.5 Exercice : L’AFC
À l’aide du tableau de données dune inclu avec la librairie vegan (utilisez la fonction data(dune) pour l’activer), calculez une AFC et répondez aux questions suivantes.
Pour votre information, le tableau de données est formé d’observations concernant 30 espèces de plantes observées dans 20 sites dans les dunes néerlandaises. Vous pouvez en savoir plus sur ces données avec la commande ?dune
Les données sont-elles appropriées pour appliquer une AFC?
Quel pourcentage de la variance est expliqué par le premier axe?
Et par le deuxième?
Quelles espèces sont les plus représentatives du premier axe de l’AFC?
Avancez une hypothèse sur les causes de ce gradient
Et pour le deuxième axe, quelles sont les espèces les plus représentatives?