Dans ce chapitre, nous verrons une technique pour tester l’association entre deux variables quantitatives. Nous voudrons déterminer s’il existe une relation entre nos deux variables. On entend par relation que, si une des variable change, l’autre changera systématiquement dans un sens donné.
Évidemment il y aura aussi du bruit autour de la relation, elle ne sera pas parfaite. On parlera de relation positive lorsque les deux variables augmentent simultanément, et de relation négative lorsque l’augmentation d’une variable entraîne la diminution d’une autre.
Notez que l’on ne parle pas de changement dans le temps, mais plutôt du portrait de la situation lorsqu’on regarde une série d’observations où on a mesuré les deux variables, un gradient. L’analyse des séries temporelles comme tel est un sujet avancé, que nous ne verrons pas dans ce manuel.
17.1 Corrélation de Pearson
Sans doute une des statistiques les plus connues et les plus utilisées, la corrélation de Pearson, permet d’évaluer la force de l’association entre deux variables et d’informer sur le sens (positif ou négatif) de celle-ci. Bien qu’il existe d’autres corrélations (p. ex. celle de Spearman), si quelqu’un vous parle de corrélation sans donner d’autre détail, il vous parle assurément de la corrélation de Pearson.
Avant de vous lancer dans une analyse de corrélation, vous devez vous assurer que vos données correspondent à ce qu’attend la procédure. Outre le fait que vos observations doivent être indépendantes, la corrélation de Pearson assume aussi que vos données présentent une relation linéaire et qu’elles sont distribuées normalement. Si l’une ou l’autre de ces conditions n’est pas remplie, vous pouvez appliquer une méthode alternative, soit la corrélation de Spearman. Nous reviendrons sur cette méthode dans le Chapitre 21.
Le calcul de la corrélation est basé sur une statistique nommée la covariance. La covariance mesure combien deux variables varient une avec l’autre. Si les deux variables augmentent ensemble, ce chiffres sera grand et positif. Si lorsqu’une augmente l’autre diminue, ce chiffre sera très négatif, et si les variables ne sont pas reliées, ce chiffre sera près de zéro. Comme il n’est pas critique de le maîtriser ici, nous reporterons les détails du calcul de la covariance à la Section 22.4.
Le problème majeur de la covariance est que sa valeur dépend des unités dans lesquelles ont été mesurées nos données. Si par exemple on change des m pour des km, notre covariance pourrait devenir beaucoup plus petite. Ce genre de problème rend extrêmement complexe les comparaisons entre les jeux de données.
C’est pourquoi le calcul de la corrélation inclut un facteur de correction, qui remet toutes les données à la même échelle. Conceptuellement, on peut donc décrire la corrélation comme ceci :
Soit que la corrélation (r) entre X et Y se mesure comme la covariance entre les deux variables, divisée par le produit de leur écart-types.
Ce facteur de correction fait en sorte que la valeur de la corrélation se retrouvera toujours entre -1 et 1. Une valeur de -1 présentant une relation négative parfaite (i.e. sans bruit), 0 une absence de relation et 1 une relation positive parfaite.
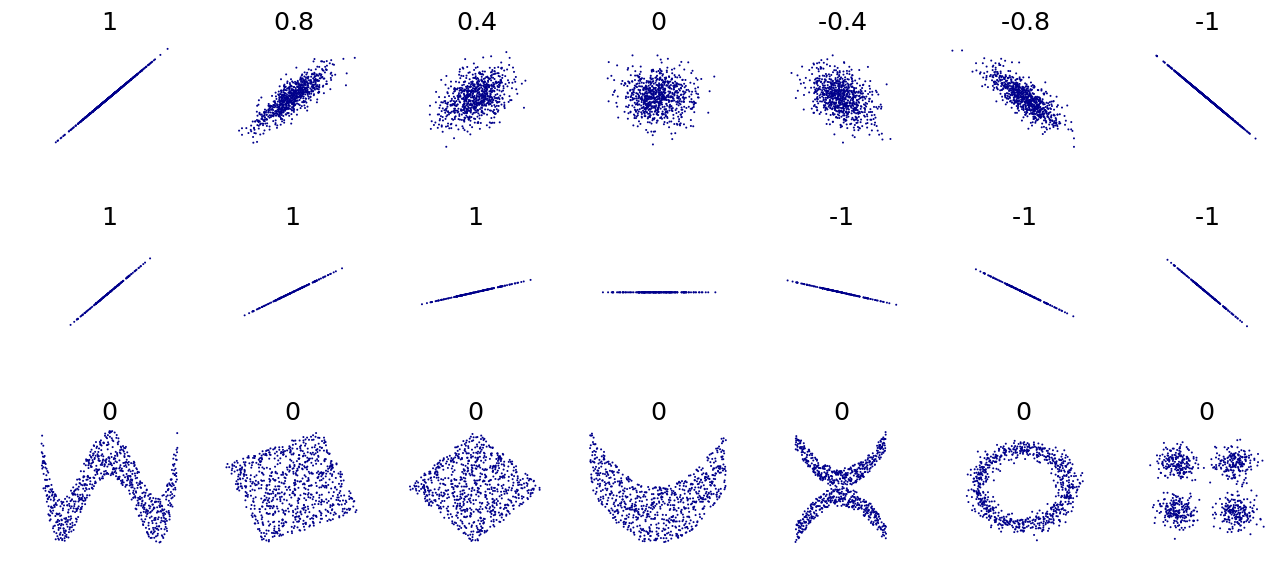
Voici, pour vous donner une idée, quelques exemples de relations et les valeurs de corrélation qui leur sont associées :
Remarquez particulièrement avec la dernière ligne de cette figure que la corrélation ne mesure que des relations linéaires dans les données. Elle n’est pas appropriée pour mesurer d’autres formes.
Si vous voulez vous entraîner à bien évaluer la force d’une corrélation, sachez qu’il existe des jeux en ligne créées exactement à cette fin1. Je vous conseille d’en essayer quelques parties pour vous faire l’œil avant de continuer.
Enfin, il est important de comprendre que trouver une corrélation entre deux variables ne veut PAS dire que ces deux variables sont effectivement reliées par un mécanisme quelconque. Il existe d’ailleurs un adage anglais qui illustre bien ce propos : correlation is not causation. Pour vous donner une idée, allez visiter le site Spurious Correlations2. Ce site a recensé les corrélations les plus loufoques que l’on pouvait trouver, et en ont même fait un livre. Ils montrent, entre autres, qu’il existe une corrélation de 0,66 entre le nombre de films de Nicolas Cage et le nombre de décès par noyade…
Tout ça pour dire que, soyez prudentes, réfléchissez bien à votre question écologique avant de vous lancer dans toutes sortes de statistiques!
17.2 Tester une corrélation de Pearson
La majorité du temps, la corrélation de Pearson sera utilisée comme tel : on calcule la valeur de r, on l’interprète, et c’est tout. Il pourra cependant arriver que l’on vous demande de savoir si cette valeur de r est significative (i.e. significativement différente de zéro) ou non, particulièrement si votre échantillon est petit ou votre valeur de r plutôt faible. Voici donc la procédure pour tester cette corrélation.
Nous travaillerons la corrélation de Pearson avec un petit exemple où vous avez mesuré la transparence de l’eau (m) dans 24 lacs à l’aide d’un disque de Secchi3 et la densité de poissons par filet installé. Vous voulez savoir si ces deux mesures sont associées ou non.
Étape 1 : Définir les hypothèses
L’hypothèse nulle de ce test est que la corrélation entre les deux variables est de zéro, et l’hypothèse alternative est qu’elle est différente de zéro.
Notez que le symbole de la corrélation, lorsque l’on discute de la valeur de la population est le symbole grec rhô (ρ). Le r étant en général réservé aux échantillons.
Étape 2 : Explorer visuellement les données
Comme nous avons discuté précédemment, il y a deux assomptions que l’on peut vérifier à ce point avec nos données, soit la linéarité de la relation et la normalité des distributions.
La linéarité de la relation peut être établie à l’aide d’un nuage de points montrant les deux variables d’intérêt :
En plus de permettre d’évaluer la linéarité de la relation, ce graphique nous permet aussi de se faire une idée sur la valeur de corrélation que l’on devrait trouver. Ici, “au pif” je dirais que l’on devrait s’attendre à quelque chose qui tourne autour de 0,7.
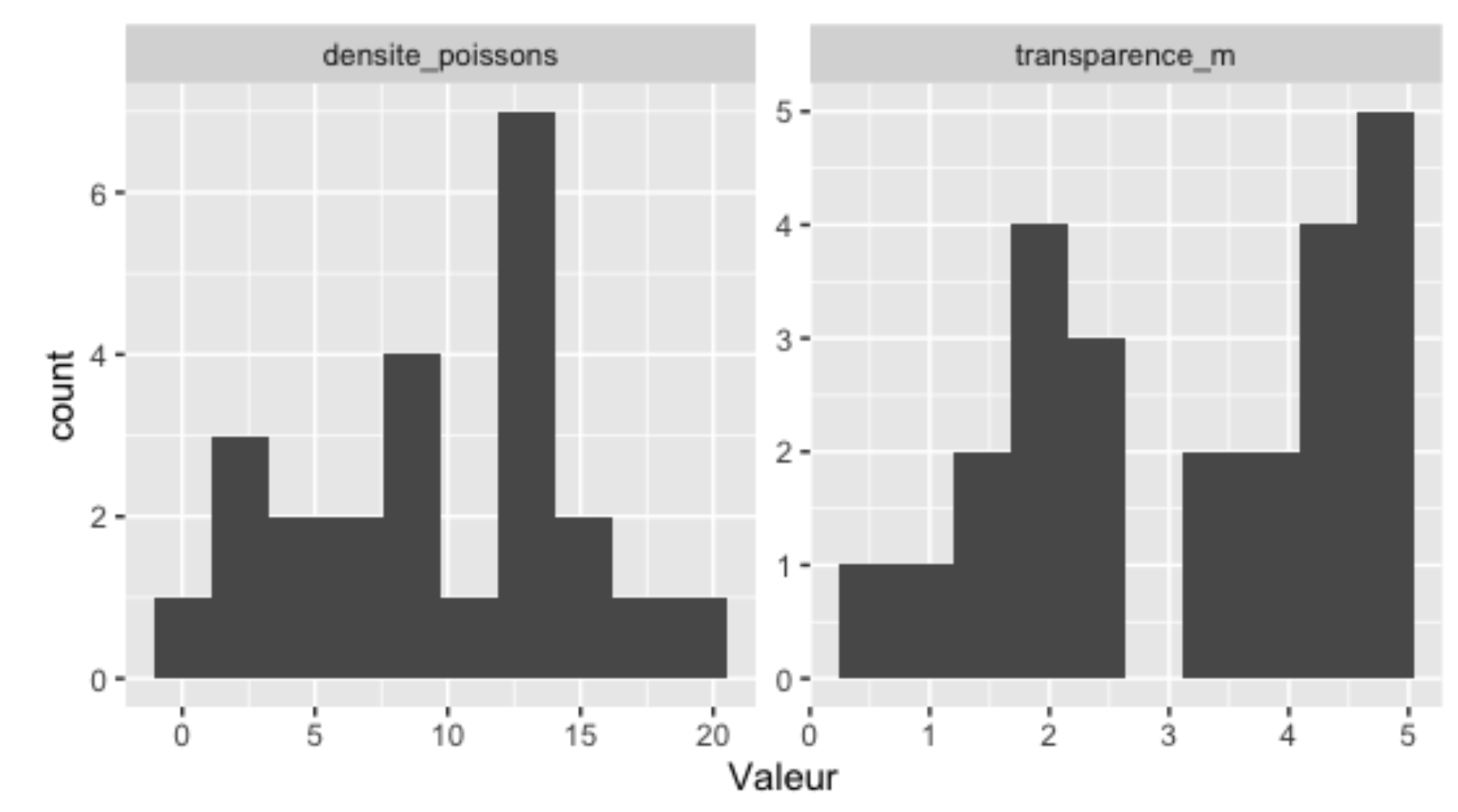
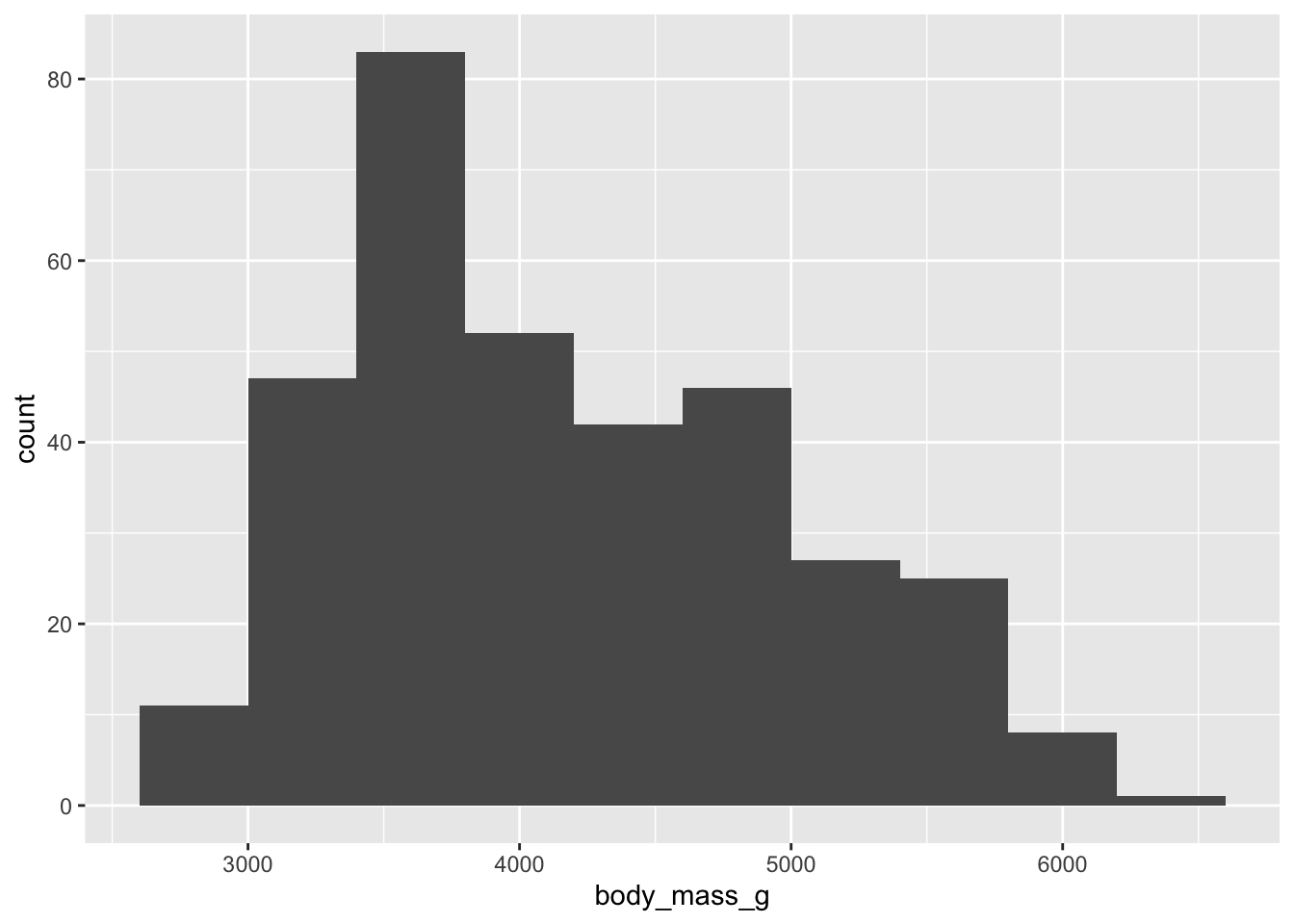
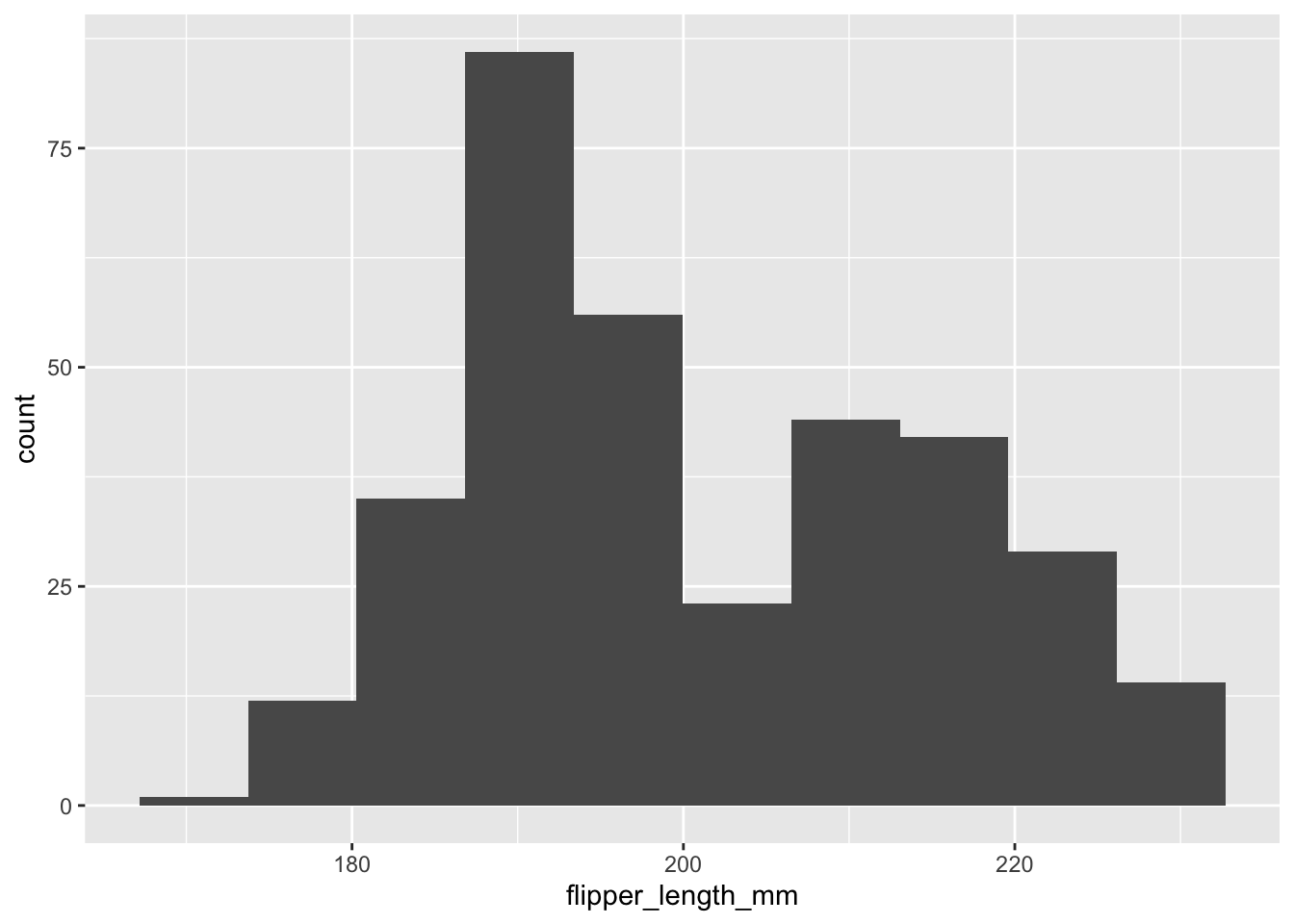
La normalité des deux variables s’évalue facilement, quant à elle, à l’aide d’histogrammes :
Nos histogrammes ne sont clairement pas parfaits, mais étant donné notre faible taille d’échantillon, on ne peut pas dire qu’ils suggèrent une absence claire de normalité.
Encore ici, en présence de grands échantillons, le théorème central limite conférera au test une plus grande robustesse, mais pas de façon aussi directe que pour les tests de T. Ses priorités prennent plus d’échantillons avant de se réaliser.
Étape 3 : Calculer la statistique de test
La première étape du test est bien sûr de calculer notre valeur de r. Dans notre exemple, la valeur calculée est de 0,833. Ensuite, le test de cette corrélation s’effectue en calculant une valeur de t, à l’aide de la formule suivante :
\[
t = \frac{r\sqrt{n-2}}{\sqrt(1-r^2)}
\]
Où n est la taille de notre échantillon et r est la valeur de la corrélation. Pour notre exemple, cette valeur de t sera donc de 6,98.
Étape 4 : Obtenir la valeur de p
Comme tous les autres tests jusqu’à présent, le test de corrélation est basé sur la probabilité de trouver une corrélation aussi grande si il n’y avait aucune association entre les populations. Rappelez vous qu’en général, deux populations non reliées ne présenteront pas de corrélation, mais qu’une fois de temps en temps, ça peut arriver, comme pour le nombre de films de Nicolas Cage et le nombre de décès par noyade!
On va donc trouver dans la distribution de t la probabilité associée à la valeur de t trouvée, pour nos n-2 = 22 degrés de liberté. Pour notre exemple, on trouve une valeur de p de 0,000000044.
Étape 5 : Rejeter ou non l’hypothèse nulle
Comme notre valeur de p est plus petite que la valeur seuil de 0,05 (i.e. rare), on considère que notre corrélation est significativement différente de zéro.
Étape 6 : Citer la magnitude de l’effet et son intervalle de confiance
La magnitude de l’effet dans cette analyse est la valeur de r trouvée. Vous n’aurez que très rarement à rapporter l’intervalle de confiance de cette corrélation, et dans tous les cas, vous n’aurez pas à la calculer manuellement. Néanmoins, si vous avez besoin d’y arriver, sachez que l’erreur-type de la corrélation se calcule comme suit :
\[
s_r = \sqrt{\frac{
(1-r^2)
}{
(n-2)
}}
\]
Dans R, le calcul basé sur cette erreur-type et la valeur de T pour n-2 degrés de liberté et un intervalle à 95 % nous donne un intervalle de confiance situé entre 0,64 et 0,92. Autrement dit, la vraie valeur de la population se situe probablement entre ces deux valeurs.
Comme discuté précédemment, ces valeurs sont rarement rapportées. On écrit habituellement ce genre de résultat comme suit : «La transparence de l’eau et la densité de poissons étaient fortement corrélées (r=0,83)».
Notez que l’adjectif “fortement” doit être utilisé en relation de ce que l’on connaît du système à l’étude. Une corrélation de 0,83 pour une mesure physique où l’on évalue par exemple l’expansion d’un métal avec la chaleur serait considérée comme extrêmement faible. Dans d’autre contextes, par exemple si l’on essaie de trouver à quoi est reliée à la richesse en espèces d’une communauté locale d’oiseaux, alors cette valeur serait extrêmement élevée, puisque l’on trouve rarement des valeurs > 0,30 à cause de la nature aléatoire de la composition des communautés d’une année à l’autre.
Aussi, méfiez-vous toujours des très fortes corrélations, particulièrement si vous arrivez à la valeur r = 1. À tout coup, il s’agit d’une erreur dans les calculs…
17.3 Labo : Corrélation de Pearson
Pour ce petit laboratoire, nous allons explorer la présence d’une association entre la longueur des ailes et la taille du corps chez les manchots de Palmer.
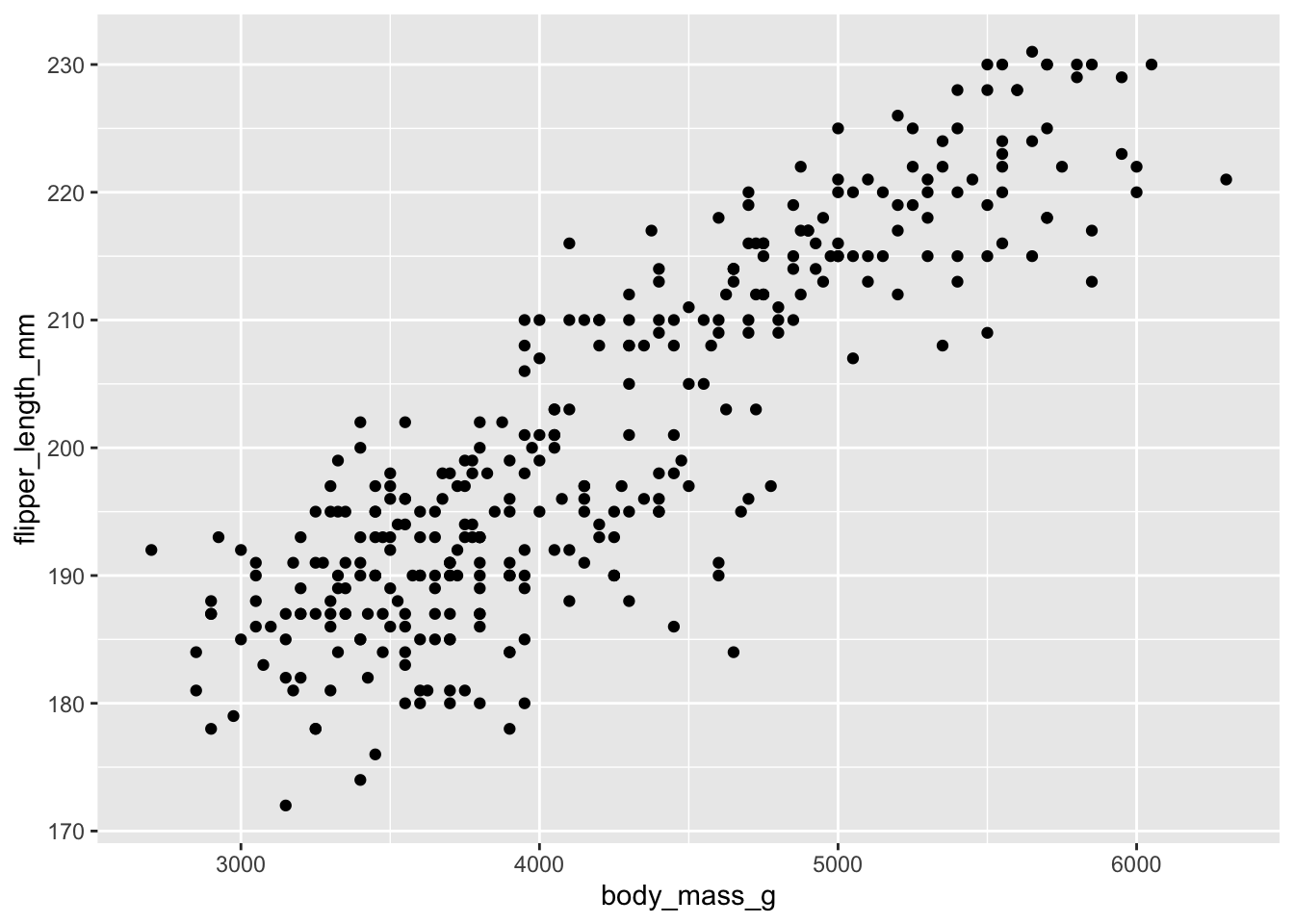
Les deux choses importantes à vérifier avant de lancer notre analyse de corrélation sont la linéarité de la relation et la normalité des deux distributions. Voici le code R pour y parvenir :
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
Il serait difficile d’obtenir une relation plus parfaitement linéaire!
Si jamais la relation avait été clairement non-linéaire, il aurait été préférable d’utiliser la corrélation de Spearman (voir Section 21.7) plutôt que celle de Pearson pour effectuer vos calculs.
Comme nos tailles d’échantillons sont relativement grandes, on peut passer sans stress à l’étape suivante, même si les distributions ne sont pas parfaitement normales.
Une fois ces vérifications effectuées, on peut calculer la corrélation à l’aide la fonction cor, qui attend deux arguments, soit les deux vecteurs contenant nos données :
cor(propre$body_mass_g, propre$flipper_length_mm)
[1] 0.8712018
Donc le poids du corps et la taille des ailes sont fortement corrélés positivement chez les manchots de Palmer (r=0,87).
Enfin, si on veut tester si cette corrélation est significative ou non, on peut utiliser la fonction cor.test, qui attend les mêmes arguments :
Pearson's product-moment correlation
data: propre$body_mass_g and propre$flipper_length_mm
t = 32.722, df = 340, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.843041 0.894599
sample estimates:
cor
0.8712018
Nous avons donc la valeur de t (32,72), les degrés de liberté (340) et la valeur de p (<2,2 x 10-16) associés à notre valeur de corrélation, ainsi que l’intervalle de confiance à 95 %, qui va de 0,84 à 0,89.
Cette corrélation est donc clairement significativement différente de zéro. Notre intervalle de confiance est particulièrement précis!
17.4 Exercice : Corrélation de Pearson
Sachant que les insectes sont des ectothermes, nous allons voir avec cet exercice si la fréquence de chant (le nombre de stridulations par seconde) d’une espèce de grillons, la némobie striée, est reliée à la température du sol.
Voici les données que vous avez recueillies pour répondre à cette question :
Stridulations/seconde
Température (º F)
20.0
88.6
16.0
71.6
19.8
93.3
18.4
84.3
17.1
80.6
15.5
75.2
14.7
69.7
15.7
71.6
15.4
69.4
16.3
83.3
15.0
79.6
17.2
82.6
16.0
80.6
17.0
83.5
14.4
76.3
Testez l’association entre ces deux variables à l’aide de la corrélation de Pearson.
{kind=link}