Pour ce chapitre, nous nous attaquerons à un type de données précis. Celui où notre variable en Y (la variable à expliquer) ne peut avoir que deux valeurs : 0 et 1. Ce genre de données binaires peut survenir dans de nombreuses situations en écologie. Vous pourriez par exemple suivre une population de poissons, que vous marquez en début de saison, puis tentez de repêcher en fin de saison pour savoir s’ils ont survécu, et ensuite analyser les facteurs favorisant leur survie. Chacune des observations de votre tableau de données sera donc un individu, avec une variable Survie (0 ou 1) que vous voudriez expliquer par une série d’autres facteurs (Age, Sexe, etc.). Ce genre de données surviendra aussi, par exemple, si vous tentez de déterminer quels sont les facteurs qui favorisent la présence d’une espèce. Vous codez alors 0 ou 1 sa présence et notez pour chaque site les facteurs que vous croyez importants.
33.2 Problématique
Au moment d’entrer ces données dans un modèle de régression multiple, on remarquera rapidement une série de problèmes.
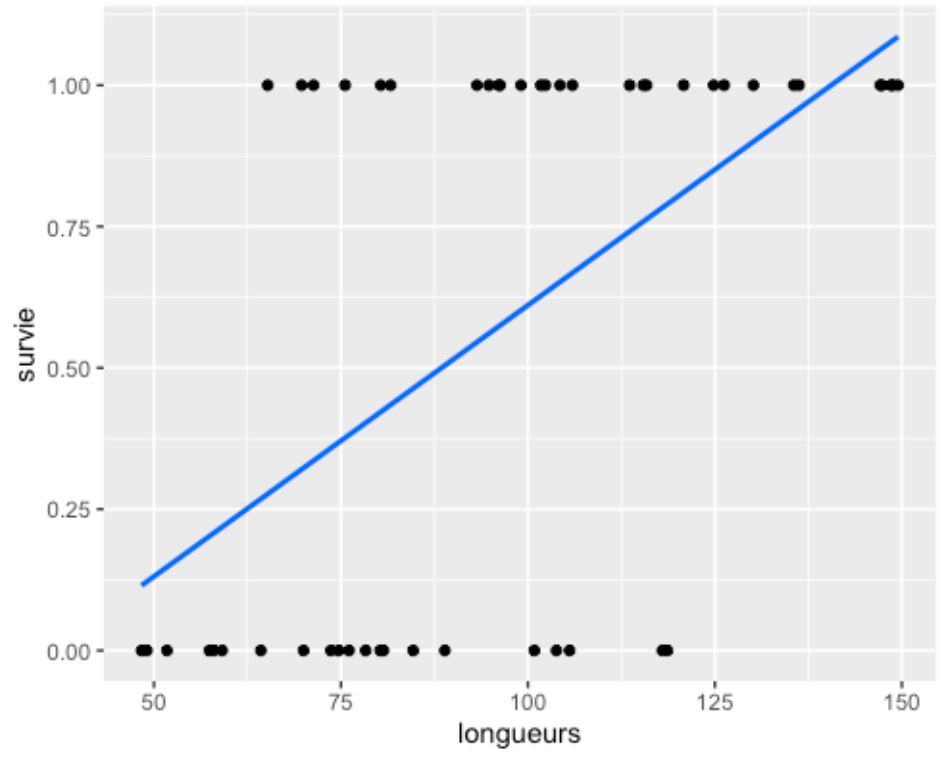
Tout d’abord, avec des données binaires, il n’y a aucun moyen de transformer les données pour les forcer dans une distribution normale. C’est tout simplement impossible. Ensuite, si on décide d’outrepasser cette restriction, on se butte rapidement à d’autres problèmes. Si on voulait par exemple modéliser la survie en fonction de la taille d’un individu, la régression à ajuster pourrait visuellement ressembler à ceci :
On a PLUSIEURS problèmes! Tout d’abord, remarquez que notre modèle nous informe que, pour un poisson de 87 cm, on obtient 0,5 survie. Or, notre poisson a survécu ou pas, il ne peut pas avoir survécu à moitié.
Donc, premier constat, pour que notre modèle ait du sens, il devra modéliser non pas la survie directement, mais la probabilité de survie. Dans ce contexte, cette probabilité est habituellement notée avec le symbole π (pi).
Par contre, cela ne règle pas tout. Pour un poisson de 150 cm, notre modèle prédit environ 1,15. Or, par définition, une probabilité devrait toujours se situer entre 0 et 1.
33.3 Principe d’un GLM pour la régression logistique.
Les GLM (Generalized Linear Models) nous permettent de régler tous ces problèmes de façon extrêmement élégante et fonctionnelle.
Nous avons vu au chapitre précédent sur les modèles mixtes que la définition précise, mathématique, d’un modèle de régression comprend une partie systématique
\[
y_i=b_0+b_1x_i+\epsilon_i
\]
et une partie qui définit la distribution des résidus
\[
\epsilon_i\sim N(0,\sigma^2_\epsilon)
\]
Un GLM, quant à lui, comprendra trois parties. La partie systématique, la distribution des résidus mais aussi une fonction de lien.
La première chose à faire pour permettre l’analyse de données binaires sera de spécifier la bonne distribution d’erreurs, correspondant à nos données plutôt que de toujours utiliser la distribution normale.
Dans le cas de la régression logistique (le GLM approprié aux données binaires), les erreurs suivront une distribution binomiale avec un n de 1 et probabilité π. Si on se rappelle des premiers chapitres, la distribution binomiale décrit les situations, comme un lancer de pièce de monnaie, où l’on connaît le nombre d’essais, et où chaque essai peut être un succès ou un échec.
Ainsi, les observations de notre modèle seront des observations 0 ou 1 (présence/absence, mort/survie, etc.), mais nous pourrons jouer avec des probabilités continues dans notre modèle (π).
Ensuite, nous devrons spécifier une fonction pour relier la partie systématique du modèle et la probabilité (π), de façon à contraindre les probabilités entre 0 et 1. Nous devrons choisir ce que l’on nomme dans un GLM la fonction de lien.
Dans un GLM pour données binaires, le lien utilisé est habituellement la transformation logit. Mathématiquement, la transformation logistique se définit comme ceci :
Nous prendrons maintenant quelques minutes pour comprendre pourquoi cette transformation fonctionne bien.
Le problème de nos probabilités est qu’elles sont coincées entre 0 et 1, alors que le modèle de régression, lui, n’est pas borné. C’est pourquoi la fonction logistique transforme d’abord la probabilité en cote (comme à Vegas) :
\[
cote = \frac{\pi}{(1-\pi)}
\]
Une probabilité de 0,75 sera traduite en une cote de 3 (à Vegas, on aurait dit 3:1 ou 3 contre 1). Donc, trois fois plus de chances qu’un événement se réalise que de chances qu’il ne se réalise pas.
Cette opération élimine le problème de la borne supérieure, qui peut maintenant dépasser 1 (voir Table 33.1).
Table 33.1: Comparaison entre les probabilités, les cotes et les log-cotes (transformation logit).
Probabilité
0,9
0,5
0,1
Cote
9
1
0,111
Logit
2,20
0
-2,20
Par contre, les cotes ne peuvent pas être négatives, alors que le modèle de régression, lui, peut facilement nous prédire des valeurs négatives. Les statisticiens ont donc proposé d’utiliser le logarithme naturel de la cote (log-odds) pour contourner le problème. Notre probabilité de 0,75, transformée en cote de 3, deviendrait 1,099 en log-cotes (voir Table 33.1).
Si on met tous ces morceaux ensemble, on peut donc écrire le GLM de la régression logistique comme ceci :
Un peu comme pour les modèles mixtes, les valeurs optimales des paramètres d’un GLM seront trouvées par un algorithme itératif, démarrant d’une solution aléatoire et s’approchant progressivement de la meilleure solution en maximisant la vraisemblance (maximum likelihood).
33.4 Comment interpréter un modèle de régression logistique
Si on ajuste un modèle de régression logistique à nos données de survie, on obtiendra les paramètres suivants :
Autrement dit, la survie augmente selon la longueur du poisson (B1 > 0). Par contre, il est relativement complexe de se représenter l’ampleur de ce nombre puisque ce n’est pas directement la probabilité qui augmente de 0,055 par unité de longueur, mais bien le logit de la probabilité.
À cause de la transformation logit, l’effet d’un changement d’une unité de longueur n’aura pas le même effet selon l’intervalle de longueurs que l’on regarde. Pour constater cette différence, le plus simple est de se créer quelques prédictions. On pourrait par exemple prédire la probabilité de survie pour des poissons de 50 vs. 60 cm et 90 vs 100 cm à l’aide de notre modèle logit(π) = -4,77+0,055*longueur :
Longueur 1
Longueur 2
Logit 1
Logit 2
Prob. 1
Prob. 2
Diff.
50
60
-2,02
-1,47
0,12
0,18
0,06
90
100
0,18
0,73
0,54
0,67
0,13
Ensuite, on peut passer du logit à la probabilité en inversant la transformation :
\[
\pi = \frac{exp(x)}{1+exp(x)}
\]
Donc, autrement dit, une différence de 10 cm aurait un effet deux fois plus grand sur la probabilité de survie si notre poisson mesure 90 cm plutôt que 50 cm.
La façon la plus simple pour se faire une tête sur ce sujet est de visualiser l’ensemble de la courbe de probabilités :
Autrement dit, la probabilité de survie augmente lentement avant 50 cm, elle connaît son maximum d’augmentation autour de 90 cm et ensuite elle ralentit, jusqu’à ne plus vraiment augmenter au-delà de 140 cm.
33.5 Évaluer la qualité des prédictions
La première question qui nous viendra à l’esprit est probablement de savoir : est-ce que notre modèle prédit bien ou non la survie des poissons. Ce qui est complexe pour évaluer cette performance est que notre modèle prédit une probabilité (entre 0 et 1), et que nos données terrain, elles, sont toujours 0 ou 1 (le poisson a survécu ou il n’a pas survécu).
Pour valider la qualité du modèle, une façon simple de contourner ce problème est de choisir un seuil de probabilité, par exemple 0,5 et d’assumer que notre modèle prédit 0 quand π < 0,5 et qu’il prédit 1 quand π >= 0,5. On peut ensuite calculer le nombre de cas pour lequel notre modèle a bien prédit et le nombre cas où il a mal prédit, i.e. sa précision. Dans notre exemple, le modèle fournirait 38 bonnes prédictions sur 50 individus. Il aurait donc une précision de 76%.
Dans les cas où notre jeu de données est relativement équilibré, calculer la précision du modèle sera suffisant. Par contre, dans les cas où une des classes sera plus rare que l’autre, calculer uniquement la précision ne serait pas très informatif.
Imaginez un scénario où 90% des poissons survivent à l’hiver. Un modèle stupide, qui fait simplement prédire que tout le monde survit aurait une précision de 90%, alors qu’en fait, il ne comprend strictement rien au système.
Il existe une série de mesures permettant de définir les qualités prédictives de notre modèle de façon plus nuancée : sensibilité, spécificité, etc, permettant d’aller très en détail sur les qualités d’un modèle (proportions de faux positifs, faux négatifs, etc.). Nous n’irons cependant pas dans ce genre de détail dans un cours censé introduire aux GLM en général.
Il existe heureusement une façon de mieux évaluer notre modèle avec une statistique nommée le D de Tjur, que l’on interprète habituellement comme un coefficient de discrimination. L’idée générale de cette statistique est d’évaluer à quel point notre modèle sépare bien ou non les cas positifs et négatifs. Verbalement, le calcul va comme suit : on calcule la moyenne des probabilités prédites pour les cas positifs, à laquelle on soustrait la moyenne des probabilités prédites pour les cas négatifs. Dans notre exemple sur les poissons, la moyenne de nos prédictions pour nos poissons ayant vraiment survécu était de 0,711 et la moyenne des prédictions pour ceux n’ayant pas survécu était de 0,399. Le D de Tjur serait donc à ce moment de 0,312.
Dans un cas extrême comme notre modèle stupide qui prédit une survie à tout le monde, les deux moyennes seraient 1, et leur soustraction donnerait donc un D de zéro.
Comme le D de Tjur est borné entre 0 et 1 et qu’il nous renseigne sur la qualité d’ajustement d’un modèle, il est d’usage de l’interpréter comme une mesure de R2 appropriée aux régressions logistiques.
33.6 La déviance dans un GLM
Dans les modèles linéaires, nous avons souvent utilisé les termes somme des carrés et somme des carrés des résidus (voir Chapitre 28 pour un rappel). Ces termes nous renseignaient respectivement sur la variabilité de Y et la qualité de l’ajustement de notre modèle. Plus le ratio somme des carrés des résidus sur somme des carrés totale est petit, meilleur est notre modèle.
Dans le cas des GLM, comme nos modèles sont ajustés en maximisant la vraisemblance, on s’intéressera plutôt à la déviance, qui se décline en plusieurs versions.
La première, la déviance nulle (null deviance) décrit la différence de vraisemblance entre un modèle qui ne contient qu’une ordonnée à l’origine et un modèle qui expliquerait parfaitement nos données. Elle servira donc, un peu comme la somme des carrés, à décrire l’ensemble de ce qui pourrait être potentiellement expliqué par notre modèle.
La deuxième déviance que nous utiliserons est la déviance des résidus. Cette dernière mesure la différence de vraisemblance entre le modèle d’intérêt et un modèle parfait qui expliquerait tout.
On pourrait d’ailleurs calculer une mesure de pseudo-R2 nous informant de l’ajustement du modèle en calculant la déviance expliquée, soit :
Ce nombre, comme le R2 pourra varier entre 0 et 1.
33.7 Comment valider un GLM
Comme avec les modèles mixtes, il y a quelques particularités à comprendre à propos des résidus avant de pouvoir bien valider un GLM. La chose la plus importante à comprendre à propos des résidus est que, puisque notre réponse n’est plus linéaire et que la variance n’est plus nécessairement homogène à travers le gradient, un même résidu n’aura pas le même impact dépendamment pour quelle valeur de X on le retrouve.
Il existe toute une série de définitions et de corrections possibles pour contourner le problème (résidus de Pearson, résidus d’Ascombe, etc.), mais les plus utilisés sont les résidus de déviance.
Si on se rappelle plus haut, nous avons mentionné que la déviance résiduelle est l’équivalent dans un GLM de la somme des carrés des résidus. Autrement dit, de combien notre modèle dévie par rapport à la réalité. Une des propriétés intéressantes de la déviance est qu’elle peut être compartimentée. La déviance totale d’un modèle est la somme de la déviance de chacune des observations.
On peut donc définir le résidus de déviance de chaque observation comme :
\[
\sigma^D_i = signe(y_i-\mu_i) \sqrt{(d_i)}
\]
Autrement dit, le résidu de déviance d’une observation correspond à la racine carrée de la déviance de cette observation, à laquelle on colle le signe de la différence entre notre observation et la prédiction. Comme toujours, il ne faut pas s’enfarger dans les détails mathématiques. L’important est de comprendre que dans un GLM, on utilise les résidus de déviance, mais qu’ils s’interprètent comme des résidus ordinaires : un résidu négatif = sur-estimation, résidus positif = sous-estimation. Plus le résidu de déviance est grand (en absolu), moins bon est notre modèle pour cette observation.
À partir de ce moment, on peut effectuer toutes nos validations habituelles concernant l’absence de patrons dans les résidus de notre modèle, mais en effectuant nos vérifications à l’aide des résidus de déviance plutôt que des résidus ordinaires. Même chose pour les distances de Cook concernant l’influence de chacune des observations.
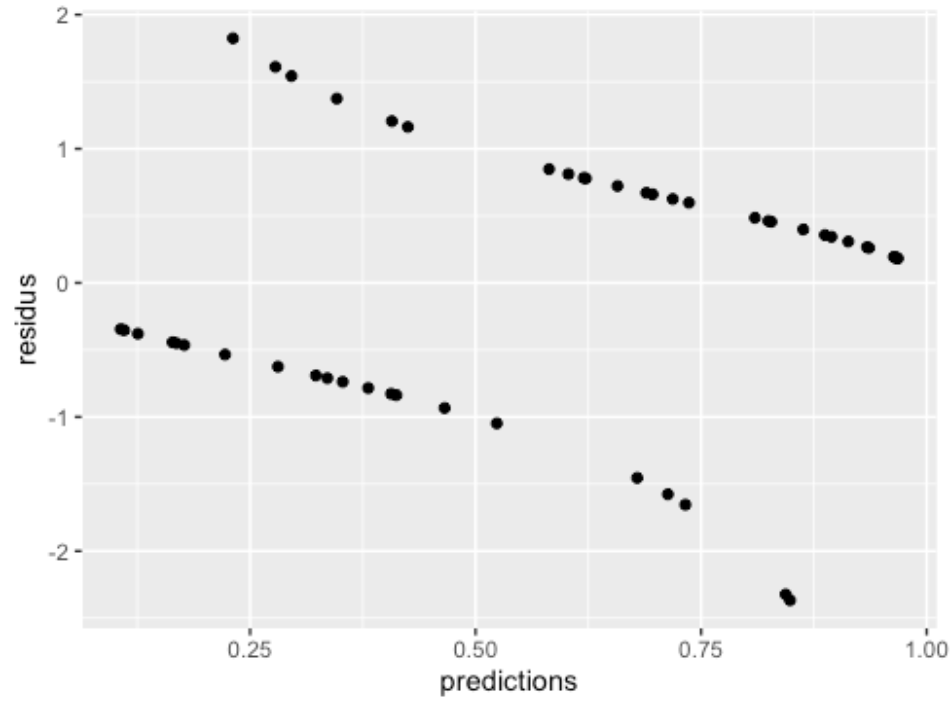
L’interprétation des graphiques est cependant beaucoup plus difficile. Voici par exemple le graphique des résidus de déviance de notre modèle prédisant la survie en fonction de la longueur du poisson :
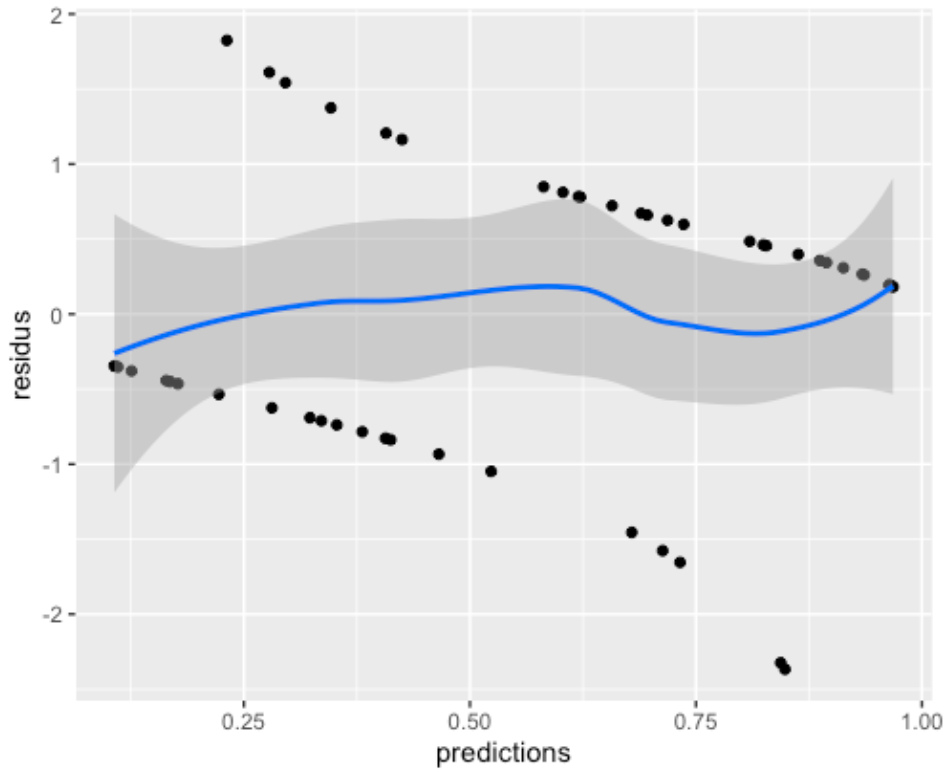
Comme nos observations ne contiennent que deux valeurs, les résidus sont inévitablement organisés en deux lignes. Ce n’est pas un problème en soi. Par contre, notre œil n’est pas particulièrement bon pour voir si les résidus ont tendance à être plus importants à un endroit ou à un autre du graphique. C’est pourquoi il est souvent pratique de passer une courbe de lissage dans le nuage de points pour nous aider à se faire une tête :
Avec la courbe, il est plus évident que les résidus sont relativement équivalents sur l’ensemble du spectre. Que notre modèle ne s’éloigne pas de zéro plus à un endroit qu’à un autre.
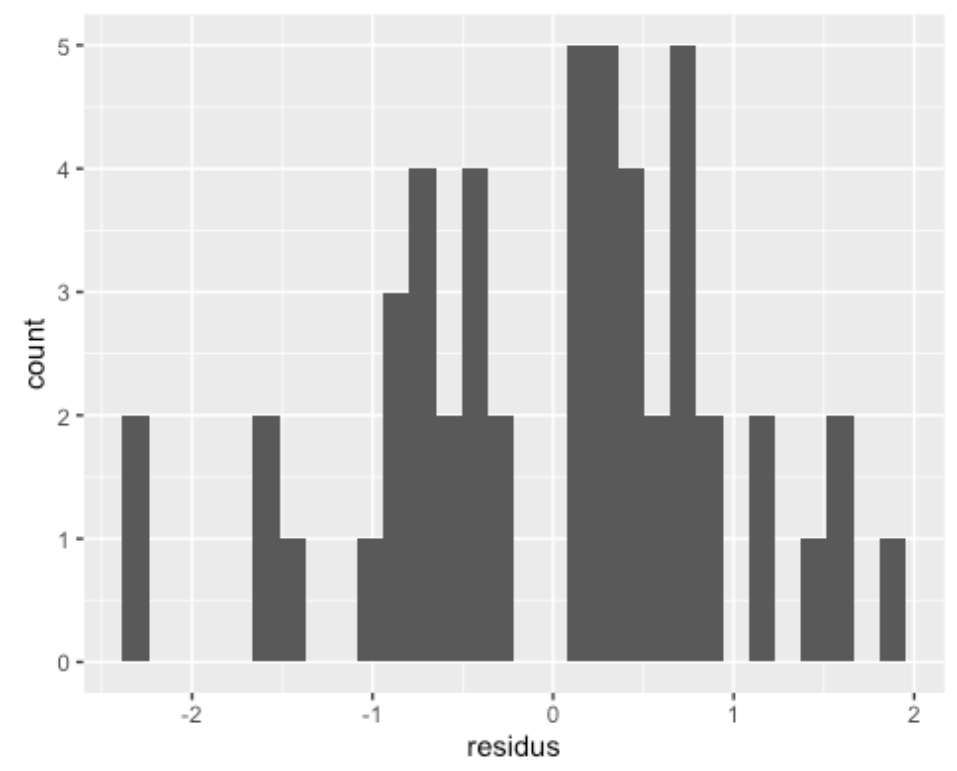
On peut aussi jeter un coup d’oeil à la distribution des résidus de déviance pour voir si elle forme une distribution normale :
Cependant, il est important de comprendre que les résidus de déviance vont habituellement tendre vers la normalité, mais il est difficile de prédire si pour un jeu de données en particulier elles vont réussir à l’atteindre. Ce n’est pas critique que la distribution de vos résidus ne semble pas normale, particulièrement si votre taille d’échantillon est relativement petite.
33.8 Labo : Survivre au naufrage du Titanic
Pour ce laboratoire, nous allons faire changement et, plutôt que nos manchots, nous utiliserons un jeu de données classique pour ce genre de modèle : la survie des passagers du Titanic, avec un tableau de données provenant de la librairie car.
Nous aurons besoin pour travailler des librairies suivantes :
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.2.1
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(car)
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
The following object is masked from 'package:purrr':
some
library(MuMIn)library(visreg)
Le tableau de données TitanicSurvival contient 4 variables :
survived : “yes” / ”no” si le passager a survécu ou non
sex : “female” / “male”
age
passengerClass : “1st”, “2nd”, “3rd”, la première classe étant la plus luxueuse
Par contre, le tableau de données contient beaucoup de valeurs manquantes. De plus, pour passer à la fonction glm, nous aurons besoin que notre variable expliquée (survived) soit convertie en 0/1 plutôt que “yes”/”no”, donc :
Par la suite, comme avec n’importe quel modèle, la première chose est de bien explorer nos données.
Tout d’abord, allons voir globalement quel pourcentage des gens ont survécu au naufrage :
donnees_glm |>summarize(mean(survived))
mean(survived)
1 0.4082218
Donc, 41% des passagers ont survécu et 59% n’ont pas survécu. Un modèle idiot qui prédit que tous les passagers meurent aura raison 59% du temps. Il faudra garder ce fait en tête pour la suite.
Ensuite, allons explorer nos trois variables explicatives. D’abord les chances de survie en fonction de l’âge :
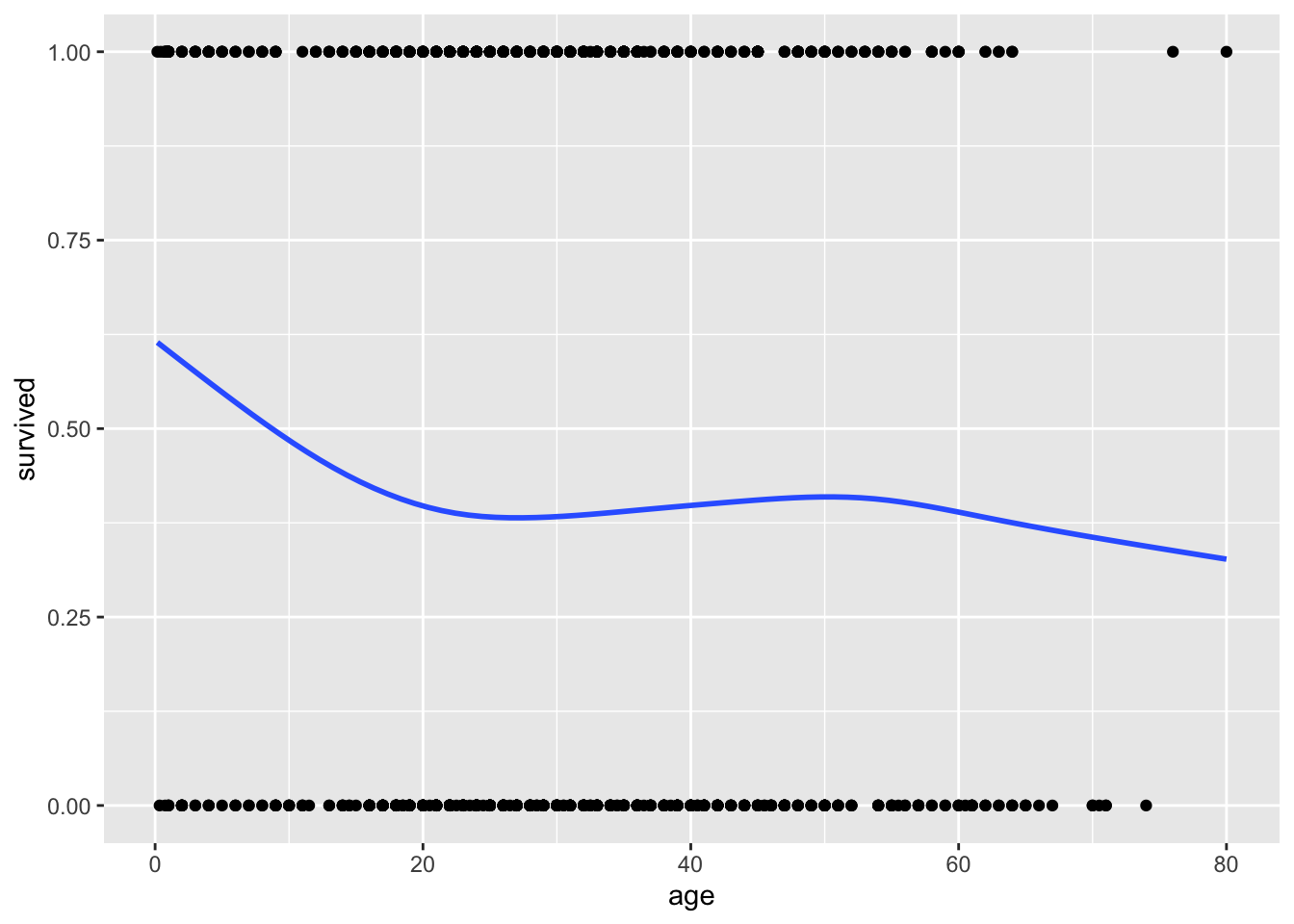
donnees_glm |>ggplot(aes(x = age, y = survived)) +geom_point() +geom_smooth(se =FALSE)
`geom_smooth()` using method = 'gam' and formula = 'y
~ s(x, bs = "cs")'
À première vue, le taux de survie semble diminuer avec l’âge, i.e. plus on est jeune, plus nos chances de survivre sont grandes. Remarquez dans ce graphique que les données observées sont soit des 0 ou des 1, mais que la courbe de lissage nous permet de visualiser la forme de la relation.
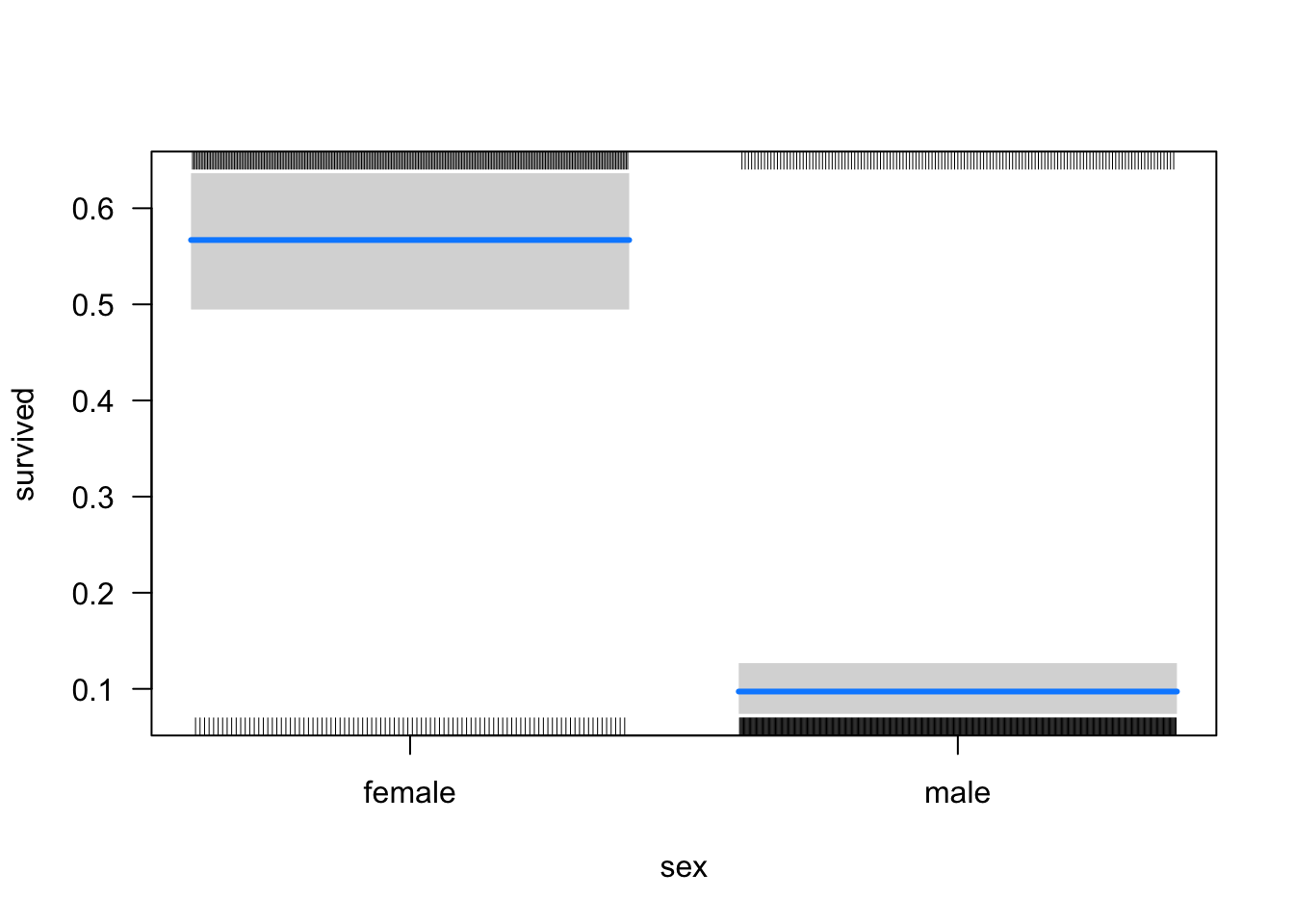
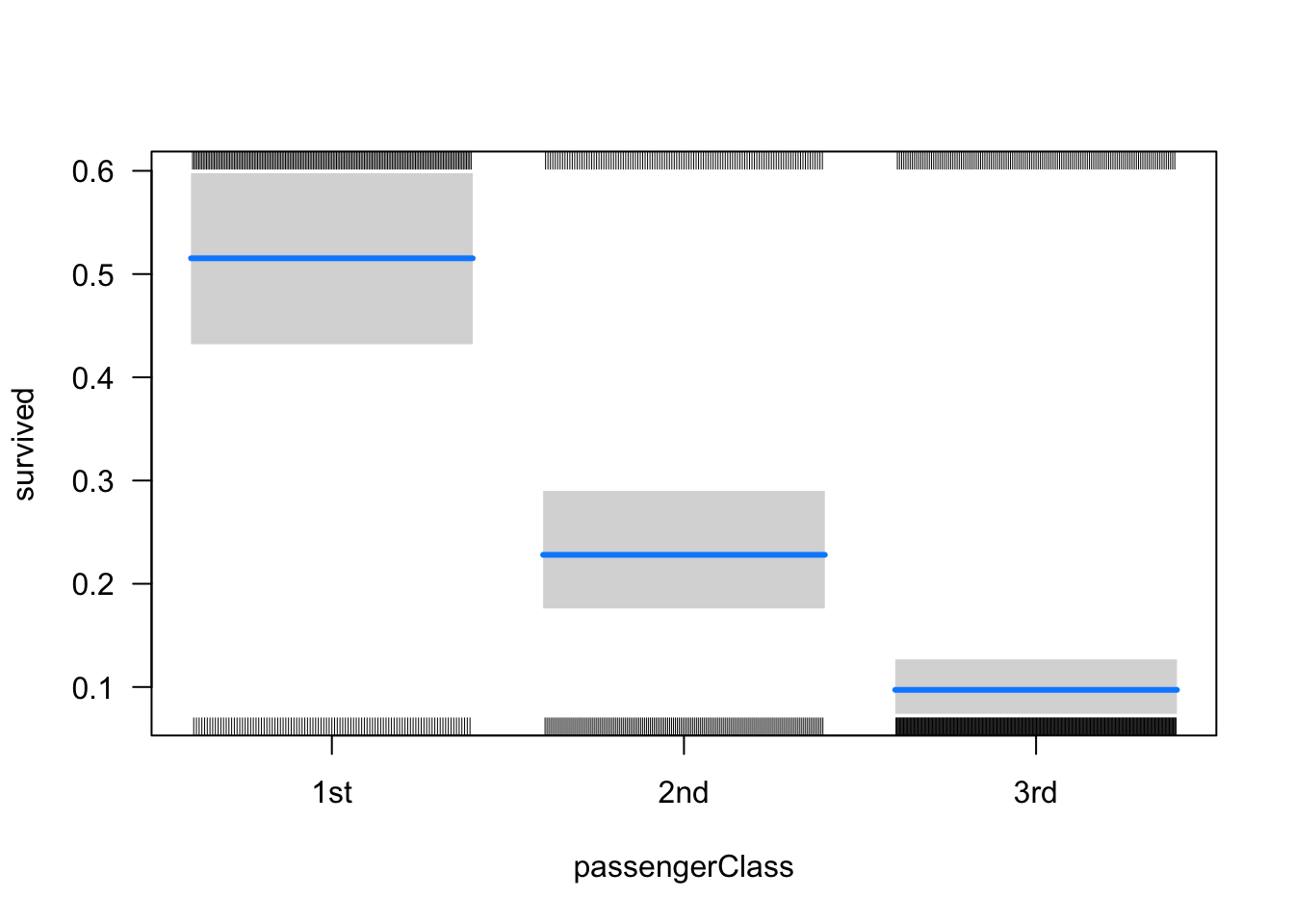
On peut aussi se faire une idée des taux de survie associés aux différents niveaux de nos variables catégoriques, par exemple comme ceci :
Donc, à première vue, les chances de survie des femmes étaient beaucoup plus élevées. De même, les passagers plus riches avaient beaucoup plus de chances de s’en sortir que les passagers moins fortunés.
Maintenant que nous avons exploré nos données, il est enfin temps de lancer notre modèle. La fonction pour calculer un GLM dans R se nomme, vous l’aurez deviné, glm :
m <-glm( survived ~ age + sex + passengerClass,data = donnees_glm,family ="binomial",na.action ="na.fail")
Comme pour nos autres modèles de régression on décrit par une formule que l’on veut expliquer la survie par l’âge, le sexe et la classe du passager. On fournit ensuite le tableau de données. L’argument supplémentaire à ajouter lorsque l’on calcule un GLM est qu’il faut spécifier la famille d’erreur de notre variable expliquée, ici, la famille binomiale.
Comme vous vous rappellez peut-être, dans un GLM, il faut aussi spécifier la fonction de lien, mais ici, puisque le lien logit est l’option par défaut de la famille binomiale, il n’est pas nécessaire de le spécifier. Enfin, j’ai aussi ajouté le na.action = "na.fail" puisque nous ferons, plus loin, une petite sélection de modèle avec la librairie MuMIn.
Ensuite, comme d’habitude, avant d’aller explorer nos résultats, il est important d’aller valider notre modèle. Pour se faire, il faut, comme toujours, aller ajouter les prédictions, les résidus et les distances de Cook à notre tableau de données.
donnees_glm <- donnees_glm |>mutate(predictions =predict(m, type ="response"),residus =resid(m),D =cooks.distance(m) )
Deux petites choses à remarquer ici. Tout d’abord, au moment d’extraire les prédictions, il est important de spécifier à R que l’on veut les prédictions de type réponse. C’est-à-dire que l’on veut obtenir les probabilités de survie pour chacun des passagers, et non le logit de la probabilité. Comme mentionné ci-haut, il est aussi important d’extraire les résidus de type déviance plutôt que les résidus bruts, mais ici, R comprend automatiquement que si on extrait les résidus d’un GLM, on veut les résidus de déviance.
Donc, la première chose que l’on peut valider à propos du modèle est de savoir si nos variables étaient trop colinéaires et pouvaient entraîner des instabilités dans notre modèle. On peut le vérifier avec le vif, comme dans un modèle linéaire ordinaire :
vif(m)
GVIF Df GVIF^(1/(2*Df))
age 1.354170 1 1.163688
sex 1.052059 1 1.025699
passengerClass 1.414640 2 1.090590
Ici, aucun problème, toutes les valeurs sont bien en-dessous de 4.
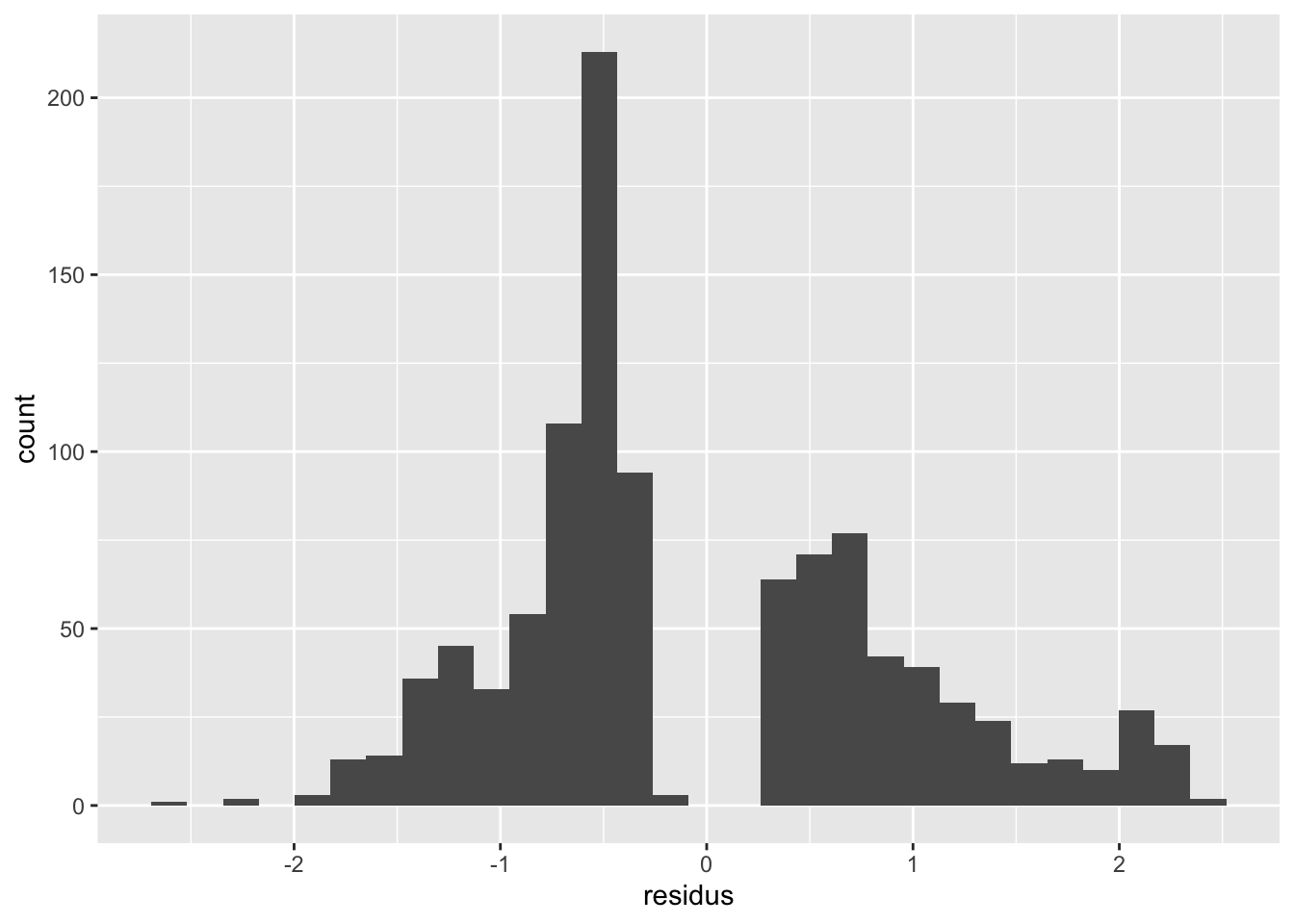
Deuxième chose que l’on peut regarder ensuite est la distribution des résidus. Comme discuté plus haut, des problèmes de normalité ici ne sont pas nécessairement indicatifs d’un mauvais modèle, mais il est tout de même intéressant de les regarder pour se donner une idée du comportement de notre modèle :
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
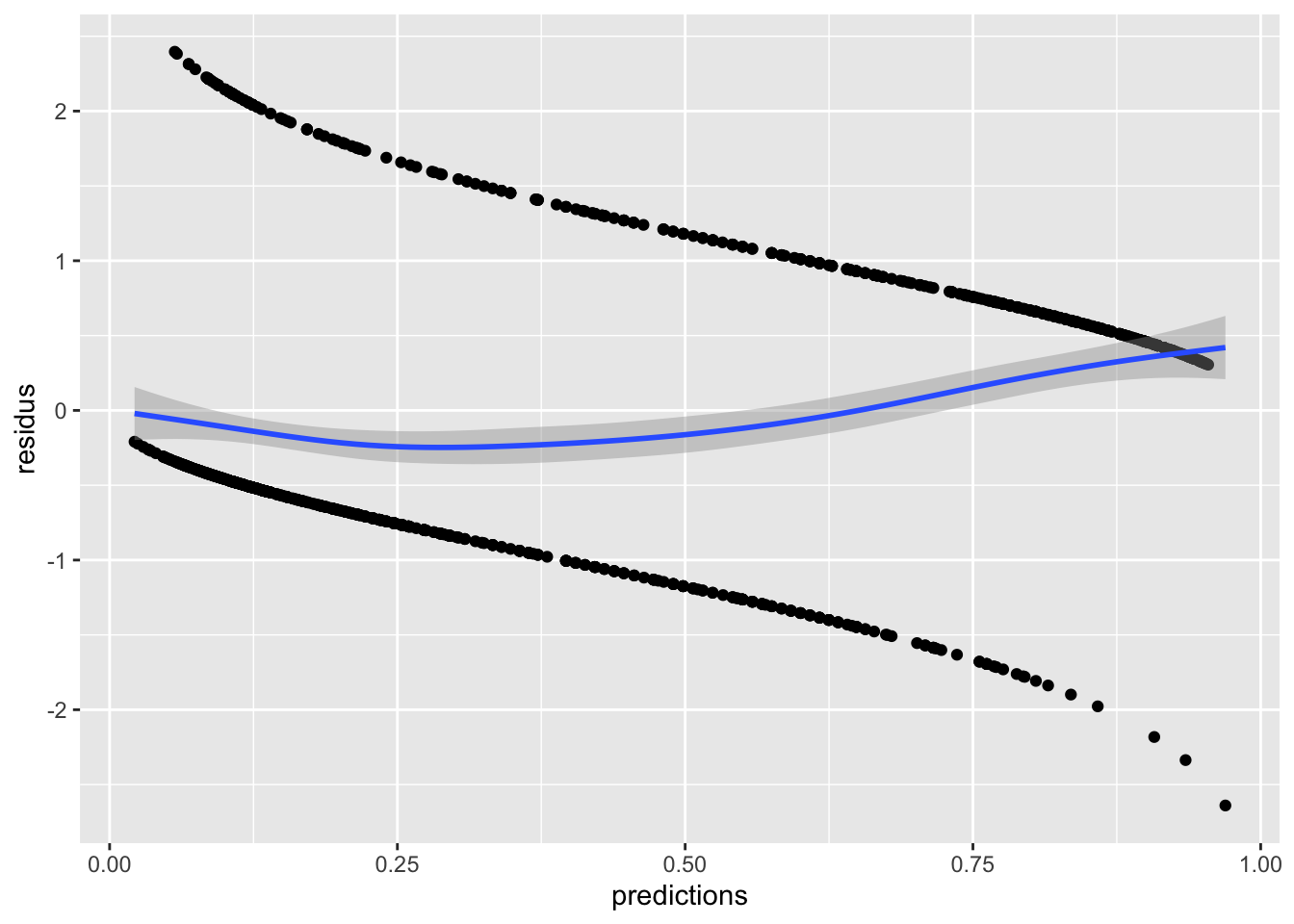
Le graphique le plus important à vérifier est la distribution des résidus en fonction des valeurs prédites :
donnees_glm |>ggplot(aes(x = predictions, y = residus)) +geom_point() +geom_smooth()
`geom_smooth()` using method = 'gam' and formula = 'y
~ s(x, bs = "cs")'
Comme discuté plus haut, il est souvent nécessaire d’ajouter une courbe de lissage à ce graphique afin d’aider notre œil à trouver des patrons. En général, les résidus sont plutôt homogènes, à part la partie vers les grandes probabilités qui ont tendance à être légèrement sous-estimées. On comprend aussi avec ce graphique pourquoi notre histogramme avait une drôle d’allure. Il n’y a à peu près pas de résidus tout près de zéro. La densité des points est beaucoup plus forte dans les valeurs intermédiaires autour de 50% de chances de survie.
Il serait important ici d’aller explorer aussi les résidus en fonction de l’âge, du sexe et de la classe de passager, mais je laisse cet exercice au lecteur afin de ne pas allonger inutilement cette section.
Une fois notre modèle inspecté, on peut effectuer une petite sélection de modèle pour s’assurer que toutes les variables pour lesquelles nous avions des hypothèses sont effectivement importantes. Pour cela, on peut utiliser, entre autres, l’approche par AIC :
Autrement dit, nos 3 variables sont clairement importantes pour expliquer la survie des passagers.
On peut maintenant, enfin, regarder les résultats de notre modèle :
summary(m)
Call:
glm(formula = survived ~ age + sex + passengerClass, family = "binomial",
data = donnees_glm, na.action = "na.fail")
Coefficients:
Estimate Std. Error z value
(Intercept) 3.522074 0.326702 10.781
age -0.034393 0.006331 -5.433
sexmale -2.497845 0.166037 -15.044
passengerClass2nd -1.280570 0.225538 -5.678
passengerClass3rd -2.289661 0.225802 -10.140
Pr(>|z|)
(Intercept) < 2e-16 ***
age 5.56e-08 ***
sexmale < 2e-16 ***
passengerClass2nd 1.36e-08 ***
passengerClass3rd < 2e-16 ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1414.62 on 1045 degrees of freedom
Residual deviance: 982.45 on 1041 degrees of freedom
AIC: 992.45
Number of Fisher Scoring iterations: 4
Donc, de ces résultats, on peut d’abord conclure que les chances de survie au naufrage diminuent effectivement avec l’âge (i.e. plus on est jeune, plus on survit). Les hommes ont moins de chance de survivre que les femmes. Enfin, plus un passager était riche (1ère vs. 3ème classe), plus il avait des chances de survivre. Ces résultats sont très rassurants, puisque l’on avait constaté la même chose dans notre exploration visuelle.
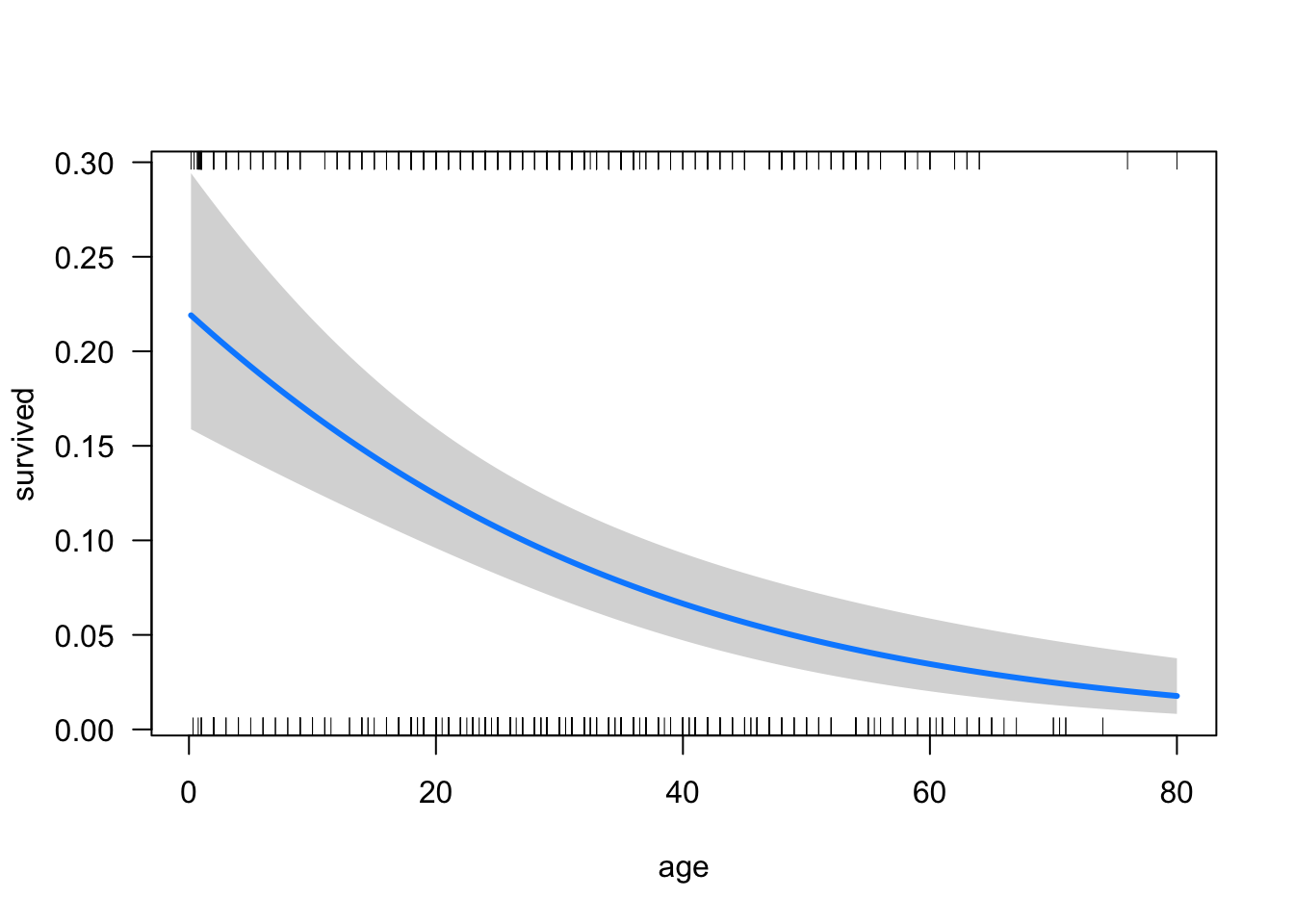
Par contre, comme discuté plus haut, ces chiffres sont difficiles à se mettre en tête. Par exemple, le paramètre associé à l’âge de -0,03 nous indique que le logit de la probabilité de survie diminue de 0,03 par année d’âge. C’est très peu parlant! Le mieux dans ce genre de situation est de visualiser chacun des paramètres avec un graphique :
Remarquez que pour chaque appel à visreg, on ajoute l’option scale="response", qui permet d’obtenir les résultats en termes de probabilités, plutôt qu’à l’échelle du lien logit.
En observant les pentes partielles associées aux paramètres, l’ampleur de l’importance de l’âge pour la survie est beaucoup plus claire. Pour un même sexe et une même classe, on passe d’environ 20% de chances de survie pour un enfant à 10% à 25 ans et pratiquement 0% passé la soixante. Si ces chiffres vous paraissent faibles, rappelez-vous que visreg calcule un graphique des effets marginaux. Dans ce cas-ci, la courbe correspond aux hommes et aux passagers de 3e classe, puisque ce sont les groupes les plus nombreux dans le tableau de données.
On voit aussi qu’une fois la correction pour l’âge appliquée, un femme avait plus de 50% des chances de survivre, alors qu’un homme avait moins de 10%, etc.
Par contre, bien qu’on ait une idée de la qualité du modèle grâce aux intervalles de confiance visuelles, nous n’avons pas de chiffre pour valider notre impression. Si on veut calculer la précision de notre modèle, on pourrait rapidement compter le nombre de fois où notre prédiction se révèle être la même que la valeur observée.
Pour se faire, on peut convertir toutes les prédictions >50% en 1 (survie) et celles <= 50% en 0 (décès). Ensuite, si l’on sait que R considère les valeur TRUE comme des 1 et les FALSE comme des zéros, on peut facilement calculer la précision de notre modèle, comme ceci :
Autrement dit, notre modèle a raison 78% du temps avec ses prédictions. Cependant, il ne faut pas oublier qu’un modèle idiot prédisant que tout le monde décède aura déjà raison 59% du temps.
Enfin, on peut calculer le D de Tjur pour se donner une idée de comment notre modèle réussit à distinguer les deux groupes, avec le calcul expliqué ci-haut :
Notre modèle explique donc 37% de la variance dans les taux de survie. Ce n’est pas si mal, mais loin d’être aussi fort que notre précision de 78% pouvait le laisser supposer.
33.9 Ouverture vers d’autres techniques
En terminant, je tenais à vous ouvrir la porte sur le fait qu’à partir d’ici de grandes possibilités de modélisation s’ouvrent à vous. Nous avons vu dans ce chapitre comment modéliser une variable en suivant la loi binomiale, mais on peut aussi le faire avec d’autres lois de probabilités comme celle de Poisson, Gamma, etc. Plusieurs distributions sont disponibles avec la fonction glm de base de R, mais il existe plusieurs librairies additionnelles fournissant un paquet d’autres lois (entre autres Beta, Binomiale-négative, etc.)
De même, bien que nous ayons vu les GLM et les modèles mixtes séparément, dans la réalité, ces deux techniques peuvent être combinées dans un même modèle, que l’on nomme alors de son acronyme anglais GLMM (Generalized Linear Mixed Models). Les librairies glmmTMB et lme4 sont, entre autres, conçues exactement pour ce genre de tâches.
33.4 Comment interpréter un modèle de régression logistique
Si on ajuste un modèle de régression logistique à nos données de survie, on obtiendra les paramètres suivants :
\[ \begin{aligned} B_0 = -4.77 \\ B_1 = 0.055 \end{aligned} \]
Autrement dit, la survie augmente selon la longueur du poisson (B1 > 0). Par contre, il est relativement complexe de se représenter l’ampleur de ce nombre puisque ce n’est pas directement la probabilité qui augmente de 0,055 par unité de longueur, mais bien le logit de la probabilité.
À cause de la transformation logit, l’effet d’un changement d’une unité de longueur n’aura pas le même effet selon l’intervalle de longueurs que l’on regarde. Pour constater cette différence, le plus simple est de se créer quelques prédictions. On pourrait par exemple prédire la probabilité de survie pour des poissons de 50 vs. 60 cm et 90 vs 100 cm à l’aide de notre modèle logit(π) = -4,77+0,055*longueur :
Ensuite, on peut passer du logit à la probabilité en inversant la transformation :
\[ \pi = \frac{exp(x)}{1+exp(x)} \]
Donc, autrement dit, une différence de 10 cm aurait un effet deux fois plus grand sur la probabilité de survie si notre poisson mesure 90 cm plutôt que 50 cm.
La façon la plus simple pour se faire une tête sur ce sujet est de visualiser l’ensemble de la courbe de probabilités :
Autrement dit, la probabilité de survie augmente lentement avant 50 cm, elle connaît son maximum d’augmentation autour de 90 cm et ensuite elle ralentit, jusqu’à ne plus vraiment augmenter au-delà de 140 cm.