15.1 Différentes façons d’organiser les mêmes données
Les tests statistiques présentés dans les chapitres précédents (le test de F et la famille des tests de T) étaient tous structurés de la même manière, soit que les deux échantillons à comparer étaient soit dans deux tableaux de données différents, ou soit dans deux colonnes différentes du même tableau. Les tests étaient pensés pour comparer deux variables quantitatives.
Lorsque l’on a affaire à plus de deux groupes, cette façon de fonctionner peut devenir lourde à gérer. C’est pourquoi normalement, on discute plutôt des tests de comparaison de 3+ moyennes comme mettant en relation une variable catégorique et une variable quantitative. Il s’agit en fait des mêmes données, mais présentées différemment.
Par exemple, au Chapitre 13, notre jeu de données concernant la question sur le poids des oiseaux des milieux urbains et naturels aurait pu être présentée en deux tableaux comme ceci :
Oiseaux en milieu naturel
date
poids_g
2020-09-09
12,5
2020-09-09
13,4
2020-09-10
12,1
…
…
Oiseaux en milieu urbain
date
poids_g
2020-08-01
10,3
2020-08-03
12,6
2020-08-03
9,5
…
…
Par contre, les mêmes observations auraient aussi pu être organisées comme ceci :
milieu
date
poids_g
Naturel
2020-09-09
12,5
Naturel
2020-09-09
13,4
Naturel
2020-09-10
12,1
Urbain
2020-08-01
10,3
Urbain
2020-08-03
12,6
Urbain
2020-08-03
9,5
…
…
…
Prenez quelques minutes pour bien comprendre comment on est passé d’un format à l’autre. Il est crucial que cette étape soit claire dans votre tête avant de passer à la suite de ce chapitre.
Ce changement de format de données change aussi la question associée. Plutôt que de se demander si les milieux urbains et naturels sont différents, on se demande maintenant comment le type de milieu influence le poids des oiseaux. Plutôt que de comparer deux variables quantitatives (poidsnaturel et poidsurbain), on met en relation une variable quantitative (poids) et une variable catégorique (milieu).
C’est dans ce dernier format que devront être organisées vos données pour faire bien fonctionner les tests du présent chapitre dans le logiciel R. Vous avez évidemment le droit de réfléchir à votre problème comme la comparaison de 3+ variables quantitatives, mais pour le logiciel, vous devrez traduire votre pensée en mettant en relation une variable catégorique et une quantitative.
Ce changement d’organisation des données entraîne aussi une nouvelle terminologie. Maintenant que nous pensons nos données en termes de cause et d’effet, nous parlerons fréquemment de variable expliquée et de variable explicative. Dans nos modèles statistiques, la variable expliquée est toujours celle que nous cherchons à comprendre pourquoi elle varie, alors que la variable explicative pourrait fournir une explication pour cette variation. En termes de cause-effet, on s’attend à ce que la variable explicative soit la cause. Dans l’analyse de variance enseignée dans le présent chapitre, la variable expliquée est la variable quantitative et la variable explicative est la variable catégorique.
Vous verrez aussi parfois les appellations de variables dépendante (i.e. expliquée) et indépendante (i.e. explicative). Les mathématiciens privilégient souvent ces appellations, mais elles sont un peu contre-intuitives pour les praticiens. Je n’utiliserai donc pas ces termes dans ce livre.
15.2 Analyser la variance
Le test statistique que nous verrons dans ce chapitre se nomme l’analyse de variance, et on le désigne habituellement sous son acronyme anglais d’ANOVA (ANalysis Of VAriance). Son but est d’aller découper la variance d’une variable quantitative entre deux parties : une que l’on peut attribuer à la variable explicative, et une qui est la variation normale entre les individus (i.e. que l’on ne peut pas expliquer).
Si on reprend notre exemple des différences de poids des oiseaux entre les types de milieux, aucun de nos oiseaux ne pèsera exactement la même chose que la moyenne. Ils seront chacun soit au-dessus ou soit en-dessous. Au Chapitre 5, nous avons donné un nom à cette variation autour de la moyenne : la variance.
Cette variance peut être due à plusieurs choses : différences génétiques entre les individus, âge différent, sexe différent, une partie de hasard, mais aussi une partie due au fait qu’ils étaient dans des milieux différents.
L’ANOVA permet d’aller évaluer la partie de la variation que l’on peut attribuer à notre variable catégorique (le milieu). Elle évalue ensuite si cette partie est grande par rapport à la variation normale entre les individus (celle dûe aux facteurs que nous n’avons pas modélisés comme l’âge, le sexe, etc.). Cette variation normale peut être nommée de beaucoup de façons différentes, entre autres vous verrez le terme variation intra-groupe, bruit et aussi résidus pour la désigner.
L’ANOVA, au final, est un simple test de F (voir Chapitre 14), qui compare la variation inter-groupe (celle due à notre variable catégorique) à la variation intra-groupe (le bruit). Elle compare ensuite la valeur de F obtenue à celle que nous aurions pu obtenir si la variable catégorique n’avait aucun effet.
Maintenant que ces principes sont (je l’espère) un peu plus clairs, nous pouvons définir l’ANOVA de façon plus formelle.
15.3 L’ANOVA à un facteur
L’ANOVA à un facteur s’utilise pour comparer deux moyennes ou plus entre elles. Comme expliqué précédemment, elle peut être aussi vue comme un test de la relation entre une variable catégorique et une variable quantitative. Pour illustrer ce test, nous utiliserons à nouveau notre exemple du poids des oiseaux dans différents milieux. Cette fois, nous avons capturé 20 oiseaux en milieu forestier, 20 oiseaux en milieu urbain et 20 oiseaux en milieu agricole. Nous désirons savoir s’il existe un lien entre le poids des oiseaux et le milieu dans lequel ils vivent.
Étape 1 : Définir les hypothèses
L’hypothèse nulle pour ce test statistique est que les moyennes des différents groupes sont toutes égales entre elles. L’hypothèse alternative est qu’au moins une des moyennes est différente des autres.
\[
H_0 : \mu_{urbain} = \mu_{agricole}= \mu_{forestier}
\]\[
H_1 : \text{Au moins un des milieux}
\]\[
\text{est différent des autres}
\]
Étape 2 : Explorer visuellement les données
L’ANOVA à un facteur comporte trois assomptions principales. La première, comme pour tous les autres tests, est que les observations sont indépendantes les unes des autres. Si jamais elles ne le sont pas, il faut utiliser un autre type d’ANOVA, plus approprié (imbriquée, en blocs aléatoires, etc., voir Chapitre 16).
La deuxième assomption est que la variance entre les groupes est égale. Bien que l’on ait longtemps recommandé de tester cette assomption formellement à l’aide d’un test de F ou de Bartlett, la recommandation moderne est de simplement valider visuellement. L’utilisation d’un test préliminaire modifie souvent l’erreur de type I, et aussi s’avère trop stricte dans bien des cas, entre autres quand les groupes sont de tailles égales.
La troisième assomption est celle de normalité de la variable quantitative. Ici par contre, il faut être bien attentif lorsque l’on vérifie cette assomption. Il est normal que, avant de débuter l’analyse, la variable quantitative présente plusieurs modes plutôt qu’un seul. L’assomption officielle du test est que chaque groupe suit une distribution normale.
On peut donc soit vérifier cette assomption groupe par groupe avant de commencer, ou la vérifier après avoir calculé le test, en vérifiant ce que l’on appelle la normalité des résidus. Autrement dit, une fois les différences de moyennes éliminées entre les groupes, ce qui reste devrait être distribué normalement. Je vous enseignerai cette deuxième façon de faire, puisqu’elle sera aussi applicable dans les chapitres suivants pour la régression linéaire, l’ANCOVA et les modèles plus complexes que nous verrons dans la section sur le modèle linéaire.
Il faudra donc penser, après avoir calculé le test, d’aller vérifier les résidus avant de pouvoir procéder à l’interprétation du test. Nous dérogerons donc légèrement des 6 étapes classiques montrées jusqu’à présent pour appliquer un test.
Enfin, comme pour les tests de T, en présence de grands échantillons, le théorème central limite peut venir à votre rescousse en conférant une certaine robustesse aux écarts face à la normalité.
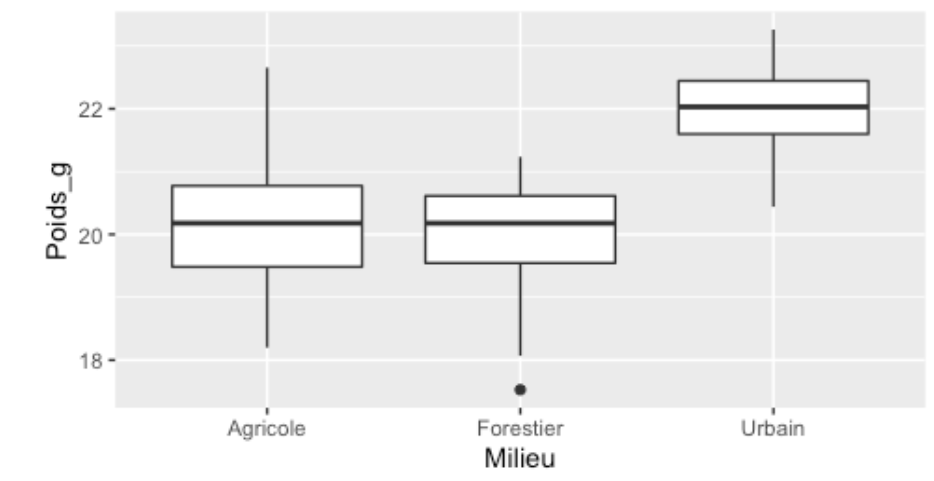
Une fois toutes ces choses vérifiées, il nous reste une chose à faire, qui est d’explorer nos données pour voir si on devrait s’attendre à trouver des différences entre les groupes ou non. La façon classique de le faire est à l’aide d’un diagramme à moustaches, comme ceci :
Après avoir observé ce graphique, on peut s’attendre à ce que l’assomption d’égalité des variances ait été respectée et qu’il existe une différence de moyenne de poids entre certains groupes, les oiseaux urbains paraissant plus lourds que les oiseaux des autres milieux.
Vous lirez aussi parfois que l’ANOVA nécessite que le nombre d’observations (le n) soit égal entre les groupes. Des tailles d’échantillons différentes n’influenceront pas le calcul ou les résultats de l’ANOVA à un facteur comme nous voyons ici. Elles rendront cependant l’analyse moins robuste aux différences de variance. On recommande néanmoins d’avoir au moins trois observations pour chacun des groupes.
Étape 3 : Calculer la statistique de test
Contrairement aux tests présentés dans les chapitres précédents, le calcul de l’ANOVA n’est pas aussi direct et nécessite quelques étapes préliminaires avant d’en arriver à la statistique de test. Avant d’en arriver à notre ratio de variance, il faudra commencer par définir le calcul de la variance inter-groupe et de la variance intra-groupe. Pour cela, rappelons-nous d’abord la définition de la variance, telle que vue au Chapitre 5 : \[
\sigma^2 = \sum_{i=1}^n \frac{ (x_i-\bar{x})^2 }{n-1}
\] Notez que cette formule pourrait être transformée comme ceci et l’on obtiendrait exactement le même résultat :
Dans cette deuxième formulation, on clarifie que la formule comporte deux parties distinctes, qui ont chacune un nom et une utilité. La partie au numérateur se nomme la somme des carrés. On peut y voir que pour chaque valeur (xi), on calcule le carré de la différence entre cette valeur et la moyenne. Le dénominateur se nomme quant à lui les degrés de liberté.
Il existe des définitions équivalentes pour la variance inter-groupe et la variance intra-groupe. Cependant, puisqu’il ne s’agit pas de variance à proprement parler, on parle plutôt de carrés moyens et on leur attribue généralement leur abréviation anglaise, soit MS pour mean square. Les formules sont les suivantes : \[
MS_{inter-groupe} = SS_{inter-groupe}/(k - 1)
\]\[
MS_{intra-groupe} = SS_{intra-groupe}/(N-k)
\]
Où k est le nombre de niveaux de la variable catégorique (i.e. le nombre de groupes différents) et N le nombre d’observations total.
Dans ces équations, il nous reste donc à définir SSinter-groupe et SSintra-groupe, qui sont des sommes des carrés (SS, Sum of Squares).
La somme des carrés inter-groupes est sans doute la chose la plus abstraite à calculer dans l’ANOVA. On la calcule en remplaçant chaque observation de la variable quantitative par la moyenne de son groupe et en faisant le calcul de la somme des carrés sur ces nouvelles valeurs. Le principe sous-jacent étant que, si les groupes sont très différents les uns des autres, la somme des carrés inter-groupes sera grande. Si les groupes sont très semblables, cette somme des carrés inter-groupes sera très petite.
Enfin, pour calculer la somme des carrés intra-groupes, que l’on peut aussi nommer résidus, il faut faire la différence entre chaque observation et la moyenne de son groupe et mettre ces différences au carré avant de les additionner. Plus les mesures dans un groupe sont différentes les unes des autres, plus cette somme des carrés sera grande. Au contraire, si toutes les observations d’un groupe sont égales, cette somme des carrés sera de zéro.
On peut donc ensuite calculer les carrés moyens, comme mentionné ci-haut, et finalement (!) calculer la statistique de F comme étant le ratio des carrés moyens inter et intra groupe, autrement dit : \[
F = MS_{inter-groupe}/MS_{intra-groupe}
\]
Dans le résultat d’une ANOVA, ces informations sont habituellement rassemblées dans un tableau que l’on présente avec les résultats :
Source
Degrés de liberté
Somme des carrés
Carrés moyens
Valeur de F
Valeur de p
Inter-groupe
2
48,88
24,44
25,45
0,0000000013
Intra-groupe (résidus)
57
54,75
0,96
Comme d’habitude, vous n’aurez pas à faire tout ce calcul en détail. R vous fournira automatiquement le tableau de l’ANOVA comme ci-haut. Cependant, il est important de comprendre que la valeur de F augmentera si les différences entre les moyennes sont grandes, et diminuera si les observations dans un groupe sont très différentes les unes des autres.
Étape 4 : Obtenir la valeur de p
Une fois la valeur de F calculée, nous pouvons aller voir, comme à l’habitude, dans la distribution F quelle serait la probabilité d’avoir trouvé un ratio aussi important si l’hypothèse nulle d’aucune différence entre les groupes était vraie.
Si l’on se rappelle bien, la distribution de F nécessite deux degrés de liberté différents, ceux qui numérateur et ceux du dénominateur. Ici, ils doivent être respectivement de k - 1 et de N - k. Pour notre exemple, notre valeur de F est de 25,45 et nos degrés de liberté sont de 2 et 57, ce qui nous donne une valeur de p de 0,0000000013
Étape 5 : Rejeter ou non l’hypothèse nulle
Comme observer un tel ratio de F serait extrêmement rare si notre hypothèse nulle était vraie, nous pouvons affirmer que nous avons trouvé une différence significative et rejeter l’hypothèse nulle.
Étape 6 : Citer la magnitude de l’effet et son intervalle de confiance
Comme le ratio de F, dans ce contexte, comporte peu d’intérêt biologique, son intervalle de confiance est rarement rapporté.
Nous pourrions donc écrire ce résultat comme ceci : «Le type milieu de vie influençait de façon significative le poids des oiseaux observés (F2,57=25,45, p = 0,0000000013) »
Néanmoins, une question reste en suspens à ce point. Nous avons pu rejeter l’hypothèse nulle que toutes les moyennes étaient égales. Nous savons que le milieu a un effet sur le poids des oiseaux. Cependant, nous ne savons pas à ce point quels milieux sont significativement différents les uns des autres. Nous verrons plus loin dans ce chapitre comment répondre à cette deuxième question.
15.4 Labo : L’ANOVA à un facteur
Pour ce laboratoire, nous irons vers une question un peu plus du côté de la biologie évolutive. Nous nous demanderons si la taille des ailes est différente entre les espèces de manchots ou si ce n’est pas un caractère distinctif.
Nous préparons d’abord les librairies de code dont nous aurons besoin, puis nous préparerons le tableau de données approprié pour notre test. Comme nous savons que pour certaines observations nous ne connaissons pas la longueur des ailes, il faut prendre le soin d’éliminer ces lignes avant d’effectuer notre analyse :
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
Par la suite, nous pouvons explorer visuellement nos données pour voir si (1) si les variances sont relativement semblables et (2) si il existe une différence de moyenne entre les groupes.
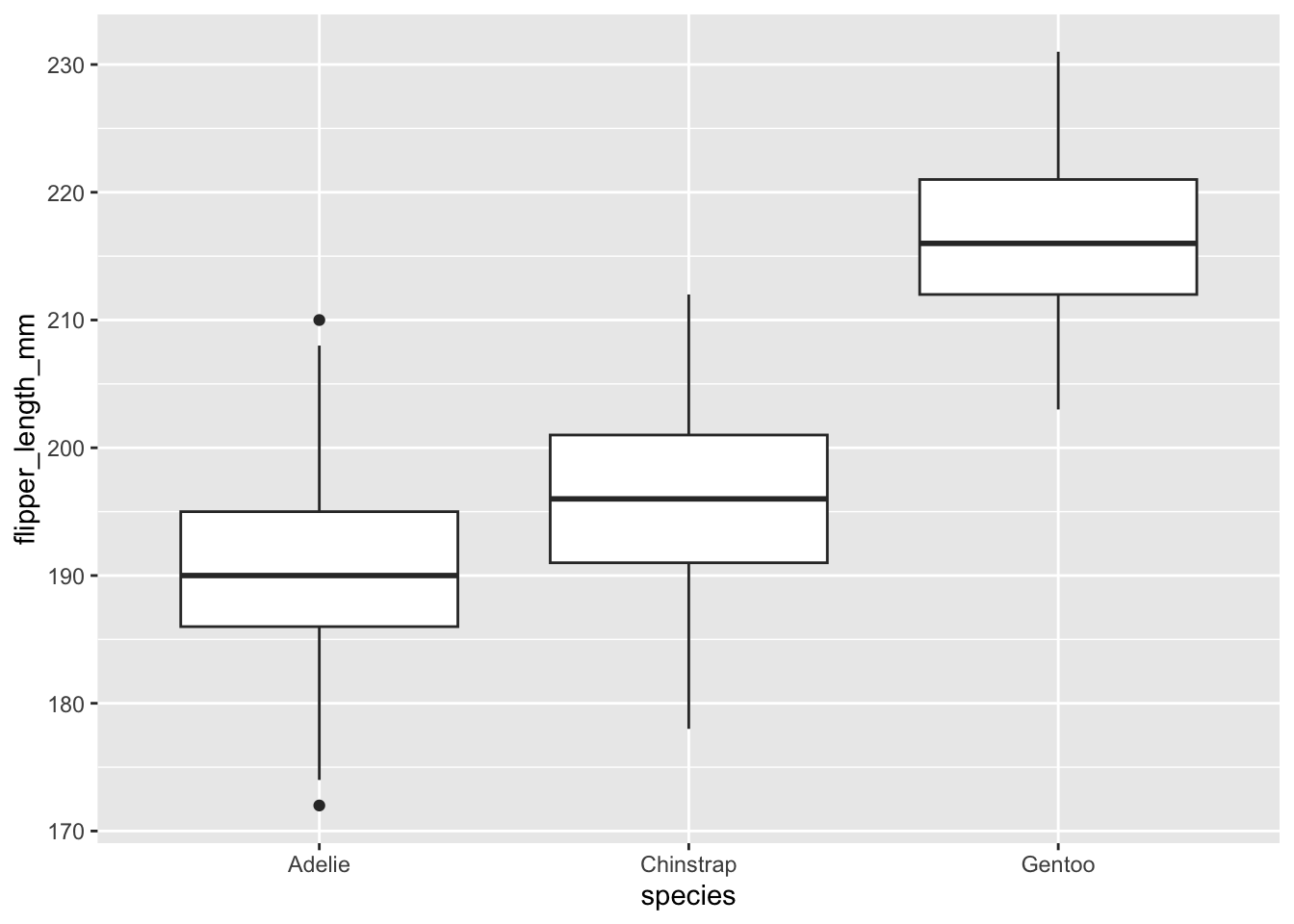
pour_anova |>ggplot(aes(x = species, y = flipper_length_mm)) +geom_boxplot()
À première vue les variances sont relativement homogènes (taille des boîtes très semblable), mais les moyennes diffèrent beaucoup, en particulier pour les Gentoo qui semblent avoir des ailes vraiment plus grandes.
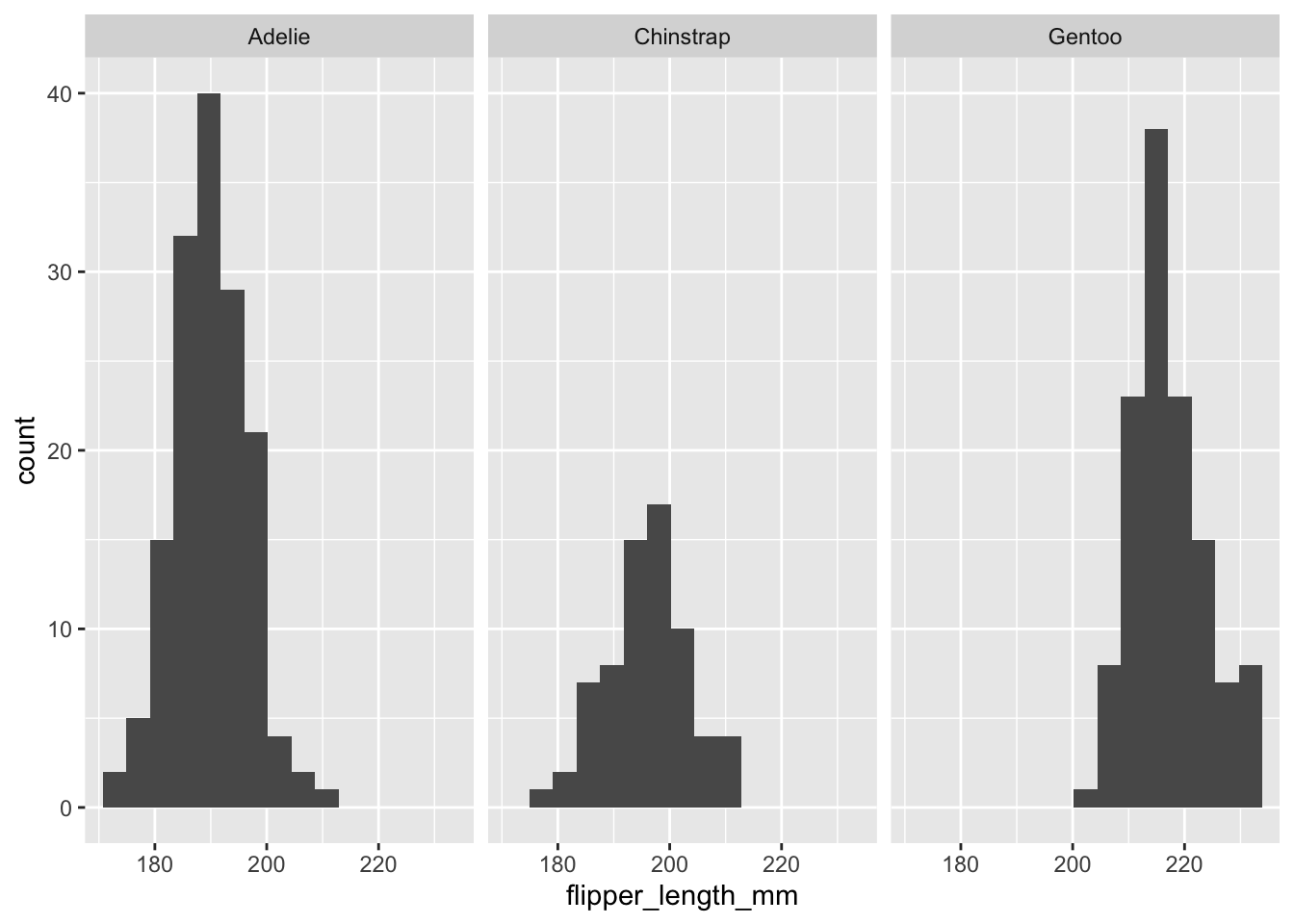
On peut ensuite jetter un coup d’oeil aux distributions des tailles d’ailes dans chacune des espèces.
À première vue, les 3 groupes sont distribués normalement. Remarquez que cette étape est uniquement exploratoire. La vérification formelle ce fera après avoir calculé le test comme tel.
Étapes 3 et 4 :
La fonction pour calculer une ANOVA dans R se nomme aov (pour Analysis Of Variance). Par contre, sa syntaxe est un peu différente des tests que nous avons vus jusqu’à présent. Plutôt que de donner les valeurs de chacun des groupes dans des arguments séparés, il faut utiliser la notation formule de R. Dans cette notation, il faut indiquer d’abord la variable quantitative que nous voulons analyser, puis le symbole ~ (tilde) et ensuite la variable catégorique. Ensuite, il faut utiliser l’argument data pour nommer dans quel tableau de données aller chercher ces variables. Pour notre exemple, la commande serait donc :
m <-aov(flipper_length_mm ~ species, data = pour_anova)
Notez que pour faciliter notre travail dans les étapes subséquentes, on attrape la sortie de l’ANOVA dans un objet nommé m plutôt que de l’afficher directement à l’écran. Remarquez aussi que (et c’est vrai pour toutes les formules dans R) la variable expliquée se trouve toujours à gauche du ~ et la (ou les) variable explicative se trouve à droite. Dans votre tête, vous pouvez lire le “~” comme “en fonction de” ou “expliqué par”.
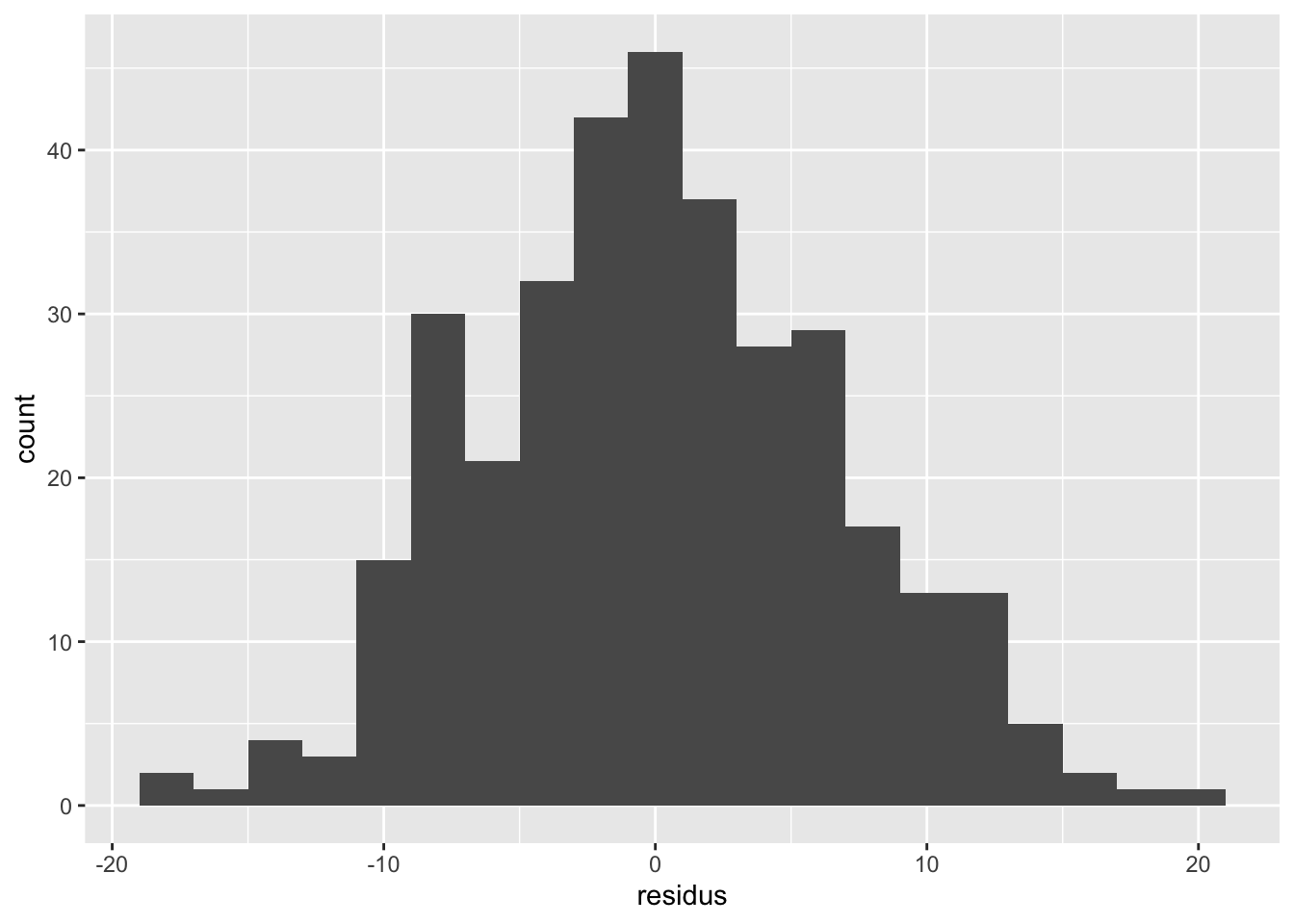
La première chose à faire à ce point est de valider la distribution des résidus pour s’assurer qu’ils sont normaux. Pour se faire, le plus simple est d’ajouter une colonne résidus à notre tableau de données à l’aide de la fonction resid et ensuite de l’utiliser pour tracer un histogramme :
Difficile de faire mieux pour la normalité. Remarquez cependant qu’il est pas crucial que les données soient parfaitement normales. Comme discuté ci-haut, L’ANOVA est relativement robuste aux écarts de normalité, mais elle est relativement sensible aux différences de variance entre les groupes.
Si on appelle la fonction summary sur cet objet m, obtient le tableau d’ANOVA tel que présenté dans l’exemple précédent :
summary(m)
Df Sum Sq Mean Sq F value Pr(>F)
species 2 52473 26237 594.8 <2e-16 ***
Residuals 339 14953 44
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Tous les éléments mentionnés précédemment s’y trouvent, mais en anglais. L’abréviation Df désigne les degrés de liberté (Degrees of Freedom), Sum Sq désigne la somme des carrés, Mean Sq les carrés moyens, F value la valeur de F est Pr la valeur de p. La première ligne (species) désigne la variance inter-groupe et le terme Residuals désigne la variance intra-groupe.
Notez qu’à côté de la valeur de p, si R nous présente une ou plusieurs étoiles (*), c’est une indication supplémentaire que la différence est significative, comme l’indiquent les codes à la fin du résumé.
Étapes 5 et 6 :
On pourrait donc à ce point écrire notre résultat comme ceci : «Les espèces de manchots de l’archipel Palmer avaient des ailes de taille significativement différentes (F2,339=594,8, p < 2 x 10-16).»
15.5 Contenu optionnel : ANOVA à un facteur vs. test de T?
À ce point, une question vous vient peut-être en tête. Si ma variable catégorique ne contient que deux groupes, est-ce que je peux quand même utiliser une ANOVA ou je dois absolument utiliser un test de T?
La réponse est que, si les variances sont égales entre vos deux groupes, vous pouvez utiliser une méthode ou l’autre et vous arriverez exactement à la même valeur de p. Ceci est tellement vrai qu’il existe une règle pour convertir une valeur de F en valeur de t et vice-versa, qui dit que F = t2.
Par contre, si vos variances sont inégales entre vos groupes, les résultats peuvent différer, puisque bien que l’ANOVA soit robuste à un certain départ de cette condition, elle n’est pas aussi bien adaptée que le test de Welch.
Il existe d’autres petites équivalences de ce genre à découvrir, mais je vais me garder un peu de matériel pour la deuxième partie de ce livre!
15.6 Les tests post-hoc
Comme mentionné plus tôt, l’ANOVA peut nous renseigner globalement sur l’effet de notre variable catégorique, mais elle ne peut pas nous informer de quels groupes sont différents les uns des autres. Si l’on désire obtenir ces informations, il faut effectuer un test post-hoc, c’est-à-dire un test après-coup.
La chose extrêmement importante à retenir est que vous devez toujours effectuer l’ANOVA globale d’abord. Ensuite, si et seulement si l’ANOVA vous montre une différence significative, vous pouvez lancer les tests post-hoc. Il ne faut jamais aller directement avec ces derniers. La raison est fort simple : comme les tests post hoc effectuent beaucoup de comparaisons, ils augmentent potentiellement votre erreur de type I. Par souci de parcimonie, il faut donc se contenter de les utiliser uniquement au moment approprié.
La première façon de déterminer quels groupes sont différents les uns des autres est d’utiliser de multiples tests de T. Pour notre exemple sur les oiseaux, on ferait un test de T entre urbain et forestier, ensuite entre forestier et agricole et finalement entre agricole et urbain. Pour contrer le problème de la multiplication des tests et le gonflement associé de l’erreur de type I, on ajoute généralement à ces tests la correction de Bonferroni. La correction de Bonferroni consiste à modifier notre seuil de signification, pour qu’il revienne globalement au seuil attendu.
Par exemple, si nous avions prévu utiliser le seuil classique de α = 0,05 et que nous voulions faire 3 comparaisons multiples, notre nouveau seuil de signification ajusté par la correction serait de 0,05/3 = 0,0167. Donc pour chacun de nos tests de T, la valeur de p devrait être < 0,0167 pour être considérée comme significative.
Bien que mathématiquement correcte, la correction de Bonferroni est souvent critiquée parce que le nouveau seuil de signification est particulièrement difficile à atteindre, ce qui réduit grandement la puissance de notre procédure statistique.
C’est pourquoi on utilise en général le test de Tukey HSD pour effectuer ces comparaisons. Nous ne verrons pas les détails techniques de ce test. L’important est de comprendre que le test calcule une distance seuil (HSD; Honest Significant Difference) puis compare la distance entre chaque paire à ce seuil. Il corrige ainsi pour l’augmentation de l’erreur de type I, au même titre que la correction de Bonferroni, mais diminue beaucoup moins la puissance de notre procédure.
15.7 Labo : Le test post-hoc de Tukey HSD
Pour appliquer un test de Tukey HSD dans R, il faut avoir préalablement effectué une ANOVA et avoir conservé le résultat dans un objet.
Comme discuté plus haut, il est primordial d’appliquer les tests post-hoc uniquement si l’ANOVA globale indiquait une différence significative entre les groupes.
TukeyHSD(m)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = flipper_length_mm ~ species, data = pour_anova)
$species
diff lwr upr p adj
Chinstrap-Adelie 5.869887 3.586583 8.153191 0
Gentoo-Adelie 27.233349 25.334376 29.132323 0
Gentoo-Chinstrap 21.363462 19.000841 23.726084 0
R nous informe d’abord sur le test appliqué et nous rappelle les détails du modèle d’ANOVA que nous avons utilisé. Ensuite, il nous fournit un tableau des comparaisons par paires qu’il a effectuées.
Ce tableau contient trois lignes, qui nous montrent les différences entre Gentoo et Adélie, ensuite Gentoo et Adélie, et enfin entre Gentoo et Chinstrap. Pour chacune des paires, le test de Tukey nous fournit la différence moyenne entre les groupes (diff) ainsi que les bornes de l’intervalle de confiance à 95 % de cette différence (lwr et upr) et finalement la valeur de p ajustée de cette différence.
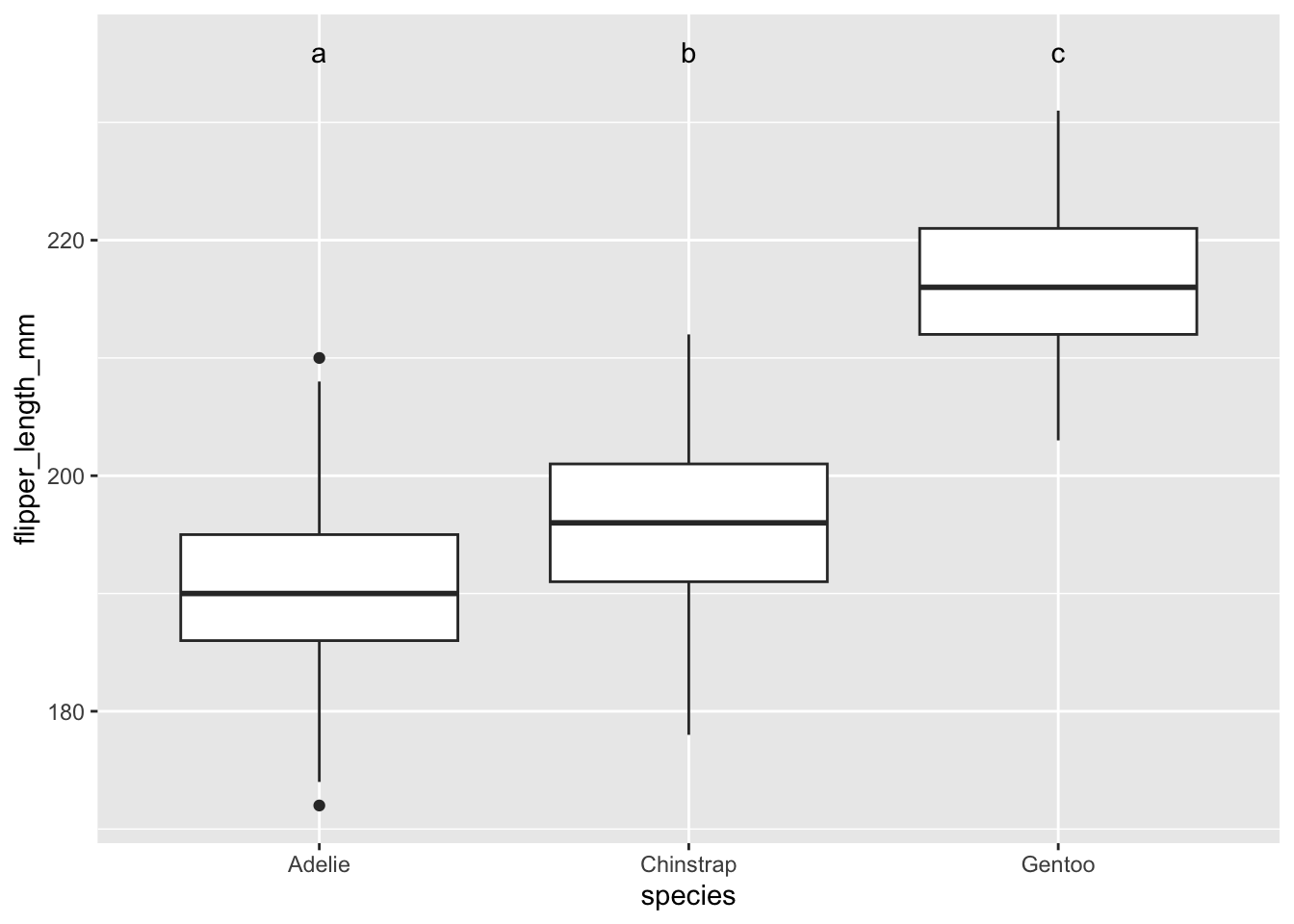
On voit ici que la taille des ailes est significativement différente dans toutes les paires de combinaison. La valeur de p de zéro est une approximation. R veut vraiment nous dire que la valeur est si petite que lui n’arrive pas à la distinguer de 0.
On voit parfois les résultats d’un test de Tukey HSD résumés ainsi : Gentoo > Chinstrap > Adélie. On place les groupes en ordre de grandeur, mais on indique le symbole > uniquement pour séparer les groupes qui sont significativement différents. On relie par un trait souligné les termes qui ne sont pas différents les uns des autres.
Visuellement, cette information peut être représentée à l’aide d’une lettre pour chacun des groupe significativement différent d’un autre groupe, comme ceci :
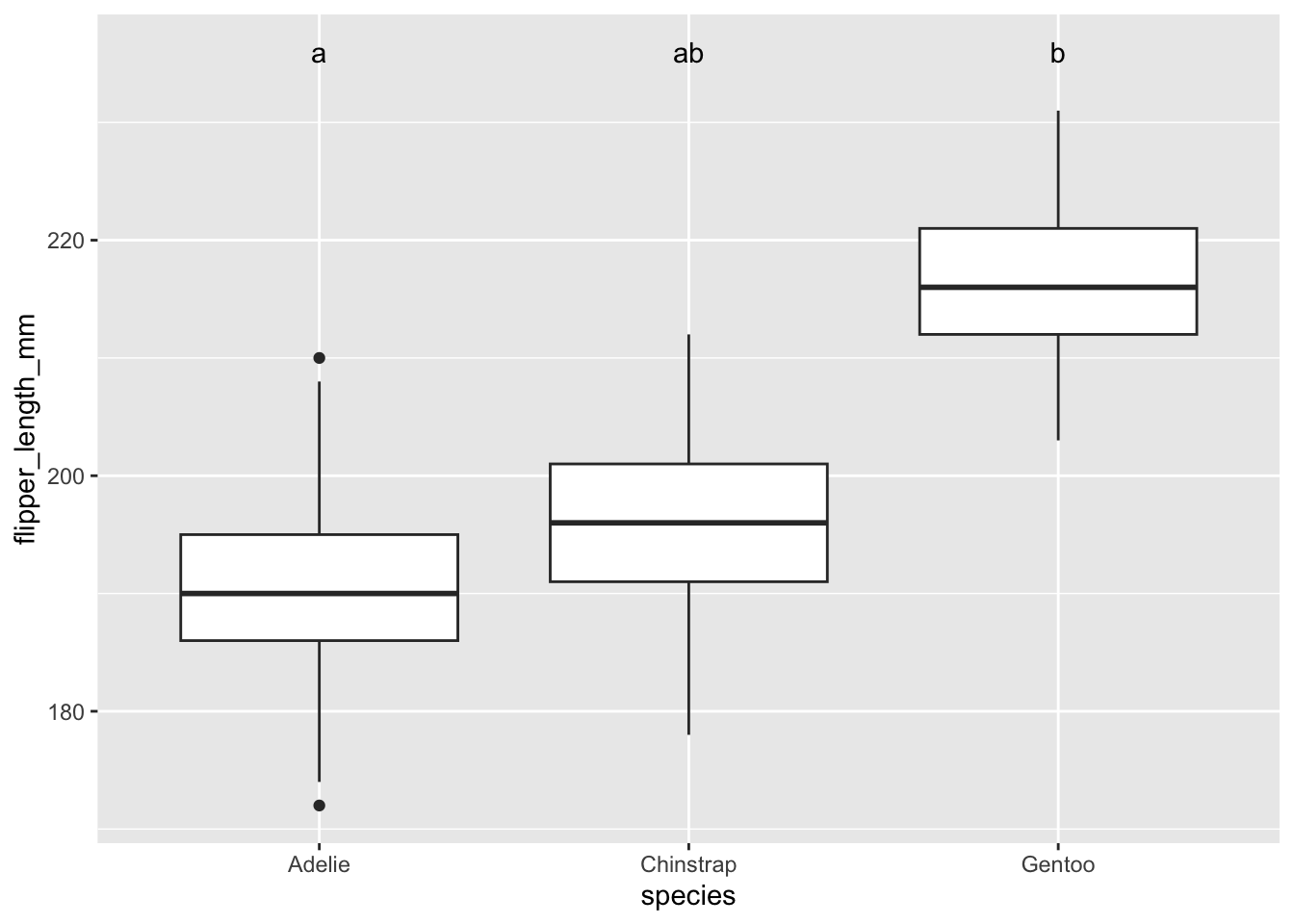
Si le manchot Adélie avait été différent du Gentoo, mais que ni le Gentoo ni le Adélie avait été différent du manchot Chinstrap, les lettres auraient été comme ceci :
Dans ce genre de graphique, il peut donc arriver qu’un même groupe possède plusieurs lettres, c’est tout à fait normal.
15.8 Exercice : L’ANOVA et le test de Tukey HSD
À partir de la base de données ChickWeight inclue avec R, filtrez les données pour ne conserver que le poids des poussins au dernier jour de l’expérience.
À partir de ces données, répondez à la question suivante : Existe-t-il une différence de poids des poussins entre les différentes diètes au terme de l’expérience?
Si vous trouvez une différence significative, déterminez quelle(s) diète(s) diffère des autres.