Nous avons vu au Chapitre 15 une technique nommée ANOVA à un facteur. Cette dernière permettait de tester si une variable catégorique avait un effet significatif sur une variable quantitative.
Nous verrons au Chapitre 30 qu’il est possible de combiner des variables catégoriques et quantitatives dans un même modèle statistique. Cette façon de faire est clairement celle que je privilégie, i.e. d’utiliser le modèle linéaire dans la majorité des circonstances, puisqu’elle est beaucoup plus flexible.
Cependant, il existe aussi des extensions de l’ANOVA permettant d’intégrer plusieurs variables explicatives dans ce type de test. Bien que je ne sois pas un pratiquant de cette approche, je vous l’expose tout de même ici, car (1) elle est tout de même utilisée, entre autres en biologie médicale et (2) qu’elle permet une réflexion sur le design d’expérience qui pourra vous être bénéfique de toute façon.
Vous constaterez que la complexité des ANOVA à plusieurs facteurs tient beaucoup, comme dans plusieurs approches statistiques, à la tonne de nouveau vocabulaire à assimiler.
16.2 L’ANOVA en blocs aléatoires
Vous vous rappelez peut-être que dans l’ANOVA à un facteur, chaque observation était indépendante et effectuée sur un individu ou une parcelle différente. Cela faisait partie des assomptions de la technique.
Dans l’ANOVA en blocs aléatoires, différents traitements (ou conditions) sont regroupés physiquement ou spatialement dans un bloc. Chaque traitement est appliqué une seule fois par bloc.
On obtient une ANOVA en blocs aléatoires par exemple si on choisit 10 champs agricoles où effectuer notre expérience, et que dans chaque champ, on choisit un site contrôle, un site où on ajoute de l’engrais et un site où on arrose plus fréquemment.
Voici une comparaison schématique de l’ANOVA à un facteur et de l’ANOVA en blocs aléatoires :
ANOVA à un facteur
ANOVA en blocs aléatoires
Ce type de design ajoute, outre l’effet du traitement et l’erreur intra-groupe que nous avions dans l’ANOVA à un facteur, un troisième compartiment de variation, soit la variabilité entre les blocs :
Source
Degrés de liberté
Carrés moyens
Ratio de F
Traitements
a-1
SStraitement/(a-1)
MStraitement/MSintra
Blocs
b-1
SSbloc/(b-1)
MSbloc/MSintra
Intra-groupe (résidus)
(a-1)(b-1)
SSintra/(a-1)(b-1)
Où a est le nombre de traitements et b est le nombre de blocs.
On peut donc ici tester deux hypothèses avec cette technique :
Est-ce qu’il y a une différence entre les blocs (rarement une question d’intérêt biologique) et
est-ce qu’il y a une différence entre les traitements.
Remarquez que le calcul du ratio de F pour l’effet du traitement est le même que dans l’ANOVA à un facteur, sauf pour les degrés de liberté des résidus qui sont réduits, car ils sont “passés” dans l’estimation des effets de bloc.
Ce qui veut dire que si les différences entre les blocs sont grandes, le test sera plus puissant parce que l’on réduit considérablement le compartiment intra (les résidus). Par contre, si les différences entre les blocs sont petites, le test sera moins puissant car on gaspille des degrés de liberté pour estimer l’effet entre les blocs.
16.3 ANOVA pairée et mesures répétées
Vous verrez souvent dans la littérature les termes ANOVA pairée et ANOVA pour mesures répétées. Bien qu’ayant leurs propres noms, ces deux techniques sont des versions spécifiques de l’ANOVA en blocs aléatoires.
Dans le cas de l’analyse pairée, il s’agit d’un design en blocs aléatoires, mais où notre variable catégorique ne possède que deux niveaux. Les traitements sont donc appliqués “par paire” sur chacun des individus/sites/parcelles, etc.
Dans le cas de l’analyse pour mesure répétées, chaque “bloc” de traitement est représenté par un individu. Les différents moments dans le temps correspondent aux différents niveaux de la variable catégorique. Conceptuellement la question est très différente de l’ANOVA en blocs aléatoires, mais les analyses statistiques sont exactement les mêmes.
16.4 Labo : L’ANOVA en blocs aléatoires
Pour essayer l’ANOVA en blocs aléatoires, nous allons avoir besoin de données appropriées, structurées en blocs. Je vous ai préparé un fichier Excel, contenant trois onglets, avec des données déjà prêtes à être traitées1. Remarquez que ces données sont déjà organisées correctement au format long, mais que dans la vraie vie, il est possible que vous ayez à réorganiser vos données avant de procéder.
Nous étudierons donc dans ce chapitre la réponse chimique des plantes à divers types d’attaques2. Notre variable expliquée sera dans tous les cas, la concentration en composés phénoliques (mg par g de biomasse sèche). Pour l’ANOVA en blocs aléatoires nous allons regarder l’effet d’une simulation d’herbivorie. Notre variable catégorique aura 3 niveaux, soit Contrôle, Défoliation (enlever toutes les feuilles) et Taille (couper entièrement la tige). Une série de parcelles ont été choisies pour l’expérience, et dans chaque parcelle, nous avons choisi un individu différent pour chacun des traitements.
Commençons par activer les librairies et charger les données :
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.2.1
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Après cette étape, il faudrait normalement inspecter les données, regarder les distributions des variables, etc., mais pour accélérer ce chapitre, assumez que j’ai déjà tout fait ça pour vous.
Pour ajuster une ANOVA en blocs aléatoires, on utilise la fonction aov (comme pour l’ANOVA à un facteur), à laquelle on passe une formule, dans laquelle on mentionne notre variable de traitement (Herbivorie) et notre variable de bloc (Parcelle), comme ceci :
modele <-aov(Concentration_Phenols ~ Herbivorie + Parcelle , data = randomized_block)
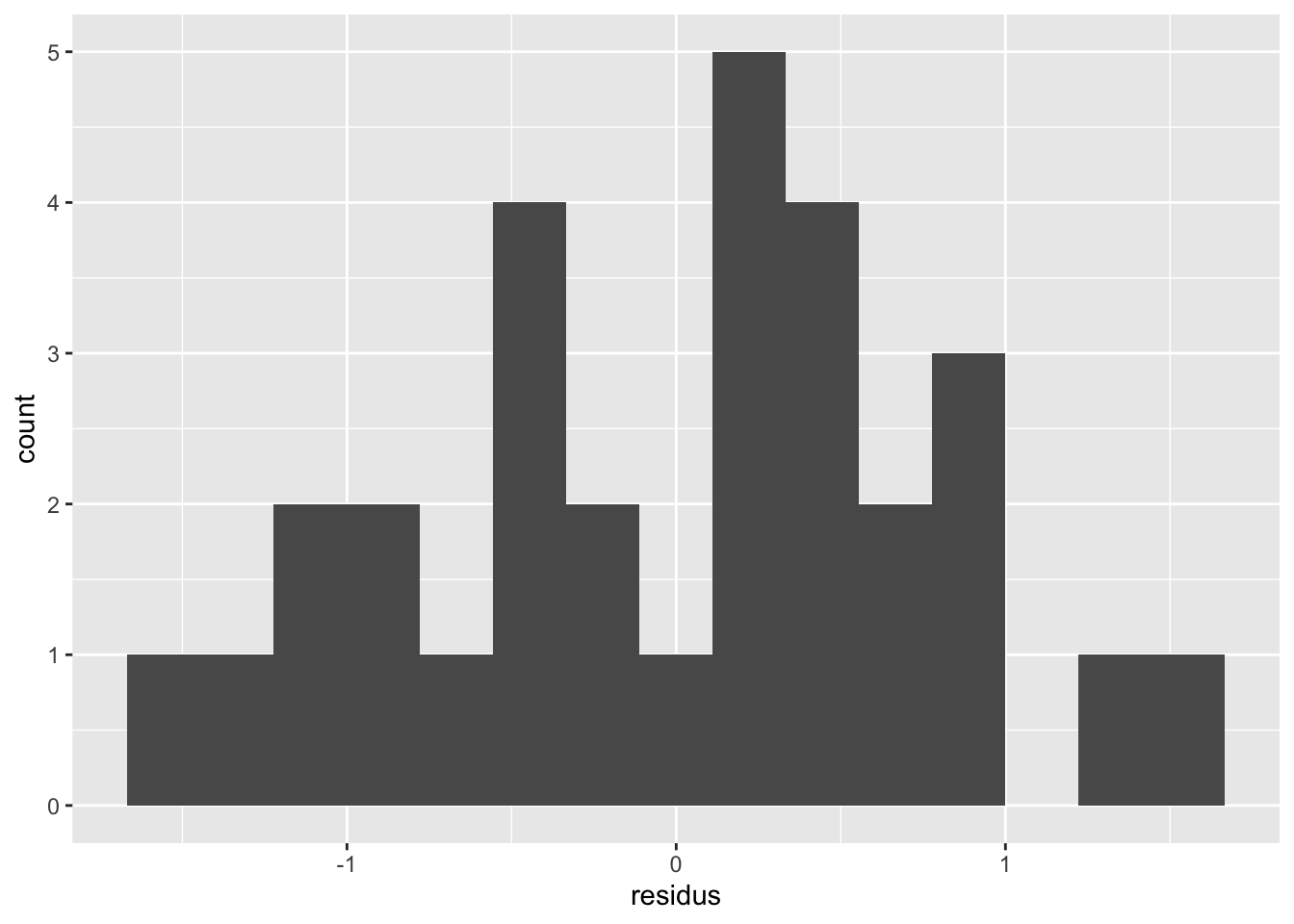
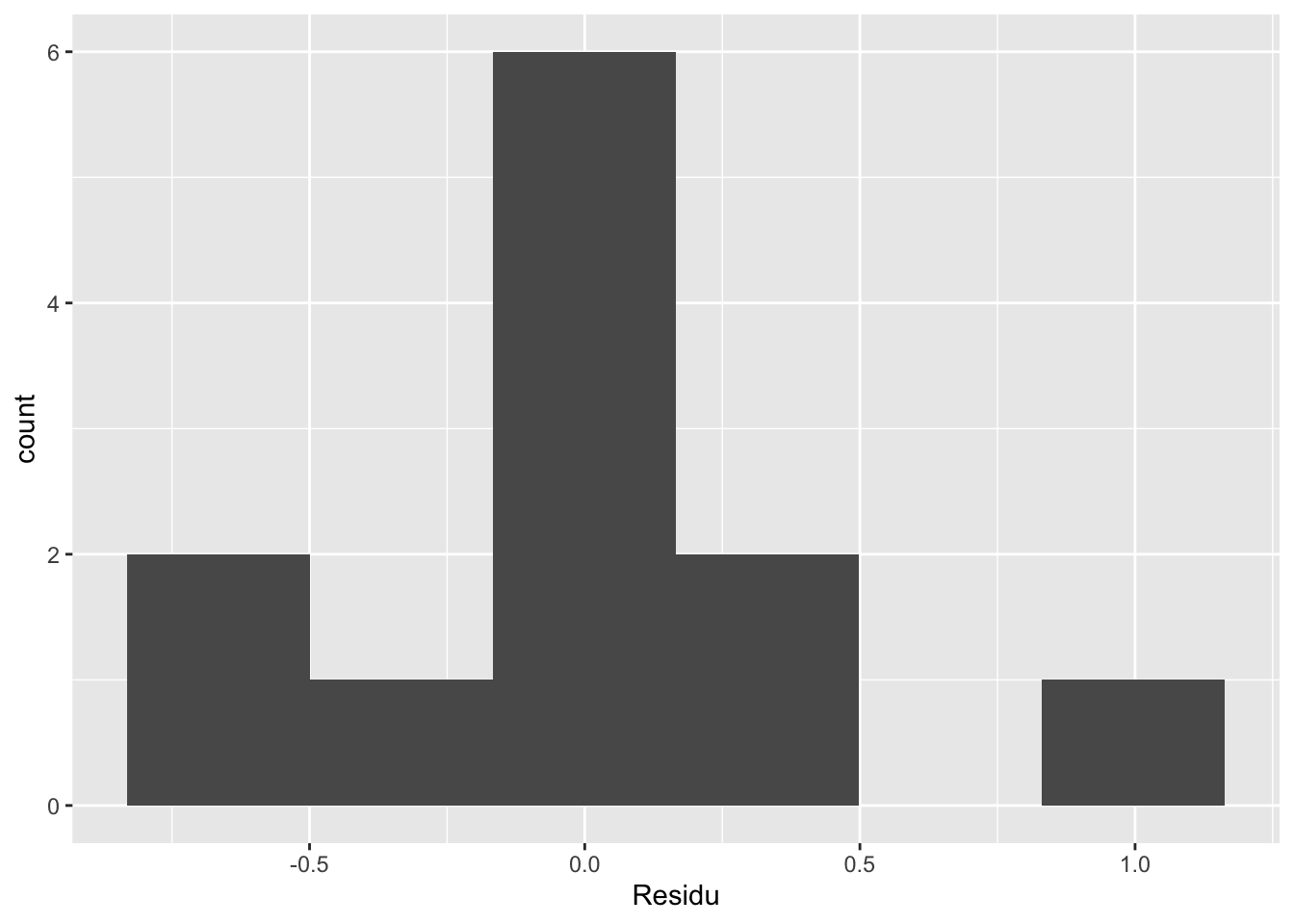
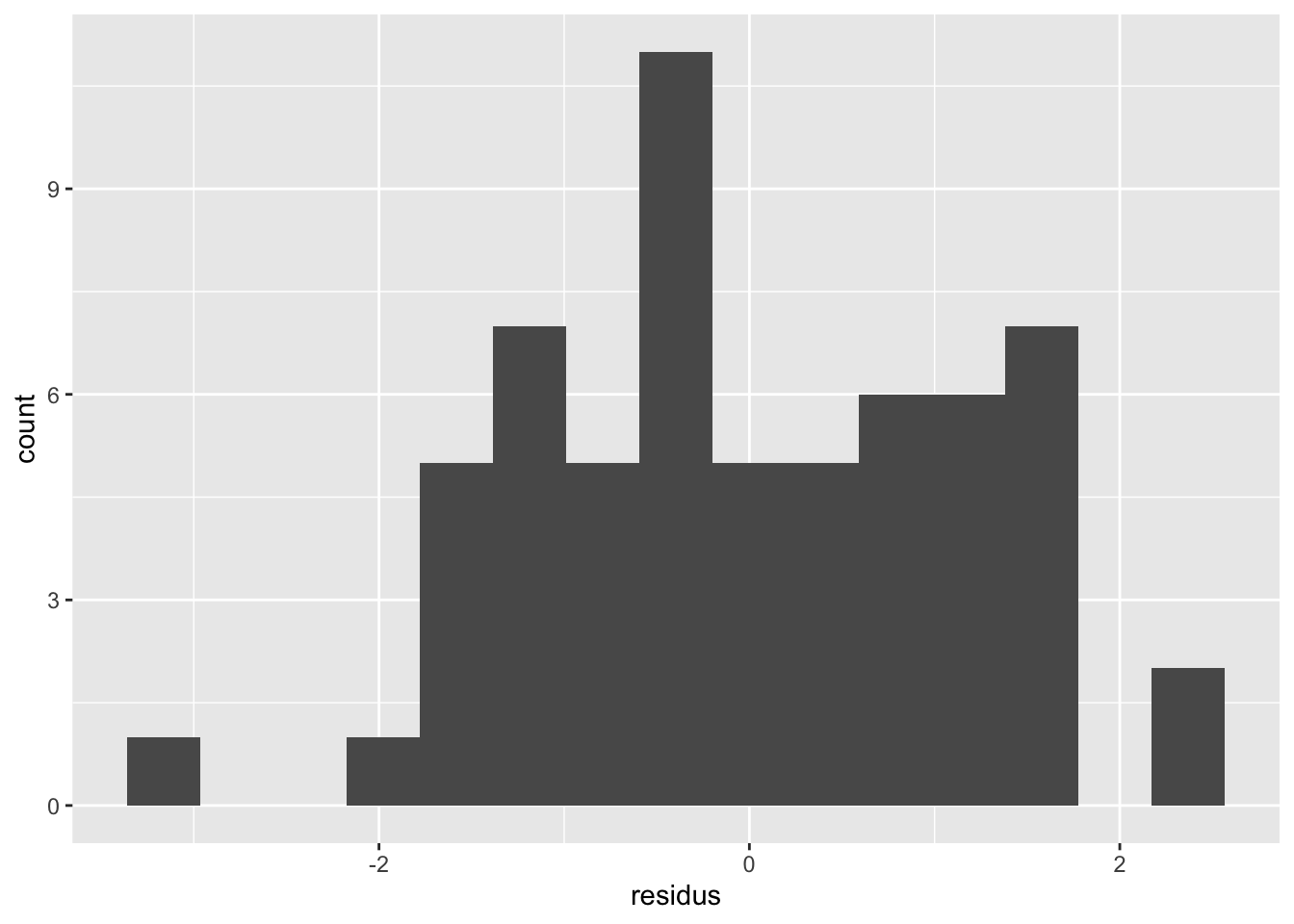
Attrapons maintenant les résidus de ce modèle pour pouvoir les valider :
La distribution n’est pas trop mal. Rien d’inquiétant.
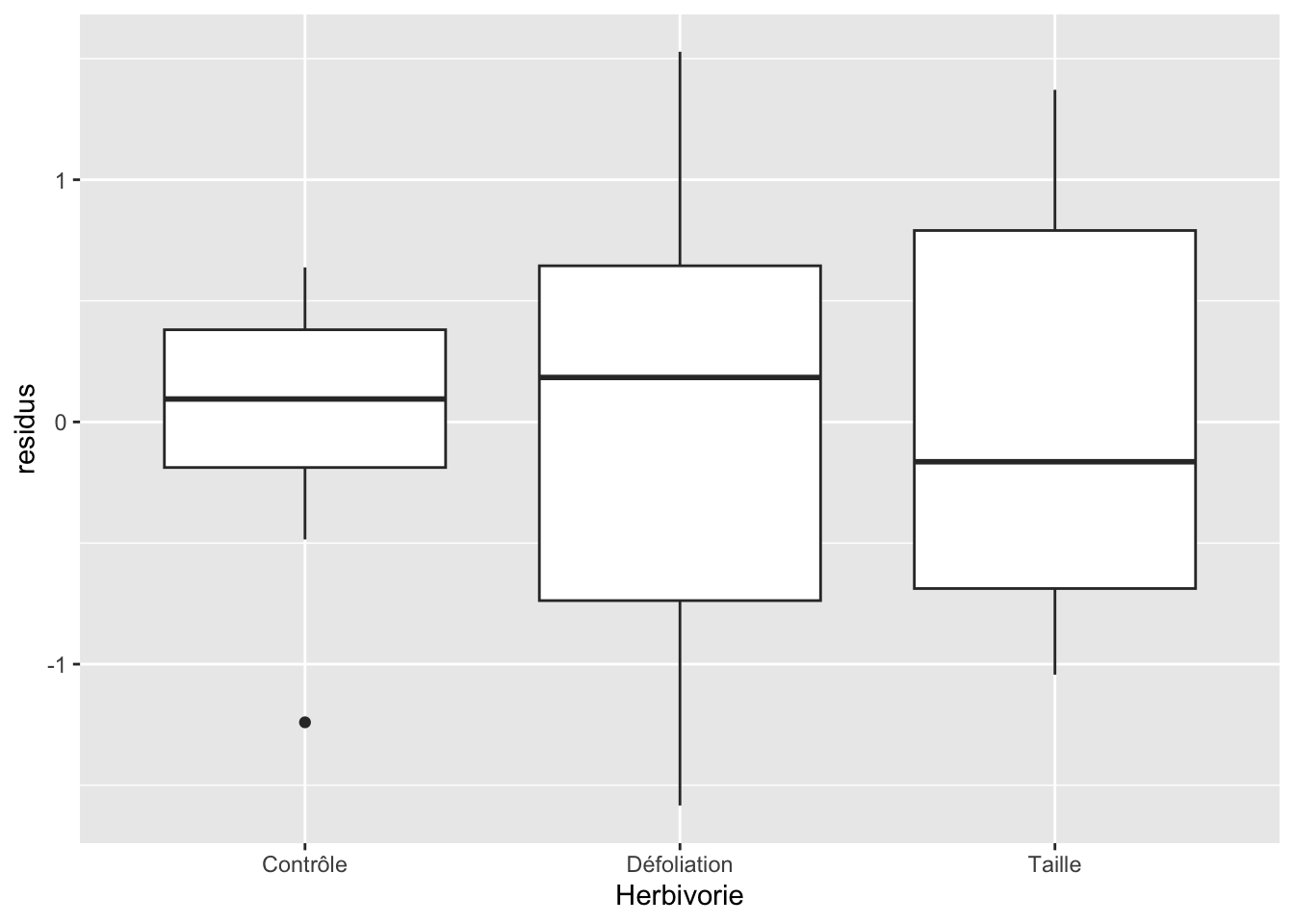
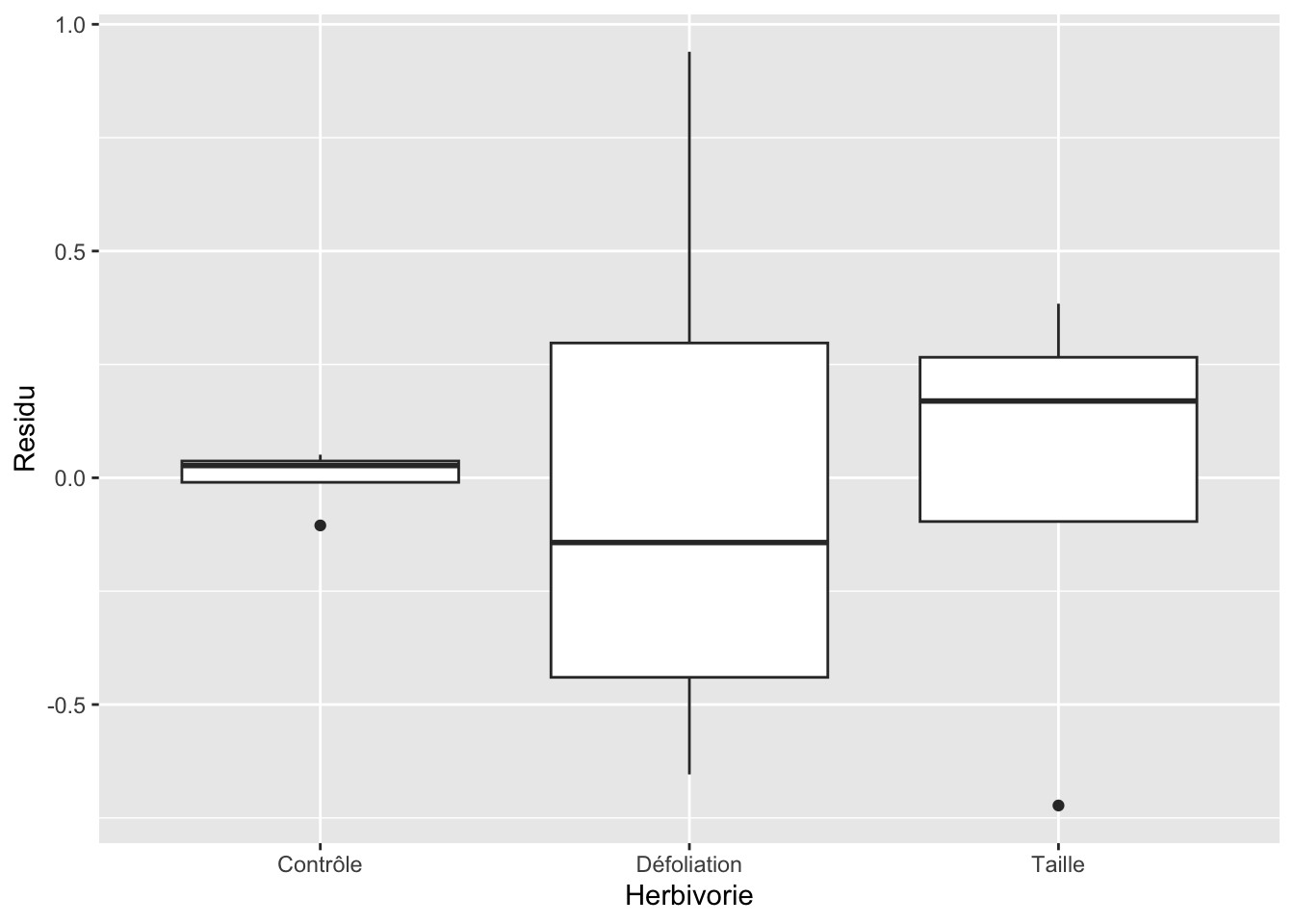
Pour l’homogénéité des résidus, on doit faire comme pour l’ANOVA à un facteur, c’est-à-dire procéder à l’aide d’un diagramme à moustache et s’assurer que les boîtes sont relativement semblables entre les différents niveaux de notre variable catégorique :
Une fois tout cela vérifié, on peut maintenant regarder les résultats de notre modèle :
summary(modele)
Df Sum Sq Mean Sq F value Pr(>F)
Herbivorie 2 51.68 25.841 25.52 5.57e-06 ***
Parcelle 9 6.29 0.699 0.69 0.709
Residuals 18 18.23 1.013
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
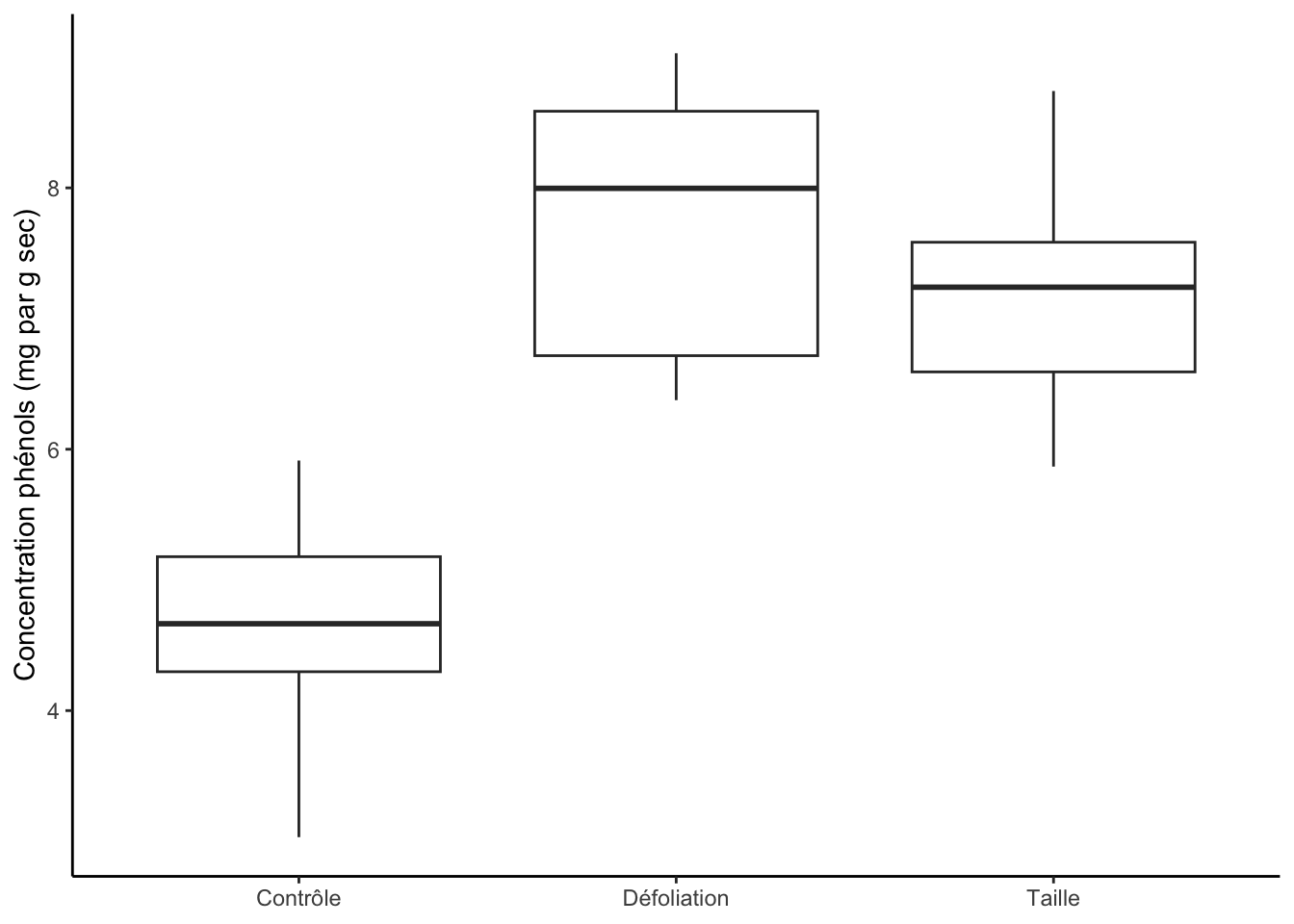
Comme discuté ci-haut, l’ANOVA en blocs aléatoires effectue en fait deux tests. Un premier sur notre variable d’intérêt (ici l’herbivorie) et un deuxième sur notre variable de bloc (ici la parcelle). Nos résultats indiquent que la concentration en phénols varie en fonction de notre traitement (p<0,05), mais qu’il n’y a pas de différence significative entre les parcelles comme tel (p>0,05).
Si on avait à produire un graphique de ces résultats, la meilleure façon serait probablement à l’aide d’un diagramme à moustaches, un peu comme ceci :
ggplot(randomized_block, aes(Herbivorie,Concentration_Phenols)) +geom_boxplot() +theme_classic() +labs(x =NULL, y ="Concentration phénols (mg par g sec)")
16.5 L’ANOVA imbriquée
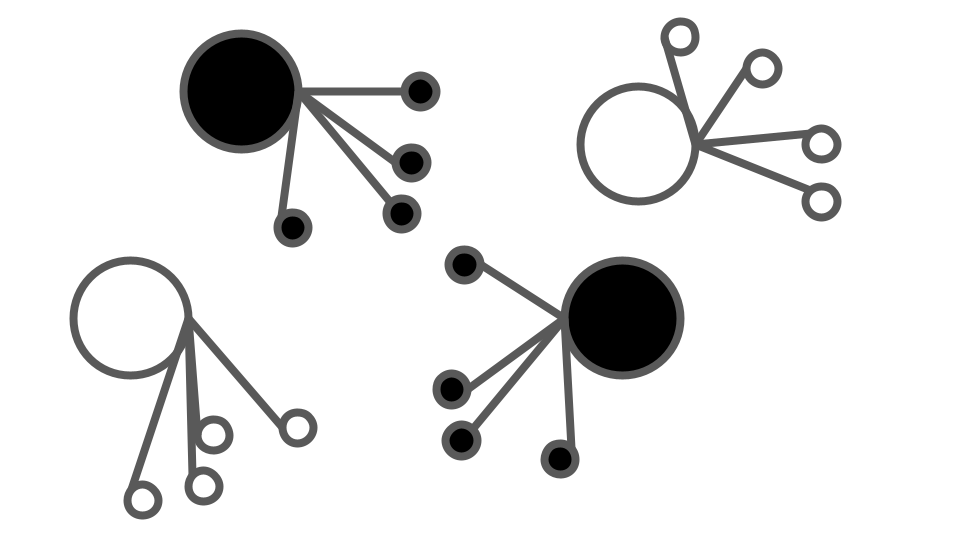
Dans un design imbriqué, chaque échantillon (site/parcelle/individu) ne subit qu’un seul des traitements. Par contre, cet échantillon est sous-échantillonné (mesuré) plusieurs fois. Conceptuellement, on pourrait représenter l’ANOVA imbriquée comme ceci :
Remarquez que dans cette façon de faire, le nombre d’échantillons indépendants n’augmente pas, uniquement le nombre d’observations.
Particularités statistiques
Comme pour l’ANOVA en blocs aléatoires, les carrés moyens sont partitionnés en 3 compartiments. Les calculs sont par contre modifiés, avec d’importantes conséquences statistiques. La plus importante étant que le ratio de F pour les traitements n’est plus divisé par les résidus intra mais par les carrés moyens des échantillons.
Source
Degrés de liberté
Carrés moyens
Ratio de F
Traitements
a-1
SStraitement/(a-1)
MStraitement/MSéchantillons
Échantillons d’un traitement
a (b-1)
SSéchantillon/a (b-1)
Intra-échantillon (résidus)
a b (n-1)
SSintra / a b (n-1)
Où a est le nombre de traitements, b est le nombre d’échantillons indépendants pour chaque niveau de traitement et n est le nombre de sous-échantillons pour chaque échantillon.
Le calcul de l’ANOVA imbriquée est mathématiquement équivalent à calculer la moyenne des sous-échantillons dans chaque échantillon et d’utiliser cette information dans une ANOVA à un facteur classique.
Avertissement
Ce qu’il est important de retenir à propos des ANOVA imbriquées est que les logiciels de statistiques ne peuvent PAS deviner que votre ANOVA est imbriquée plutôt qu’en blocs aléatoires. C’est à vous de le mentionner explicitement dans la formulation de votre analyse.
Oublier de le faire augmente de façon importante la possibilité d’erreur de type I de votre test, puisque vous considererez alors comme indépendants des échantillons qui ne le sont pas. Il s’agirait d’une erreur grave pouvant remettre en cause tous vos résultats.
16.6 Labo : L’ANOVA imbriquée
Pour illustrer l’ANOVA imbriquée, nous allons reprendre l’expérience précédente, mais cette fois-ci, les concentrations de phénols ont été mesurées 5 fois sur chacun des individus.
modele <-aov(Concentration_Phenols ~ Herbivorie +Error(Individu), data = nested)
Remarquez bien l’ajout, où notre variable qui désigne l’identité des individus a été “emballée” de la fonction Error. C’est la façon d’expliquer à R que les individus ont été sous-échantillonés plusieurs fois, et donc que nos lignes dans notre tableau de données ne sont pas entièrement indépendantes les unes des autres. Il s’agit de la clé pour bien faire les ANOVA imbriquées dans R.
Si on observe les résultats de ce modèle, on remarque que les résultats sont maintenant séparés en deux parties :
summary(modele)
Error: Individu
Df Sum Sq Mean Sq F value Pr(>F)
Herbivorie 2 87.14 43.57 35.62 5.3e-05 ***
Residuals 9 11.01 1.22
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 48 43.06 0.8972
La partie qui nous intéresse de prime abord est la première, où l’on peut constater que la différence entre nos traitements d’herbivorie est significative. La somme des carrés des erreurs utilisées pour ce calcul provient de la différence entre les individus.
L’erreur provenant de la variabilité entre les sous-échantillons provenant d’un même individu a été séparée dans l’autre partie (Error Within) et n’est pas utilisée dans le calcul de la valeur de F pour notre traitement d’herbivorie.
Rappelez-vous que le calcul de l’ANOVA imbriquée fonctionne exactement comme si, pour faire le calcul, nous avions utilisé la moyenne des sous-échantillons plutôt que leurs valeurs individuelles. Pour cette raison, la validation des résidus est un peu plus complexe que dans les autres ANOVA, et nous amènera à faire le calcul des résidus manuellement :
`summarise()` has grouped output by 'Individu'. You
can override using the `.groups` argument.
Ce n’est pas si important que vous compreniez tous les détails du calcul ci-haut. Il faut seulement être capable de remplacer les noms de variables pour les adapter à vos analyses le moment venu. En gros, la chaîne commence par calculer une moyenne de phénols pour chacun des individus, ensuite, elle ajoute une colonne de moyenne de phénols par niveau d’herbivorie (la prédiction), puis soustrait ces deux valeurs pour obtenir un résidu.
Une fois ce tableau obtenu, on fait les deux graphiques habituels, soit la normalité des résidus, et l’homogénéité entre les groupes. Remarquez que, bien que nous avions recueilli 60 échantillons dans notre expérience, nous n’avons dans les faits que 12 individus indépendants :
C’est aussi normal qu’on peut l’espérer avec seulement 12 observations.
Ensuite, il faut aussi regarder l’homogénéité de la variance entre les groupes :
ggplot(pour_validation, aes(x = Herbivorie, y = Residu)) +geom_boxplot()
Ici, c’est loin d’être parfait visuellement. Mais gardez en tête que chaque boîte ne représente en fait que 4 points. Si on observait le même genre de résultats avec 15-20 points par boîte, il y aurait lieu de s’inquiéter.
Dans ce genre de situation, il peut être légitime d’utiliser le test de Levene pour se rassurer :
library(car)
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
The following object is masked from 'package:purrr':
some
leveneTest(Residu~Herbivorie, data = pour_validation)
Warning in leveneTest.default(y = y, group = group,
...): group coerced to factor.
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 2.0451 0.1853
9
Comme l’hypothèse nulle de ce test est que la variance est homogène entre les groupes et qu’ici on ne peut pas rejeter l’hypothèse nulle (p>0,05), on est donc rassurés, la variance est homogène entre nos groupes.
16.7 L’ANOVA à deux facteurs croisés
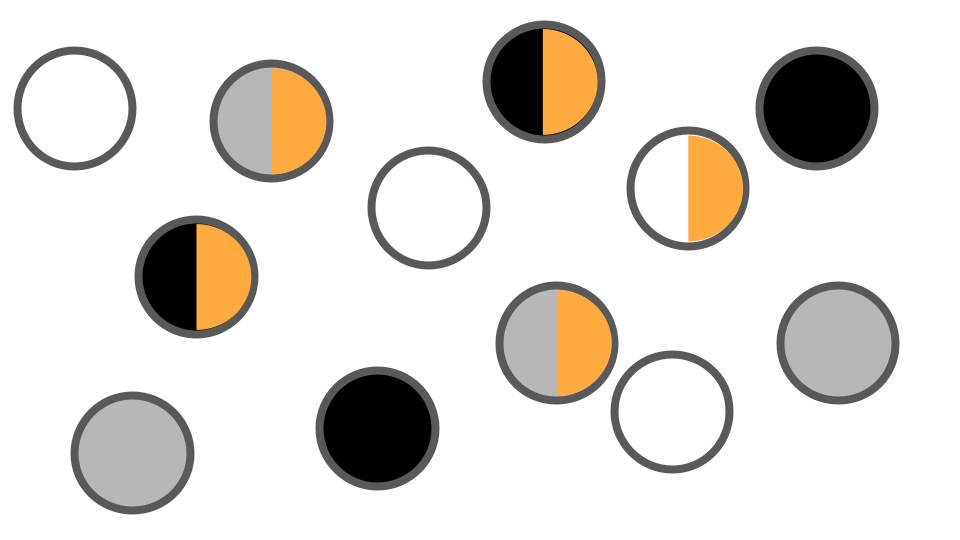
L’ANOVA à deux facteurs croisés s’utilise lorsque l’on veut tester simultanément l’effet de deux variables catégoriques sur notre variable expliquée. Chacune des variables peut avoir plusieurs niveaux. Dans la visualisation ci-dessous, on teste une première variable à trois niveaux (noir, gris ou blanc) et une deuxième variable à un niveau (orange ou non) :
Pour que l’analyse à deux facteurs croisés fonctionne correctement, il est important que chaque combinaison de traitements soit présente, et testée le même nombre de fois. Par exemple, pour tester à la fois l’effet d’augmenter ou diminuer le pH dans une culture et l’effet d’ajouter ou non du NaCl, nous aurions pu créer l’expérience suivante :
Contrôle
NaCl
Contrôle
3 plantes
3 plantes
pH+
3 plantes
3 plantes
pH-
3 plantes
3 plantes
Si on calcule un minimum comme ici de 3 observations par combinaison de traitement, on constate que le nombre d’individus nécessaires devient rapidement élevé. Par exemple, ici, nous avons besoin de 18 individus pour tester nos deux variables.
Le grand avantage de ce genre de design est qu’il permet aussi de tester la présence d’interaction entre nos traitements.
Traitement statistique
L’analyse de la variance de ce modèle à deux facteurs croisés nécessite maintenant la description de 4 compartiments de variance, soit :
Source
Degrés de liberté
Carrés moyens
Ratio de F
Variable A
a-1
SSA/(a-1)
MSA/MSintra
Variable B
b-1
SSB/(b-1)
MSB/MSintra
Interaction
(a-1)(b-1)
SSAB/(a-1)(b-1)
MSAB/MSintra
Intra-groupe (résidus)
a b (n-1)
SSintra / a b (n-1)
Où a est le nombre de niveaux de la variable A, b est le nombre de niveaux de la variable B et n est le nombre de réplicats pour chaque combinaison.
Il est possible de “récupérer” des expériences où le n n’était pas égal dans chacune des cellules, en passant par une approche de modèle linéaire mixte (Chapitre 32) plutôt que d’ANOVA.
16.8 Labo : L’ANOVA à deux facteurs croisés
Pour essayer l’ANOVA à plusieurs facteurs, nous allons reprendre l’expérience précédente où on simulait l’herbivorie sur une série de plantes, mais ici, on ajoutera en plus une deuxième variable dans notre expérience, où la moitié des plantes seront aussi soumises à une expérience où on augmente artificiellement la compétition.
Comme expliqué dans la théorie, il faut penser à l’ANOVA à deux facteurs croisés comme si on roulait deux expériences simultanément. Ici, on en fait une sur la compétition et une sur l’herbivorie.
Donc, on peut charger nos données, qui sont dans la 3e feuille du fichier Excel, puis on ajuste le modèle à l’aide de la fonction aov. Comme on veut savoir si l’effet de l’herbivorie est le même sous forte compétition ou non, on ajoutera aussi un terme d’interaction au modèle, comme ceci :
two_way <-read_excel("donnees/PourANOVA.xlsx", sheet =3)modele <-aov(Concentration_Phenols ~ Herbivorie+Competition+Herbivorie:Competition, data = two_way)
Remarquez que l’on devrait ici aussi inspecter correctement nos données avant de commencer à travailler, mais nous ne le ferons pas ici pour ne pas étirer ce chapitre.
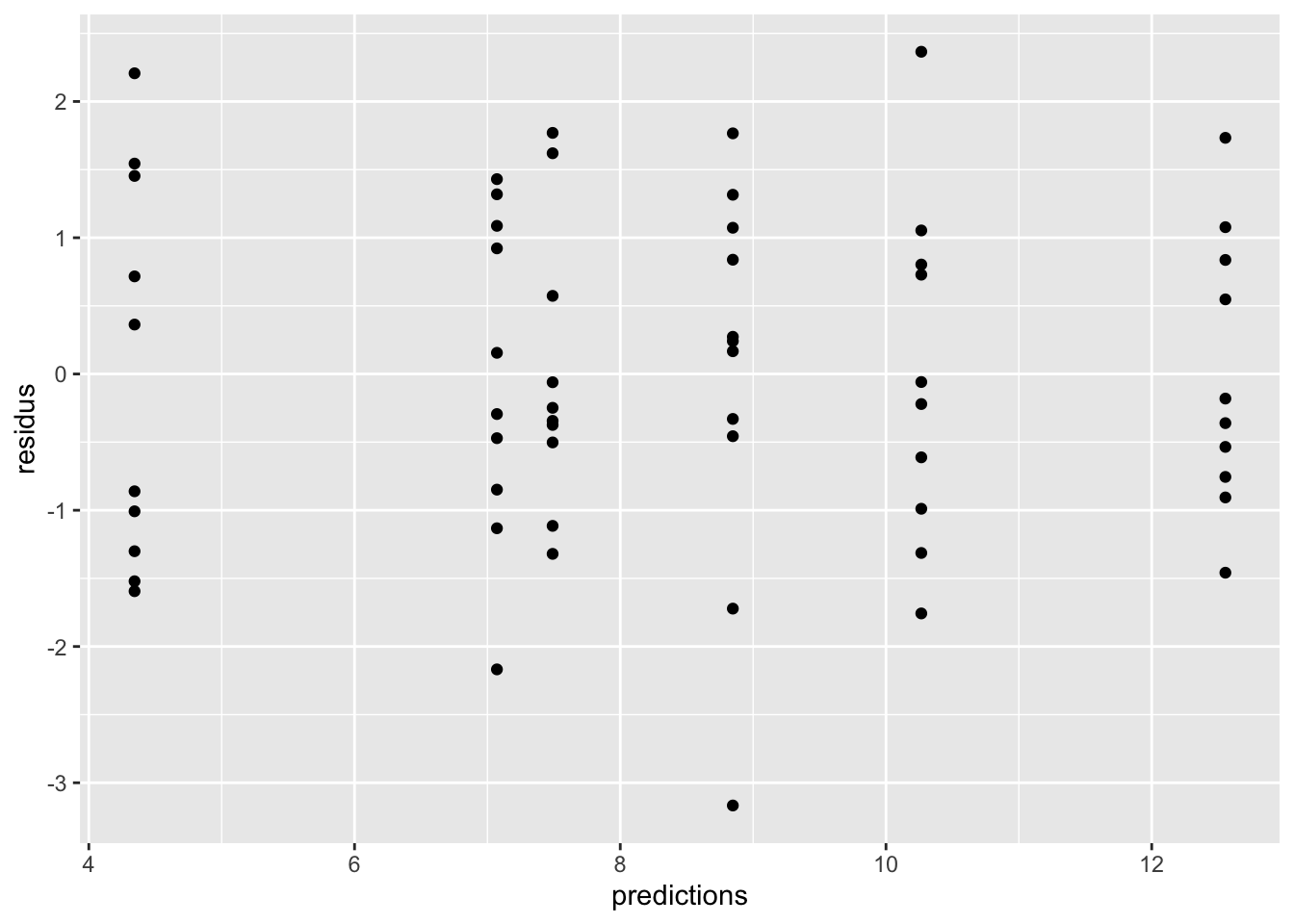
Une fois le modèle ajusté, il faut, comme toujours, l’inspecter avant de procéder à son interprétation. Nous allons conserver, comme pour la régression, les prédictions et les résidus du modèle dans notre tableau de données pour faciliter notre travail :
Maintenant, assurons-nous que les résidus sont homogènes à travers le gradient de prédictions. Autrement dit, vérifions que notre modèle se trompe à peu près de la même façon avec les petites valeurs et les grandes valeurs :
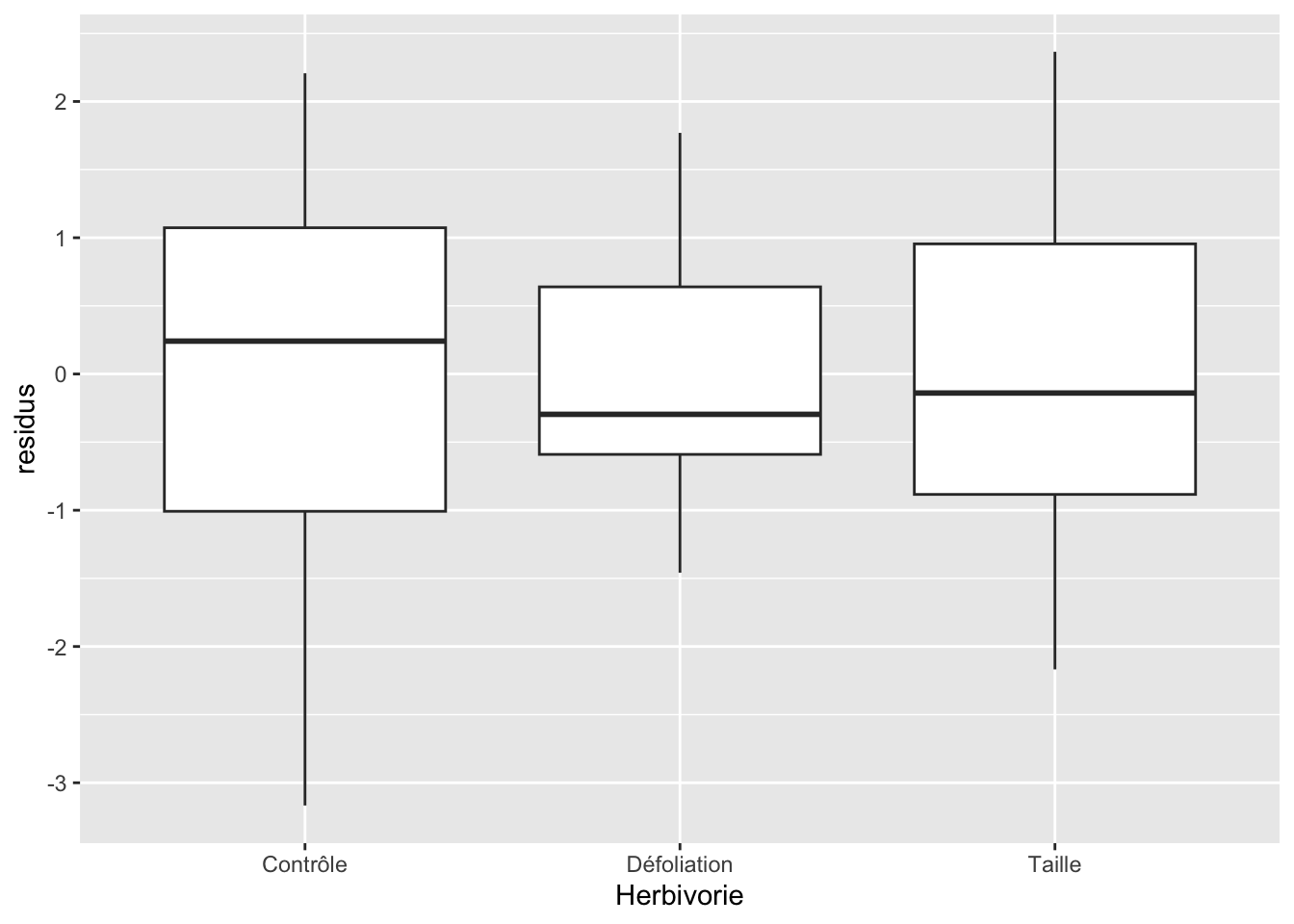
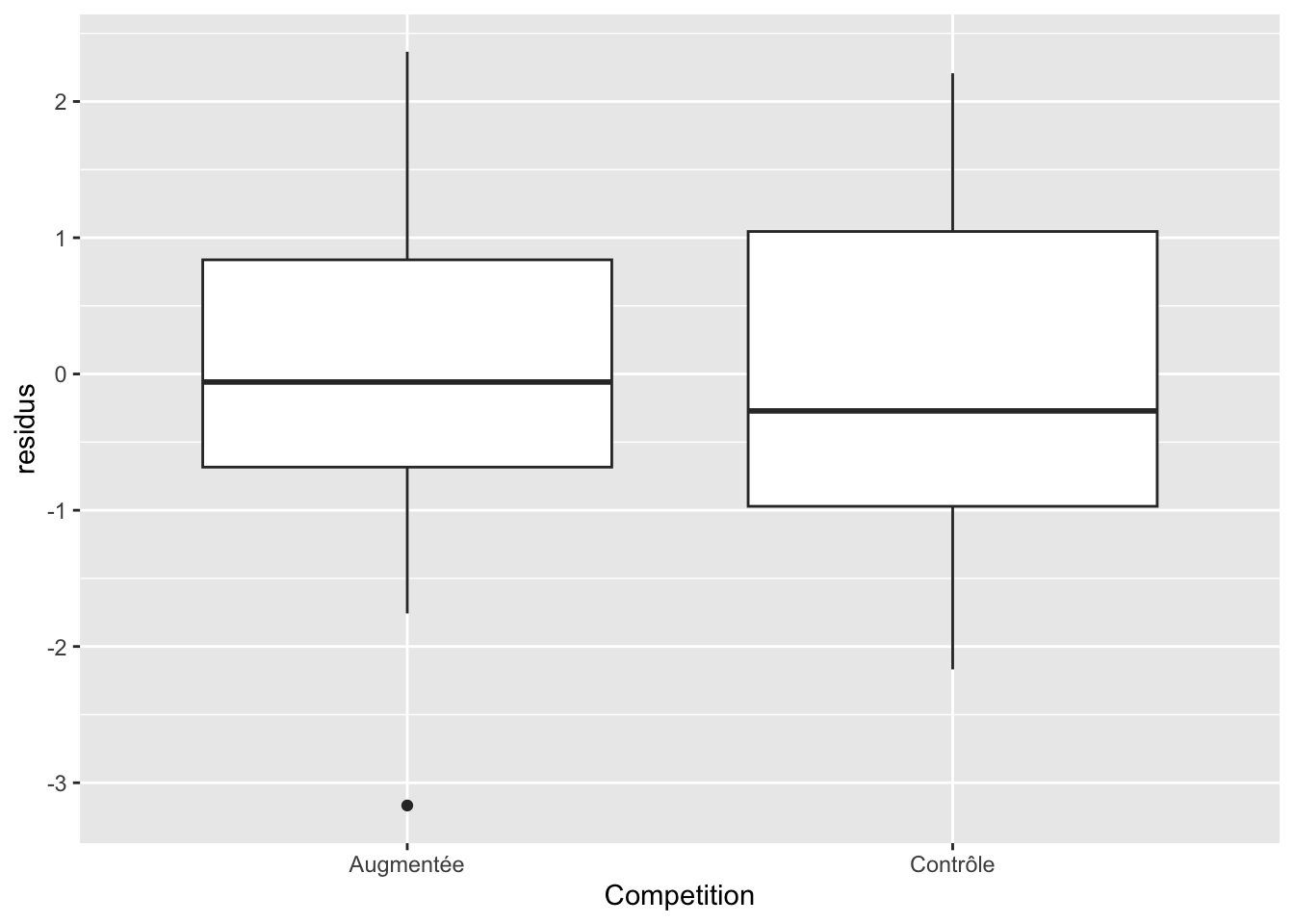
Enfin, il faut aussi vérifier que les erreurs sont équivalentes entre chacun des niveaux de nos variables catégoriques. On peut entrevoir cette information dans le graphique précédent, mais avec une boîte de diagramme à moustache par catégorie, c’est souvent plus facile :
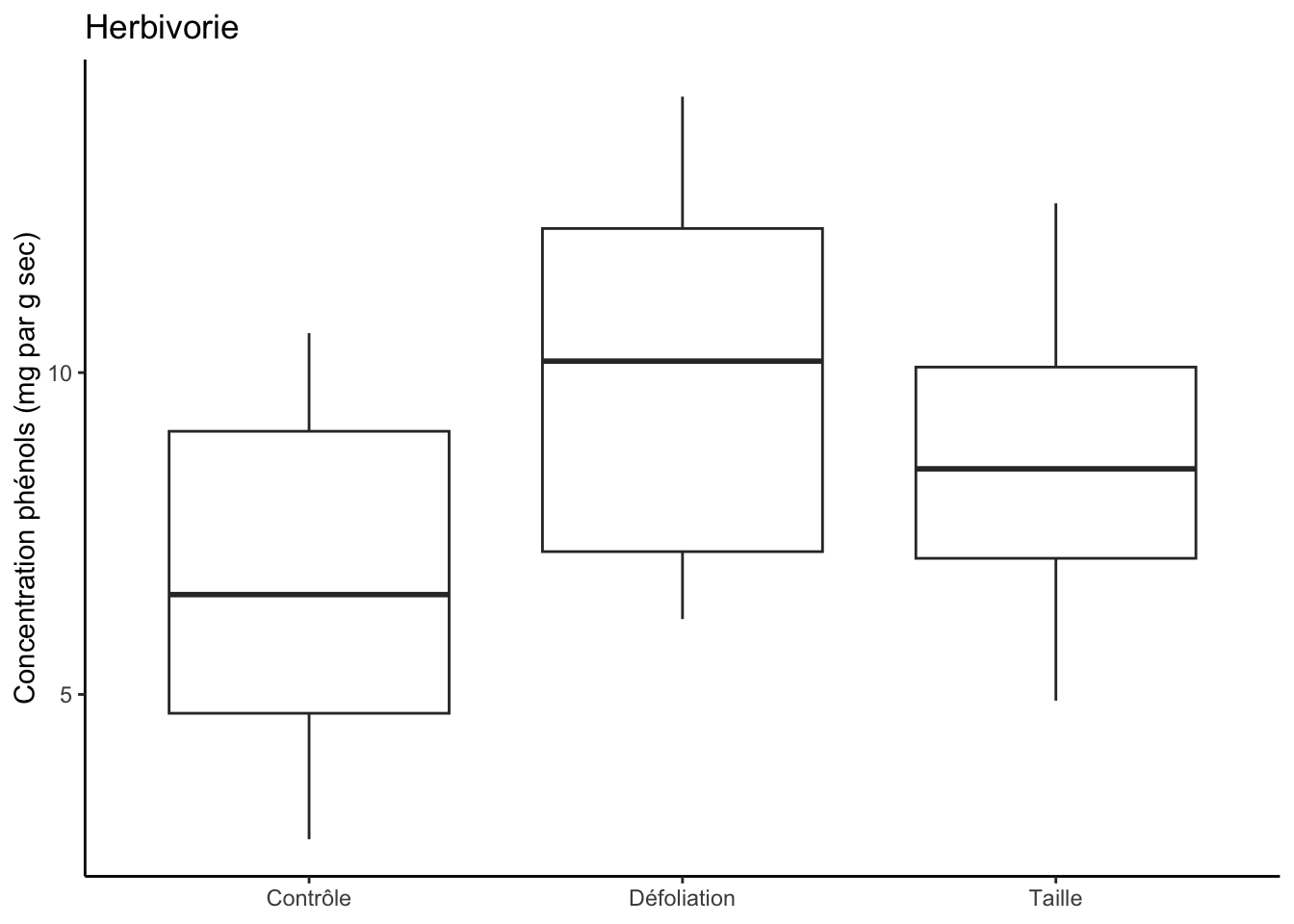
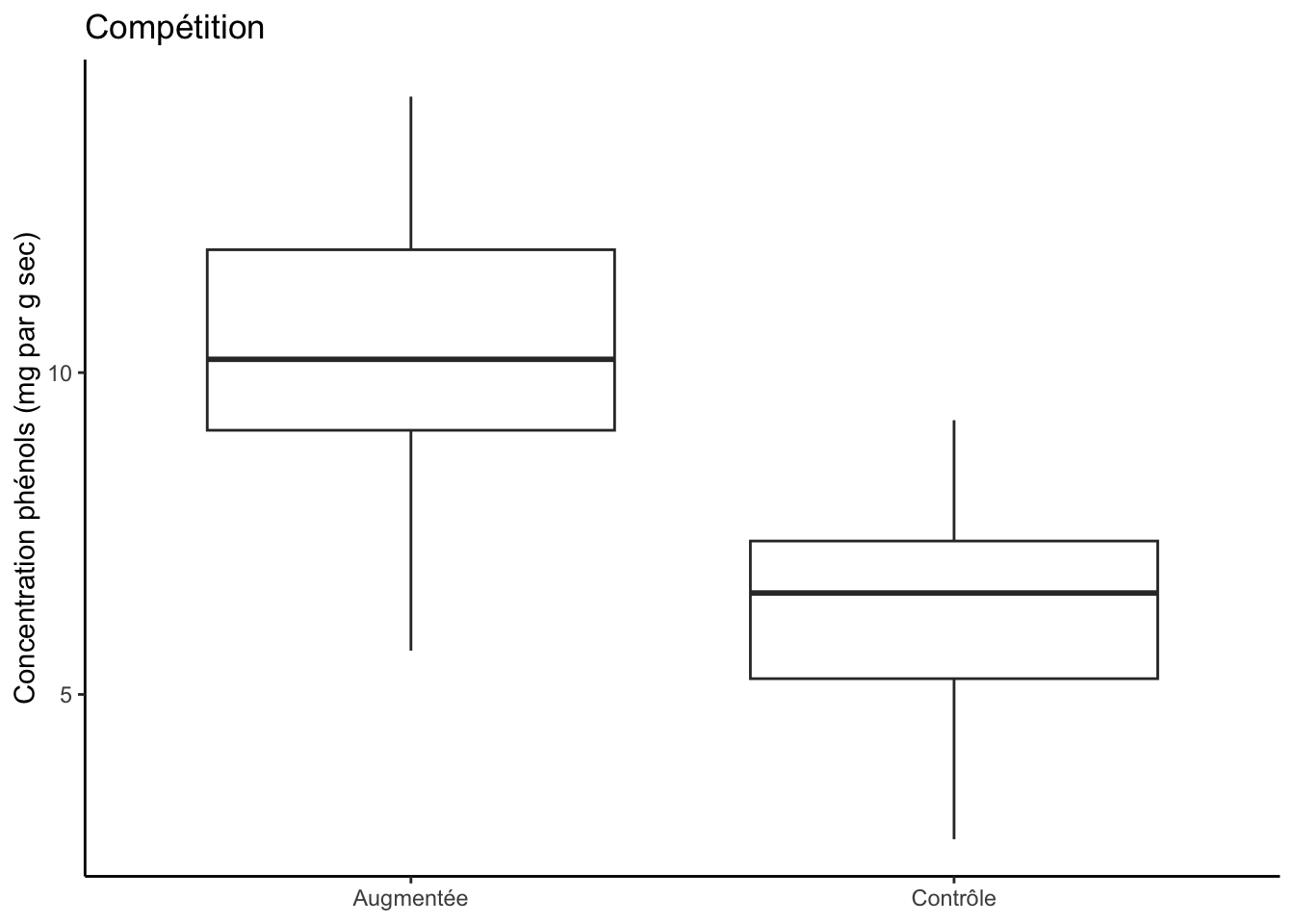
On voit dans ces sorties que notre variable d’herbivorie a un effet significatif (p<0,05). Notre variable de compétition a aussi un effet significatif (p<0,05). Mais que l’interaction entre les deux variables, elle, n’est pas significative. Autrement dit, l’effet de la compétition est le même, peu importe le niveau d’herbivorie et vice-versa, l’effet de l’herbivorie est le même, peu importe la quantité de compétition.
Si on voulait présenter ces résultats dans un rapport, on pourrait probablement le faire à l’aide de deux diagrammes à moustache, comme ceci :
ggplot(two_way, aes(Herbivorie, Concentration_Phenols)) +geom_boxplot() +theme_classic() +labs(x =NULL, y ="Concentration phénols (mg par g sec)", title ="Herbivorie")
ggplot(two_way, aes(Competition, Concentration_Phenols)) +geom_boxplot() +theme_classic() +labs(x =NULL, y ="Concentration phénols (mg par g sec)", title ="Compétition")
16.9 Comparaison des différentes ANOVA
Voici maintenant un petit résumé des avantages et inconvénients des différents types d’ANOVA. Pensez à relire ce résumé avant de démarrer une expérience, afin de choisir la bonne structure, qui maximisera vos chances de détecter l’effet désiré.
ANOVA à un facteur
Design le plus simple, mais aussi le plus puissant, car il n’y a pas de gaspillage en pseudo-réplication
Peut s’accommoder de tailles d’échantillons inégales entre les groupes
Ne tient pas compte de l’hétérogénéité (de l’environnement ou des individus)
Donc si on a beaucoup de bruit ou de facteurs confondants, on aura moins de puissance statistique
ANOVA en blocs aléatoires
Façon efficace de tenir compte de l’hétérogénéité
Utile lorsqu’on est contraint par l’espace ou le temps, p. ex. en considérant chaque site comme un bloc.
Il y a un coût statistique inutile si la variabilité inter-bloc est faible
Si on perd un des échantillon dans le bloc, le bloc entier doit être éliminé de l’analyse
Assume qu’il n’y a pas d’interaction entre les traitements et les blocs (i.e. que l’effet du traitement et le même dans tous les blocs).
ANOVA imbriquée
Avantage principal : augmente la précision de la réponse de chacun des échantillons; donc on devrait en principe augmenter la puissance du test
Permet de tester deux hypothèses : la variation entre les traitements et la variation entre les échantillons dans un traitement
Potentiellement dangereux car souvent analysée de façon incorrecte
Souvent, l’effort de sous-échantillonner est gaspillé par rapport au gain qui aurait été fait en ajoutant des échantillons indépendants.
ANOVA à deux facteurs croisés
Comme combiner deux expériences dans une seule
Utilisation plus efficace du temps et de l’espace
Toutes les combinaisons de traitements doivent apparaître dans le design de l’expérience
Permet de séparer les effets simples des interactions
Désavantage principal : le nombre de combinaisons peut augmenter rapidement, affectant le nombre d’échantillons qu’il est nécessaire de traiter.
Ce design ne tient pas compte non plus de l’hétérogénéité
16.10 Exercice : L’analyse de variance à plusieurs facteurs
Pour cet exercice, téléchargez d’abord le tableau de données Grillons.csv3. Ce tableau contient le résultat d’une expérience visant à déterminer si la réponse immunitaire des mâles grillons diffère de celle des femelles. La réponse immunitaire est mesurée par un score d’encapsulation. Plus ce score est élevé, plus la réponse immunitaire est forte. L’expérience a été effectuée sur 10 grillons mâles et 10 grillons femelles. Pour chaque individu, la réponse immunitaire a été mesurée à trois reprises.
Votre travail consiste donc à :
Charger, inspecter et préparer les données
Déterminer quelle sera l’ANOVA appropriée pour analyser ce jeu de données