Les test de comparaison de variance ont plusieurs utilités. Ils peuvent être utilisés pour déterminer si un groupe est plus variable qu’un autre (ce chapitre ci). Mais aussi, bizarrement, à savoir si les moyennes de plusieurs groupes sont différentes les unes de autres (voir Chapitre 15)
Comme expliqué au Chapitre 13, ce test a aussi déjà été utilisé par le passé pour savoir si on devait appliquer un test de T pour variances égales ou un test de Welch.
14.1 Le test de F
Le test de F est un test destiné à comparer la variance entre deux groupes pour savoir si elle est statistiquement différente. Il pourrait être utilisé par exemple pour tester l’hypothèse que la taille des oiseaux en milieu urbain est plus homogène (i.e. moins variable) qu’en milieu naturel. Vous pourriez donc avoir capturé 20 oiseaux en milieu urbain et mesuré leur poids, puis 40 en milieu naturel et aussi mesuré leur poids.
Généralement dans la littérature, on utilisera le terme homoscédastique pour désigner des jeux de données ayant la même variance et hétéroscédastique pour des jeux de données ayant des variances différentes.
Étape 1 : Définir les hypothèses
Les hypothèses statistiques du test de F sont pour l’hypothèse nulle (H0) que les variances sont égales entre les groupes et l’hypothèse alternative (H1) est qu’il existe une différence de variance entre les deux groupes.
Pour notre exemple sur les oiseaux, nos hypothèses statistiques seraient donc les suivantes : \[
\begin{aligned}
H_0: \sigma^2_{urbain} = \sigma^2_{naturel}\\
H_1: \sigma^2_{urbain} \ne \sigma^2_{naturel}
\end{aligned}
\] Remarquez à nouveau que pour les hypothèses, on utilise le symbole grec de la variance (σ2) et non celui de l’échantillon (s2).
Étape 2 : Explorer visuellement les données.
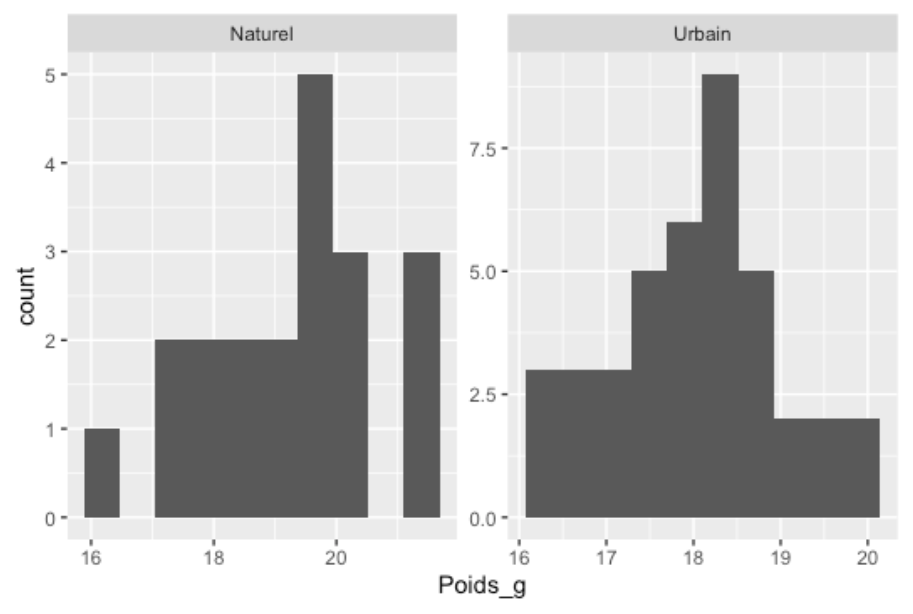
Le test de F ne compte que deux assomptions. La première, qui est commune à tous les tests, est l’indépendance des observations. Cette assomption est surtout dépendante du design de l’expérience. La deuxième assomption, encore ici, est que les observations proviennent de distributions normales. Mais cette fois-ci, il faut être un peu plus stricte, puisque le théorème central limite ne s’applique qu’aux moyennes des échantillons, alors qu’ici, nous travaillerons avec les ratios de leurs variances. La façon la plus simple de vérifier ce fait est tout de même de faire un histogramme de fréquence de chacun de nos échantillons. Comme le test de F est relativement sensible aux écarts à la normalité, il faut être relativement strict sur cette assomption.
À première vue, rien ne suggère que les échantillons ne proviendraient pas de distributions normales, on peut donc procéder à la suite.
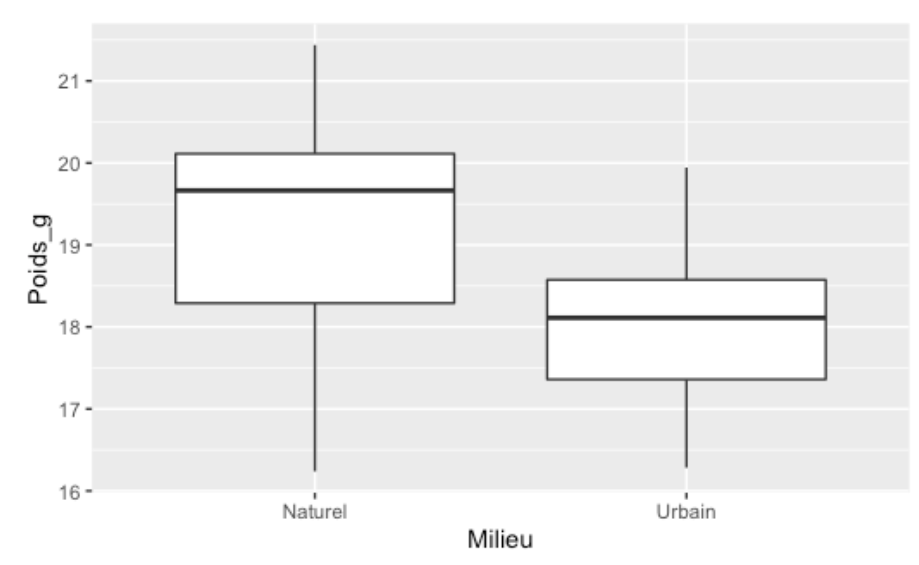
Une fois les assomptions vérifiées, on peut passer à la visualisation du test comme tel. Pour regarder si un échantillon est plus variable qu’un autre, on peut, entre autres, utiliser un diagramme à moustache et comparer la taille des boîtes :
Ici, il faut bien comprendre la nuance entre une différence de moyenne et une différence de variance. Les oiseaux en milieu urbain semblent à première vue plus petits (médiane environ 18 g vs. presque 20 g pour le milieu naturel), mais ce n’est pas cette question qui nous intéresse. Nous nous intéressons à la variabilité (la taille des boîtes). Bien que la boîte présente l’écart interquartile plutôt que la variance, elle donne quand même une bonne idée de la variabilité. Ici, les oiseaux en milieu urbain semblent moins variables (boîte plus petite) que ceux en milieu naturel. Il ne faudrait pas s’étonner que cette différence soit significative puisque l’on observe facilement la différence à l’œil nu.
Étape 3 : Calculer la statistique de test.
La statistique du test de F a été définie par les mathématiciens comme ceci : \[
F = \frac{s_1^2}{s_2^2}
\] Autrement dit, la statistique se calcule comme le ratio de la variance d’un échantillon divisé par la variance du deuxième. On utilise ici le symbole s puisque l’on parle des données de l’échantillon. Dans cette équation, on place toujours la variance la plus élevée au numérateur (en haut) et la plus faible au dénominateur (en bas). Donc, intuitivement, plus nos variances sont différentes l’une de l’autre, plus la valeur de F sera grande. Si nos variances sont absolument égales, F vaudrait 1.
Si dans notre exemple la variance des oiseaux urbains est de 0,886 g2 et celle des oiseaux en milieu naturel est de 2,10 g2, notre statistique de F sera de 2,37. Autrement dit, la variance du milieu naturel est un peu plus de 2x plus grande que celle en milieu urbain.
Étape 4 : Obtenir la valeur de p.
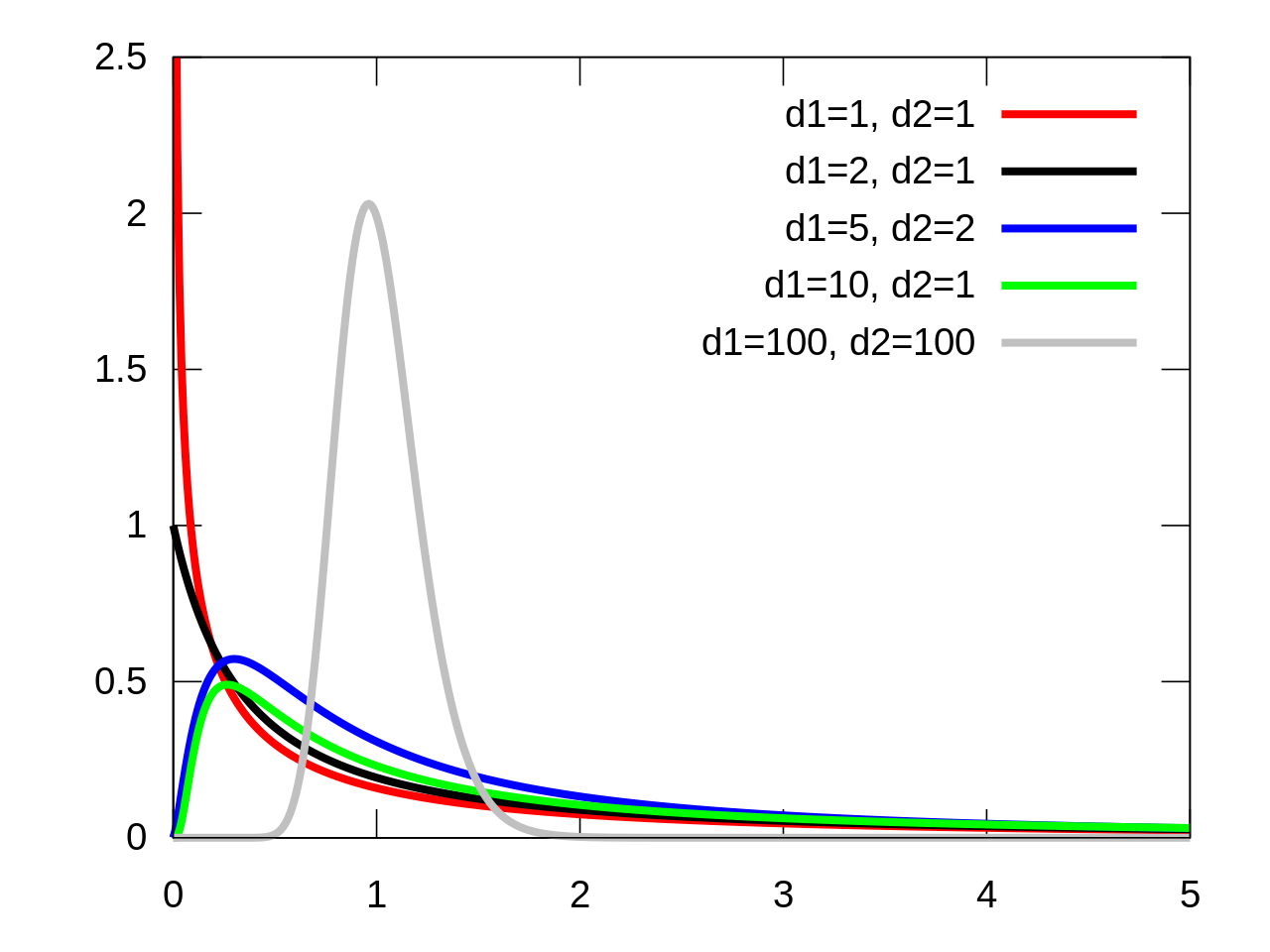
Il faut maintenant déterminer si obtenir une telle valeur de F est rare ou non lorsque l’on pige deux échantillons dans des populations de variances égales (notre hypothèse nulle). Les mathématiciens ont décrit la distribution de F exactement pour ce genre de situations. La distribution de F se définit par deux paramètres, soit les degrés de liberté du numérateur et du dénominateur. Et contrairement à la distribution de T, la distribution de F peut être asymétrique :
La distribution de F pour différents degrés de liberté (d1 et d2).IkamusumeFan, CC BY-SA 4.0, via Wikimedia Commons
Les degrés de liberté du numérateur et du dénominateur se définissent comme n1-1 pour le numérateur et n2-1 pour le dénominateur.
Pour notre exemple, avec une valeur de F de 2,37 et des degrés de liberté de 19 et 39, nous obtenons une valeur de p de 0,023. Vous pourriez récupérer cette valeur manuellement à l’aide de la fonction pf de R, mais R fera ce calcul pour vous dans le test.
Étape 5 : Rejeter ou non l’hypothèse nulle
À ce point, nous pouvons maintenant prendre notre décision statistique. Puisque notre événement est plus rare que le seuil de signification (p < 0,05), on peut rejeter l’hypothèse nulle. Les variances de nos deux groupes sont significativement différentes.
Étape 6 : Citer la magnitude de l’effet et son intervalle de confiance.
Dans le cadre d’une utilisation du test de F pour vérifier les assomptions d’un test, vous pouvez vous arrêter à l’étape précédente. Par contre, si vous avez utilisé le test de F pour tester une hypothèse biologique ou écologique comme dans notre exemple, vous devrez aussi présenter l’intervalle de confiance associé aux résultats.
Dans le cadre du cours, je ne vous demanderai pas de calculer manuellement cet intervalle. Sachez seulement qu’il est représenté dans les résultats de R, et que pour notre exemple, il se situe entre 1,13 et 5,53. Autrement dit, le ratio de la variance de nos deux populations se situe de façon très probable entre un peu plus de 1 (à peine plus grand) et 5x plus grand. Notez que cet intervalle exclut 1 (l’égalité des variances), ce qui explique que notre test soit significatif.
Dans un rapport, vous pourriez écrire ce résultat comme ceci : «Il existait une différence significative de variance du poids des oiseaux entre les milieux urbains et naturels (F19,39 = 2,37, p = 0,023).»
14.2 Labo : Le test de F
Assumons pour ce laboratoire que nous savons que l’île Biscoe de l’archipel Palmer est beaucoup plus diversifiée en termes de niches écologiques que l’île Torgersen. Nous pourrions donc émettre l’hypothèse que le poids des manchots Adélie sur l’île de Biscoe devrait être plus variable que celui de l’île de Torgersen, si la variété de niches affecte l’alimentation des manchots.
Pour faciliter l’exploration visuelle de nos données, nous créerons deux mini-tableaux de données contenant uniquement les manchots Adélie de l’île Biscoe et Torgersen, comme ceci :
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
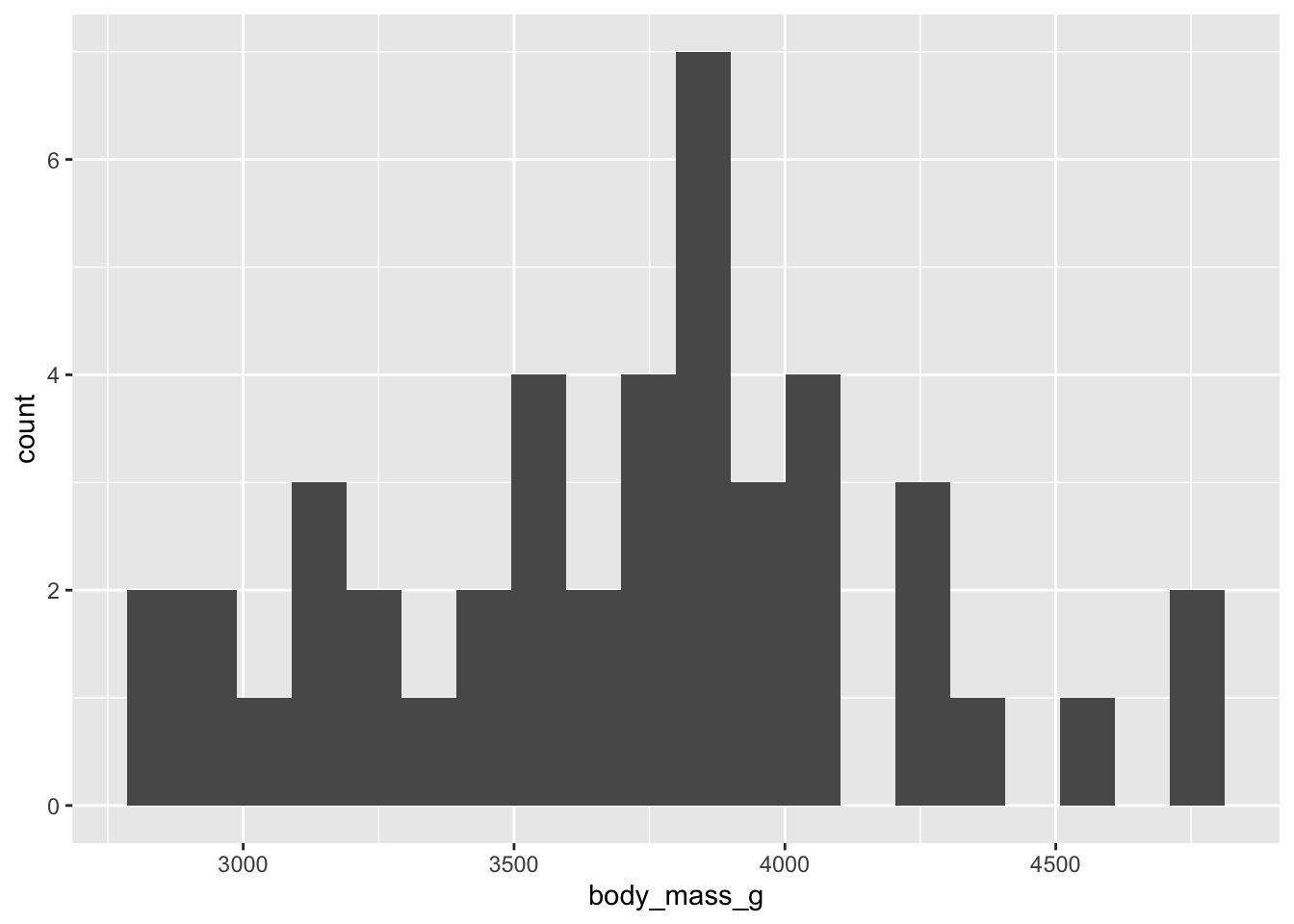
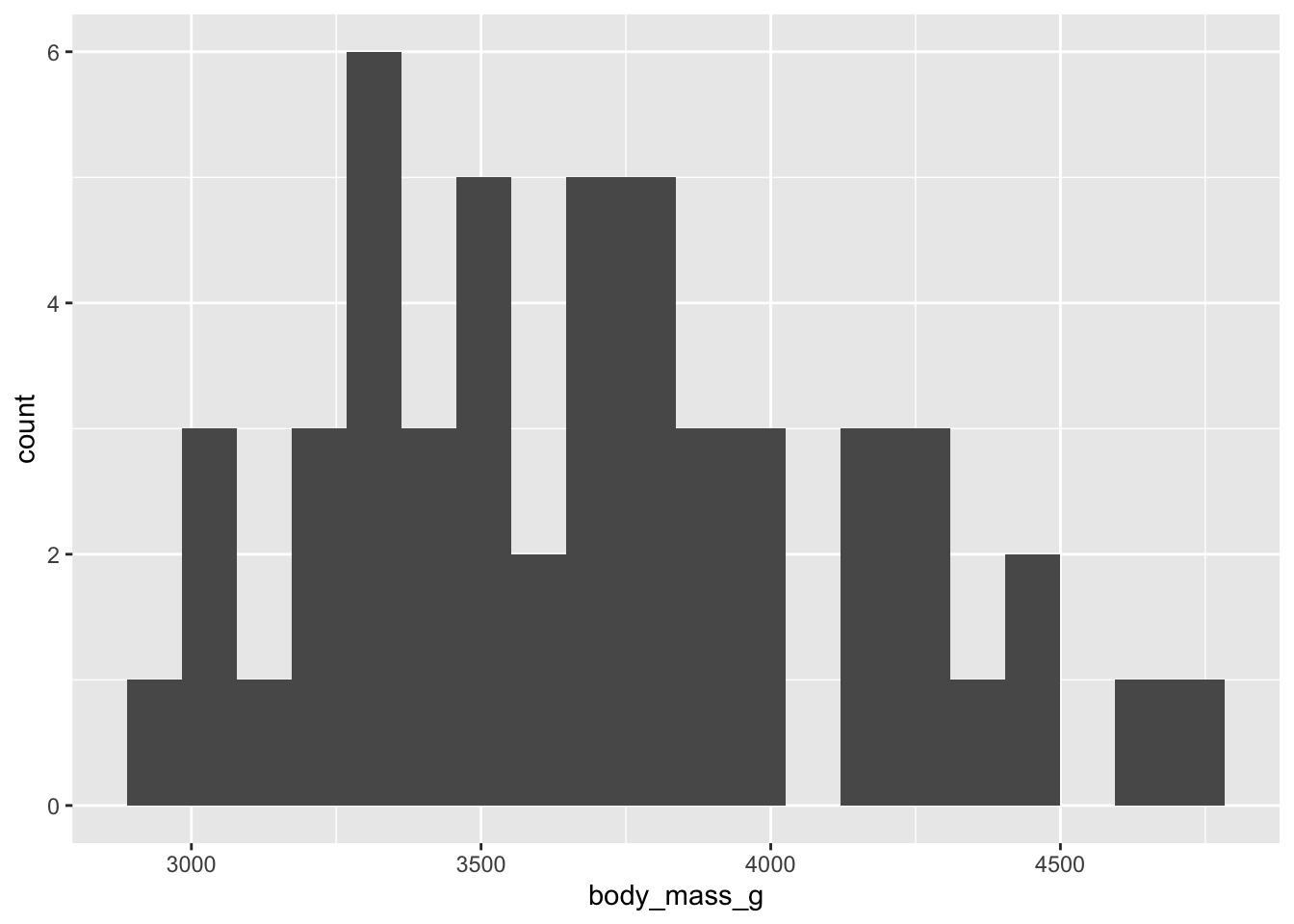
Nos distributions sont relativement normales, rien pour nous inquiéter ici.
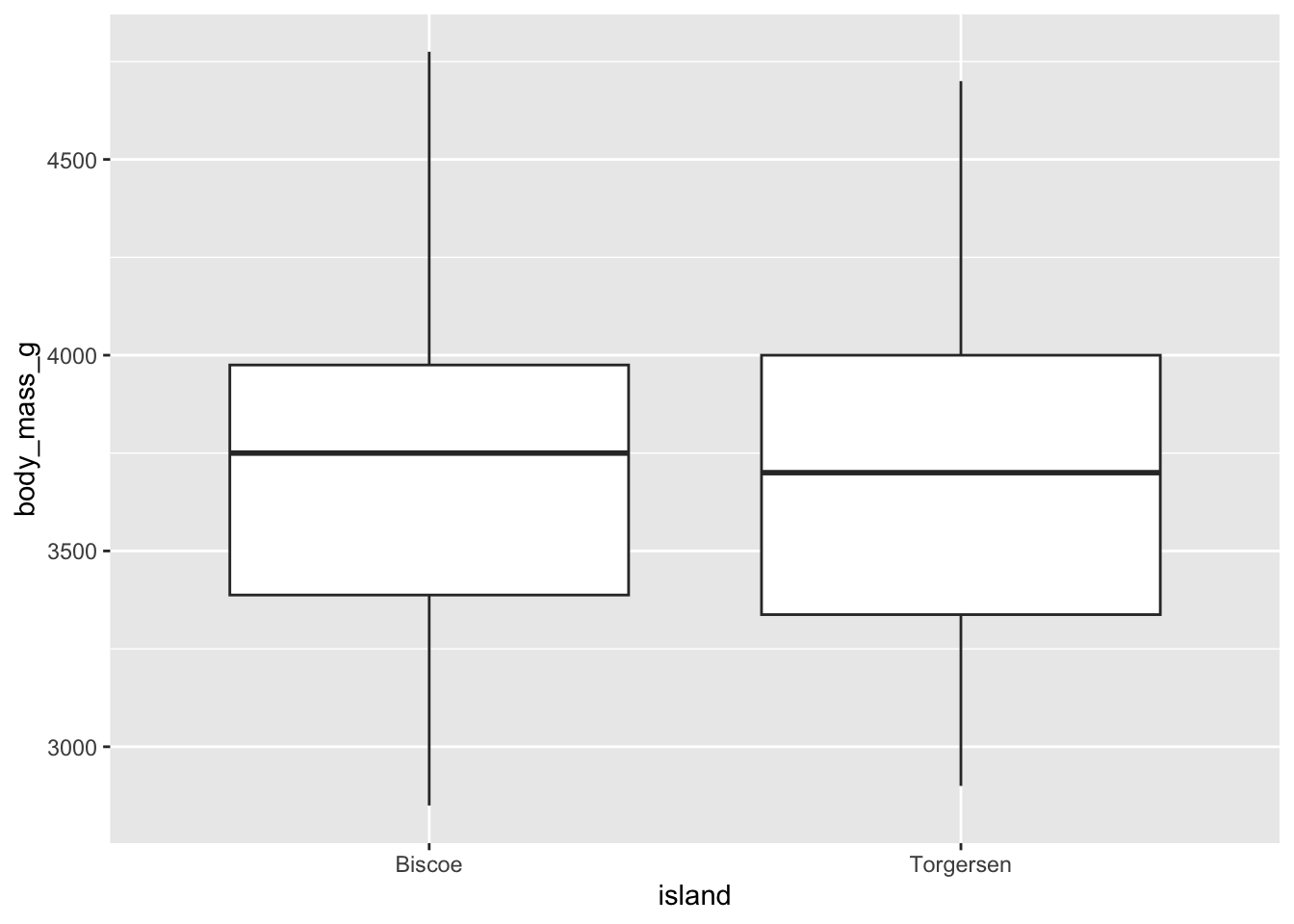
On peut ensuite se représenter visuellement le résultat du test, à l’aide d’un diagramme à moustaches :
adelie |>ggplot(aes(x = island, y = body_mass_g)) +geom_boxplot()
À première vue, on ne s’attend pas à trouver une grande différence dans la variabilité de ces deux groupes : la taille des deux boîtes est TRÈS semblable.
Étapes 3 et 4
La fonction pour calculer le test de F dans R se nomme var.test (comme “test de variance”). Il existe plusieurs façons de spécifier les données de ce test, mais la plus directe est d’aller chercher (comme pour le test de T) les valeurs de la bonne colonne à l’aide de l’opérateur $, comme ceci :
F test to compare two variances
data: biscoe$body_mass_g and torgersen$body_mass_g
F = 1.2007, num df = 43, denom df = 50, p-value
= 0.5307
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.6741525 2.1663828
sample estimates:
ratio of variances
1.200701
La première ligne nous indique qu’effectivement, R a appliqué un test de F. Ensuite, il nous rappelle avec quelles données il a fait le test. Puis il nous fournit la statistique de test qu’il a calculée (F, le ratio des deux variances), les degrés de liberté (num df et denom df) et la valeur de p (p-value). Les dernières lignes nous rapportent le ratio des variances et son intervalle de confiance.
Étape 5 :
Comme l’événement observé est relativement commun (p=0,5307), on ne peut pas rejeter l’hypothèse H0 au seuil de 0,05. Il n’y a pas de différence significative entre la variance du poids des manchots Adélie entre ces deux îles.
Autrement dit, il est très commun d’observer des différences telle qu’un ratio de 1,20 avec une telle taille d’échantillon, si les variances des deux populations sont égales.
On pourrait donc écrire ce résultat comme ceci :
«Il n’existait pas de différence significative entre les variances du poids des manchots Adélie des îles Torgersen et Biscoe (F43,50 = 1,20, p = 0,5307).»
14.3 Comparer plus de deux variances
Lorsque nous nous attaquerons à des tests plus complexes permettant de gérer plus de deux échantillons à la fois, vous aurez à vous demander s’il existe une différence de variance significative dans l’ensemble ces derniers. Une façon de faire relativement simple dans ces cas est de tester s’il existe une différence significative entre le groupe ayant la variance la plus élevée et le groupe ayant la variance la moins élevée. Si cette différence est significative, vous savez que l’assomption n’est pas respectée. Si la différence n’est pas significative, vous pouvez assumer que toutes les autres variances ne sont pas différentes les unes des autres.
Si jamais il vous arrive d’avoir à tester des différences de variance pour lesquelles vous voulez regarder plus en détail chacun des groupes, sachez qu’il existe pour ce genre de situation le test de Levene et le test de Bartlett, mais que ces deux tests dépassent le cadre de ce que nous aurons besoin dans ce livre.
14.4 Exercice : Le test de F
Vous savez, de part vos lectures antérieures, que la forme du corps des poissons est reliée au type de milieu dans lequel ils vivent. Pour tester si cette théorie a des implications pour la biodiversité, vous posez la question à savoir si la taille des poissons est plus variable dans les lacs comprenant des fosses que dans les lacs qui n’ont pas vraiment de zones profondes.
Vous avez capturé et mesuré (en cm) :
12 poissons dans un lac sans fosse [28, 22, 22, 28, 26, 23, 25, 21, 24, 21, 26, 24] et
8 poissons dans un lac avec fosse [23,20,28,25,25,29,29,22].
Évaluez à l’aide d’un test de F si la variance est différente entre ces deux lacs. Autrement dit, est-ce que la taille des poissons est plus diversifiée dans les lacs comprenant une fosse que dans les lacs n’en comprenant pas?
{kind=link}