install.packages("palmerpenguins")2 Les manchots de l’archipel Palmer
Comme vous le découvrirez bien assez tôt, charger nos propres données dans R n’est pas la tâche la plus simple lorsque l’on débute avec R. C’est pourquoi le début de ce livre sera axé sur un jeu de données déjà prêt pour nous, qui pourra nos accompagner au fil des chapitres et des apprentissages. Nous utiliserons pour cela des données provenant de la librairie de code palmerpenguins.
Ces données ont été recueillies sur 3 îles de l’archipel Palmer en Antarctique, de 2007 à 2009. Elles contiennent une séries de mesures morphologiques sur 3 espèces de manchots différentes présentes dans cet archipel, soit :
- Le manchot à jugulaire (Chinstrap)
- Le manchot papou (Gentoo) et
- Le manchot Adélie

Afin de limiter la charger mentale de passer constamment du noms français au nom anglais et vice-versa dans ce livre, nous utiliserons systématiquement les noms anglais puisque ce sont ceux que nous verrons dans les tableaux de données et dans les sorties des modèles.
Les données disponibles pour chaque individu sont :
- Le nom de l’espèce (species)
- L’île où a été effectuée la mesure (island)
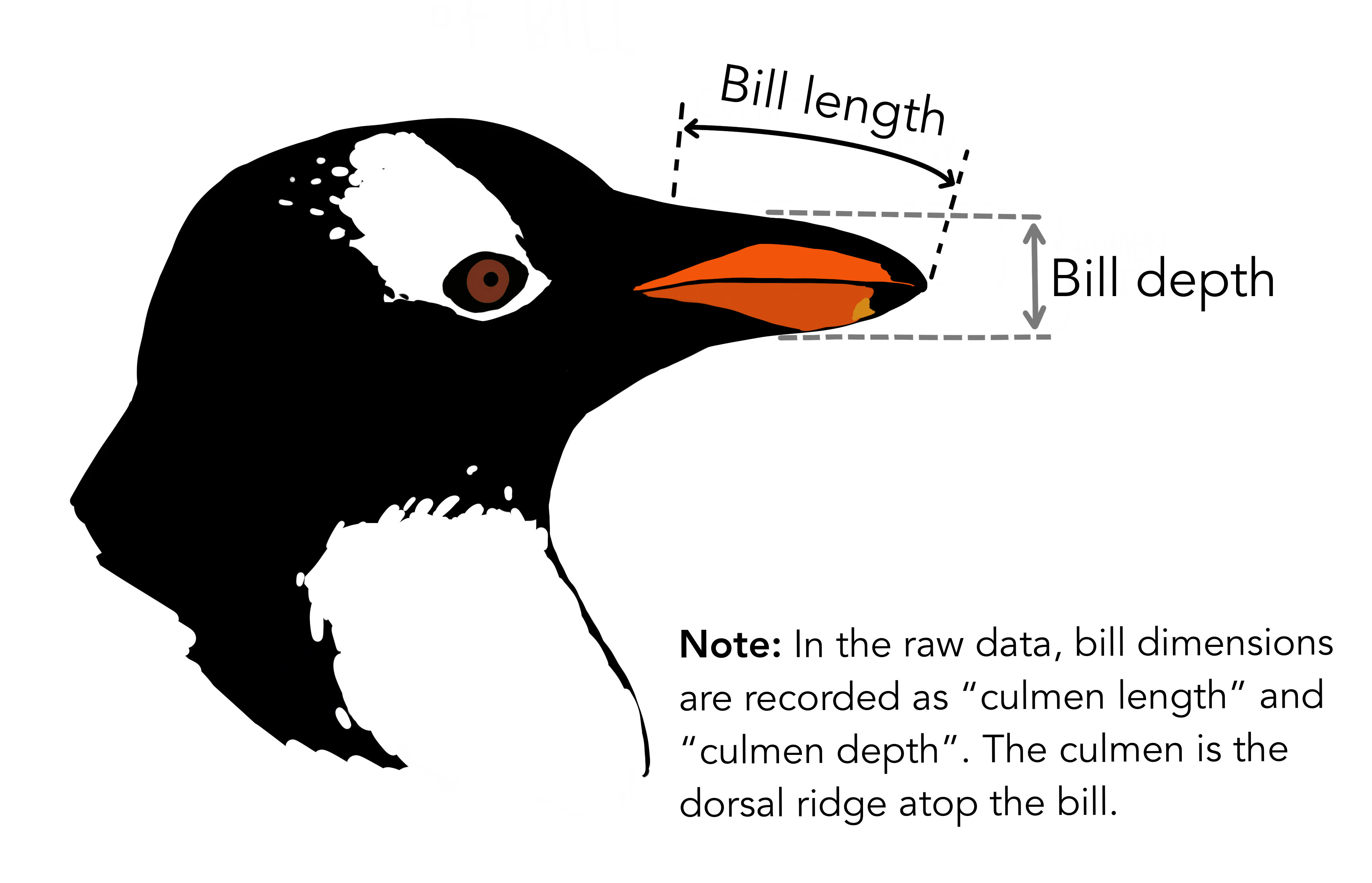
- La longueur du bec (bill_length_mm)
- L’épaisseur du bec (bill_depth_mm)
- La longueur des nagoires (flipper_length_mm)
- Le poids (body_mass_g)
- Le sexe (sex) et enfin
- L’année (year).
2.1 Les librairies de code dans R
Bien que nous n’ayons pas besoin nous-même de saisir les données concernant ces manchots, ces dernières ne sont pas incluses avec le logiciel R de base.
Comme nous l’avons vu dans l’introduction, R fait partie d’un écosystème complexe où beaucoup de gens contribuent du code ou des données gratuitement. Cela rend notre travail beaucoup plus agréable et rapide, mais implique aussi que l’on doit constamment installer ou mettre à jour ces contributions externes.
La façon classique de distribuer publiquement du code ou des données est de les inclure dans une librairie (package) déposée sur le serveur CRAN1. Cette organisation a pour mission d’effectuer un contrôle de qualité et d’offrir une infrastructure permettant de téléchager facilement ces librairies. Une librairie peut contenir du code R, des données, ou les deux.
2.2 Labo : Installation et activation de la librairie palmerpenguins
Pour utiliser une librairie provenant de CRAN, il faut suivre deux étapes importantes soit :
1. Télécharger la librairie sur votre ordinateur
Cette étape n’a besoin d’être effectuée qu’une seule fois. C’est équivalent d’installer un nouveau logiciel sur votre ordinateur ou une nouvelle appli sur votre téléphone.
On appelle la fonction install.packages, et on lui passe comme argument, entre guillemets, le nom de la librairie désirée :
Notez que pour que cela fonctionne, votre ordinateur doit être connecté à internet pour toute la durée de l’installation.
Astuce
Cette opération n’a pas besoin d’être répétée à chaque fois que vous ouvrez R. Une fois la librairie installée, elle y est pour toujours (du moins, tant que vous ne changez pas d’ordinateur ou de version de R.)
L’installation de librairies ne fait donc pas partie du processus d’analyse de données comme tel.
2. Activation de la librairie
Pour le moment, la librairie palmerpenguins est sur le disque dur de votre ordinateur, mais elle n’est pas encore prête à être utilisée par R. Comme vous aurez rapidement des dizaines, voire des centaines de librairies installées sur votre ordinateur, R trouve beaucoup plus poli d’attendre que vous lui demandiez explicitivement avant de charger une librairie en mémoire.
Donc, chaque fois que vous voudrez utiliser une librairie, vous devrez l’activer à l’aide de la commande library :
library(palmerpenguins)
Attaching package: 'palmerpenguins'The following objects are masked from 'package:datasets':
penguins, penguins_raw
Mise en garde
Portez une attention particulière au fait que l’on doit mettre des guillemets autour du nom de la librairie au moment de l’installation, mais que ces derniers sont optionnels au moment de l’activation.
Cette façon de faire a été maintes fois critiquée, mais demeure à ce jour le standard 2
Maintenant que le contenu de la librairie est prêt à être utilisé, on peut, par exemple, jeter un coup d’oeil aux premières lignes du tableau de données penguins avec la fonction head :
head(penguins)# A tibble: 6 × 8
species island bill_length_mm bill_depth_mm
<fct> <fct> <dbl> <dbl>
1 Adelie Torgersen 39.1 18.7
2 Adelie Torgersen 39.5 17.4
3 Adelie Torgersen 40.3 18
4 Adelie Torgersen NA NA
5 Adelie Torgersen 36.7 19.3
6 Adelie Torgersen 39.3 20.6
# ℹ 4 more variables: flipper_length_mm <int>,
# body_mass_g <int>, sex <fct>, year <int>Maintenant que nous connaissons un peu mieux les données avec lesquelles nous travaillerons, les prochains chapitres seront consacrées plus en détails, à leur exploration, leur visualisation, leur manipulation et leur description.