Nous avons vu dans les chapitres précédents une série de tests statistiques. Vous avez sans doute remarqué qu’une assomption importante revenait sans cesse : que les échantillons proviennent d’une distribution normale. Nous avons vu que pour la plupart des tests, cette assomption pouvait être étirée un peu, en particulier en présence de grands échantillons. Nos données n’avaient jamais besoin d’être parfaitement normales. Mais que peut-on faire lorsqu’elles ne le sont clairement pas? Il existe deux stratégies possibles : soit utiliser des transformations pour normaliser nos données (Chapitre 9), soit d’utiliser des tests non-paramétriques. Nous verrons dans ce chapitre la deuxième stratégie, soit d’utiliser des tests différents, qui n’assument pas la normalité.
Notez bien que tous les tests non-paramétriques assument tout de même l’indépendance des observations. Ce ne sont pas les bons outils à utiliser si jamais c’est cette assomption en particulier que vos données ne respectent pas.
21.2 Perte de puissance
Vous vous demandez peut-être à ce point pourquoi on se casserait la tête avec des tests paramétriques quand les non-paramétriques sont disponibles? La raison est que les tests non-paramétriques sont, en général, moins puissants que leur équivalent paramétrique.
On peut dire de façon générale, que les tests non-paramétriques présentent 95 % de l’efficacité des tests paramétriques (p. ex. Hodges et Lehmann 1956). Ce qui signifie qu’un test non-paramétrique avec un n de 100 serait aussi puissant (aurait tant de chances de détecter une différence significative) qu’un test paramétrique équivalent avec un n de 95. Autrement dit, faire un test non-paramétrique équivaut à gaspiller 5 % de vos échantillons.
La corrélation de Spearman a 91 % de la puissance de celle de Pearson (Kruskal 1958). À l’extrême, le test de signe (signed test), que l’on ne verra pas ici, a 63 % seulement de la puissance de son équivalent paramétrique (Brown et al. 1992).
Astuce
Donc, si vous voulez valoriser vos données au maximum, utilisez les tests paramétriques chaque fois que c’est possible!
21.3 Test de Wilcoxon (remplacement du test de T)
Le premier test non-paramétrique que nous verrons est celui de Wilcoxon (Wilcoxon Rank-Sum Test). Il s’utilise en remplacement du test de T pour deux échantillons. L’application du test est d’ailleurs très semblable, à quelques changements près, que nous verrons ci-dessous.
Le test de Wilcoxon compare l’entièreté des distributions, plutôt que de se concentrer sur un ou deux paramètres comme la moyenne et l’écart-type. Ceci étant dit, si les deux échantillons ont des distributions de formes identiques (tendance centrale variabilité), le test se transforme en un test des médianes entre les deux échantillons.
L’hypothèse nulle du test étant que les deux distributions sont identiques, et l’alternative étant que les deux distributions sont différentes, dans leur ensemble.
L’exploration visuelle des données est la même que le test de T, soit à l’aide d’un diagramme à moustaches. Remarquez qu’ici les diagrammes à moustaches sont encore plus appropriés que pour les tests de T, puisqu’on y voit directement (1) la forme complète de la distribution et (2) la médiane de chacun des groupes.
La statistique de test, elle, est complètement différente du test de T. Elle est basée sur le rang des observations plutôt que sur leur valeur comme tel. Il s’agit d’une stratégie commune des tests non-paramétriques, que l’on reverra dans le test de Kruskal-Wallis et dans la corrélation de Spearman.
Pour illustrer ce principe, imaginons que nous avons fait une mini-expérience, où nous avons mesuré le nombre d’alevins dans 2 aquariums où nous avons ajouté un mécanisme d’oxygénation et 3 aquariums où nous n’avions pas ce mécanisme. Nos données sont les suivantes :
Avec oxygénation : 43 et 32 alevins
Sans oxygénation : 41, 35 et 44 alevins
Si on trie nos observations, leurs rangs seront respectivement :
Avec oxygénation : 4, 1
Sans oxygénation: 3, 2, 5
Le calcul se base ensuite sur la somme des rangs de chacun des échantillons et la taille de l’échantillon pour calculer une statistique nommée W (plutôt que T ou F par exemple). Si jamais vous grattez un peu dans ces calculs, vous verrez qu’en fait, il existe deux calculs différents selon la taille de l’échantillon. R fera toujours pour vous la bonne version des calculs, vous n’aurez pas à vous inquiéter de ce détail.
Il faut ensuite, comme pour les autres tests, aller chercher la valeur de p associée à cette valeur de W et aux degrés de liberté et déterminer si une telle différence est rare ou non quand l’hypothèse nulle est vraie.
21.4 Labo : Le test de Wilcoxon
Nous reprenons pour ce test la même question que pour le test de T à deux échantillons, à savoir : est-ce que la longueur des ailes des machots Adélie varie entre l’île Torgersen et l’île Biscoe.
Étape 0 :
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
H0 : La médiane de la longueur des ailes de l’île Torgersen est égale à celle de l’île Biscoe.
H1 : La médiane de la longueur des ailes de l’île Torgersen est différente de celle de l’île Biscoe.
Remarquez que ces hypothèses sont conditionelles à ce que le reste des distributions soient identiques…
Étape 2 :
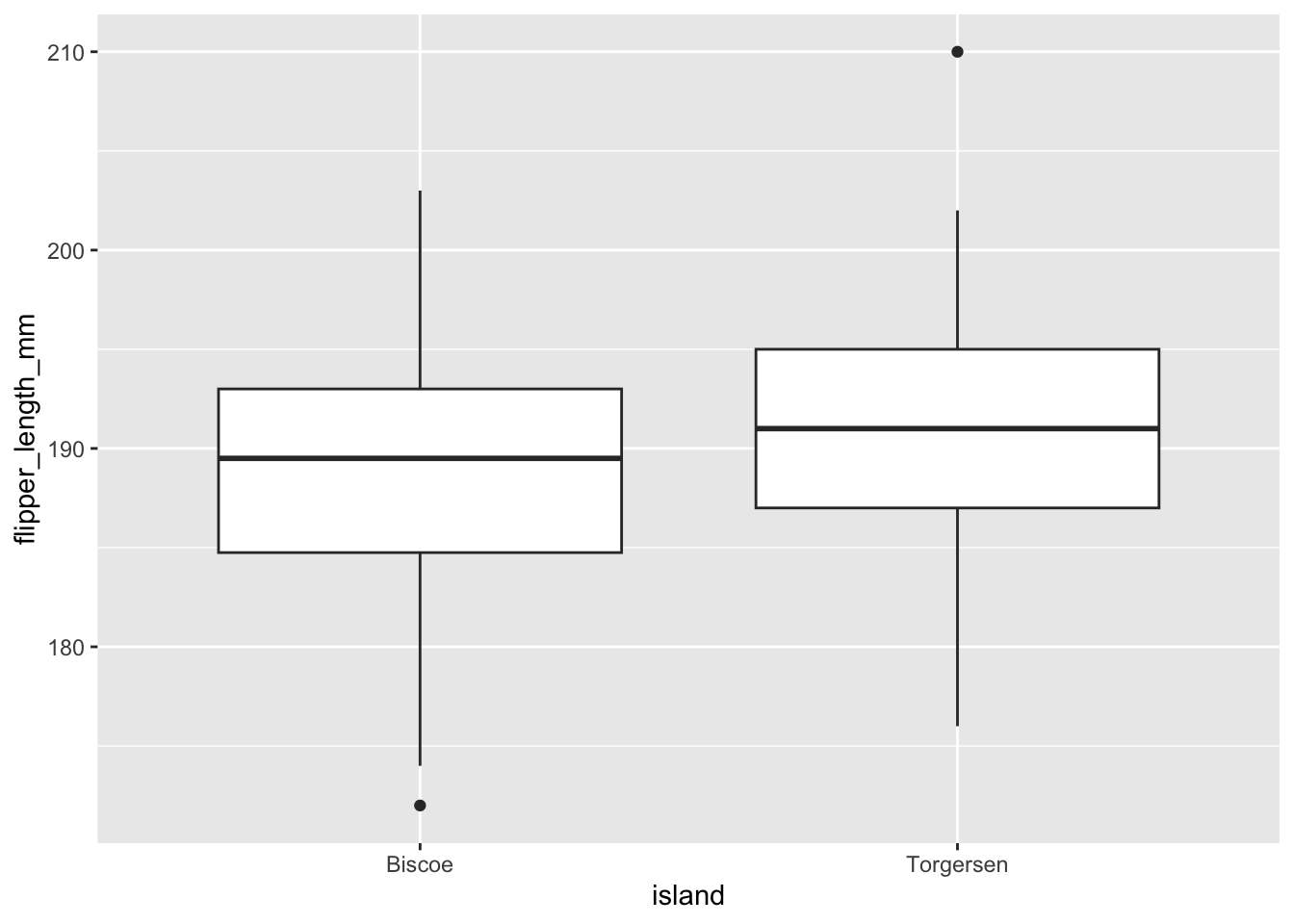
Bien que nous n’ayons pas d’assomption de normalité à vérifier, il est tout de même important de visualiser nos données, car le test explore l’ensemble des différences, et se réduit à un test de médianes uniquement si les distributions sont identiques.
adelie |>ggplot(aes(x = island, y = flipper_length_mm)) +geom_boxplot()
À l’oeil, les manchots de l’île Biscoe ont des ailes légèrement plus courtes que sur l’île Torgersen, mais peut-être pas sufisamment différentes pour qu’on soit certains que cette différence n’est pas zéro.
Étapes 3 et 4 :
La fonction pour effectuer le test de Wilcoxon se nomme wilcox.test, et s’utilise comme celle du test de T :
Wilcoxon rank sum test with continuity
correction
data: torgersen$flipper_length_mm and biscoe$flipper_length_mm
W = 1341, p-value = 0.1023
alternative hypothesis: true location shift is not equal to 0
Étape 5 :
Comme notre valeur de p est > 0,05, on ne peut pas rejeter l’hypothèse nulle d’aucune différence de médiane entre nos deux groupes.
Remarquez que (comme prévu), cette valeur de p est plus grande (moins proche du seuil de signification; 0,1023) que celle du test de T à deux échantillons (0.07444) pour les mêmes données, puisque le test de Wilcoxon a moins de puissance.
Étape 6 :
Le test de Wilcoxon par défaut dans R ne nous fournit pas d’intervalle de confiance associée à nos résultats. Nous devons activer manuellement cette option :
Wilcoxon rank sum test with continuity
correction
data: torgersen$flipper_length_mm and biscoe$flipper_length_mm
W = 1341, p-value = 0.1023
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
-1.973526e-05 4.999983e+00
sample estimates:
difference in location
2.000049
Comme expliqué dans l’aide de la fonction wilcox.test, cet intervalle de confiance est un peu contre-intuitif. L’intervalle de confiance ne nous informe pas sur la différence entre les médianes, mais plutôt sur la médiane des différences. Une fois cela dit, ça ne change pas grand chose sur notre interprétation dans la vraie vie, mais c’est quand même bon à savoir.
Nous pourrions donc écrire nos résultats comme ceci : « Il n’y a pas de différence significative de longueur d’aile entre les îles de Torgersen et Biscoe (W = 1341, p = 0,102). L’intervalle de confiance à 95 % de la différence entre les deux groupes allait de -1,97x10-5 mm à 4,999 mm»
21.5 Kruskal-Wallis (remplacement de l’ANOVA)
Si jamais votre question vous demandait de tester simultanément plus de deux groupes et que vous ne respectiez clairement pas l’assomption de normalité de l’ANOVA, vous pouvez toujours vous rabattre sur le test de Kruskal-Wallis. Ce test, comme celui de Wilcoxon, se base sur le rang de vos observations et compare l’entièreté des distributions. Si les distributions ont la même forme, il se réduit alors à un test de comparaison de médianes.
Comme pour le test de Wilcoxon, le test de Kruskal-Wallis utilise la somme des rangs de chacun des groupes dans un calcul un peu compliqué pour trouver la statistique de test. Les statisticiens ont ensuite déterminé que, lorsque toutes les populations avaient la même distribution (l’hypothèse nulle…), cette statistique suivrait une distribution de khi-carré. C’est donc dans cette distribution que la fonction associée au test ira déterminer la valeur de p associée.
Nous n’irons pas plus dans les détails de ce test, car dans la vraie vie, vous aurez rarement à l’utiliser. Il sera souvent plus utile et productif de transformer vos données pour les conformer aux exigences de l’ANOVA (voir Chapitre 9).
21.6 Labo : Le test de Kruskal-Wallis
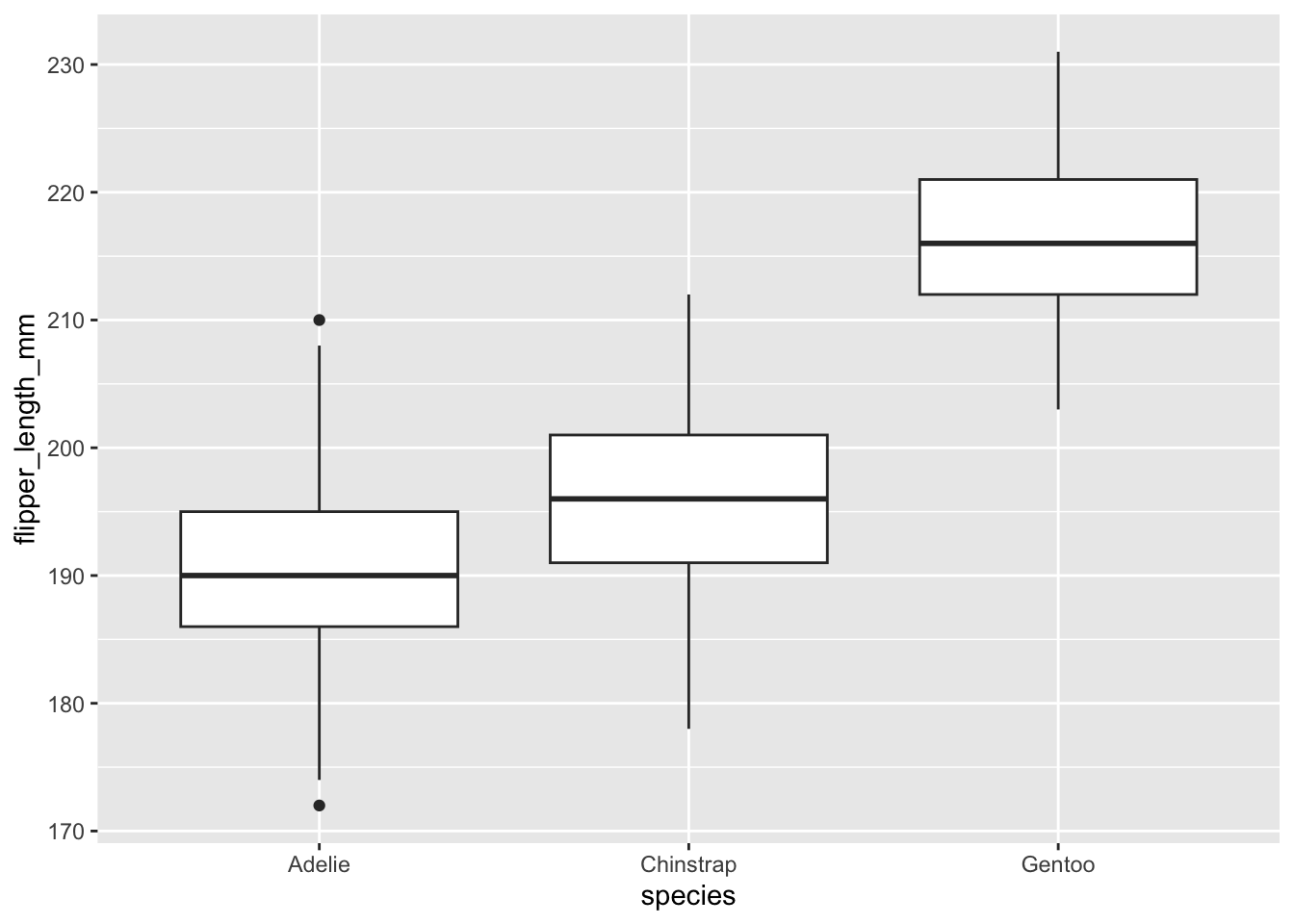
Nous reprendrons pour ce laboratoire la même question que celle abordée au Chapitre 15, soit de savoir si la longueur des ailes varie entre les 3 espèces de manchots de l’archipel Palmer.
kruskal.test(flipper_length_mm ~ species, data = pour_anova)
Kruskal-Wallis rank sum test
data: flipper_length_mm by species
Kruskal-Wallis chi-squared = 244.89, df = 2,
p-value < 2.2e-16
Étape 5 :
Comme la valeur de p est fortement sous 0,05, on peut rejeter l’hypothèse nulle d’aucune différence entre les médianes.
Étape 6 :
Ce test, comme l’ANOVA, ne fournit pas directement d’intervalle de confiance associé. On pourrait rapporter nos résultats comme ceci :
«Les espèces de manchots de l’archipel Palmer avaient des ailes de taille significativement différentes (Ꭓ22=244,89, p<2,2x10-16).»
Comme le test de Tukey HSD est basé lui aussi sur une distribution normale de nos données, il n’aurait pas pu être appliqué ici (si notre test de Kruskal-Wallis avait été significatif…). Par contre, nous aurions pu appliquer une série de tests de Wilcoxon en appliquant la correction de Bonferroni à l’interprétation des valeurs de p.
21.7 Corrélation de Spearman
Si jamais vous aviez eu besoin de calculer une corrélation entre deux variables, mais qu’une (ou les deux) ne respecte pas suffisamment les assomptions de la corrélation de Pearson, vous pourriez appliquer à la place la corrélation de Spearman. Cette dernière se calcule exactement comme la corrélation de Pearson, à la nuance que (vous l’aurez peut-être deviné) on remplace chacune des valeurs par son rang avant le calcul.
Dans R, la corrélation de Spearman se calcule comme ceci :
La valeur, comme celle de la corrélation de Pearson, va de -1 à +1 et s’interprète exactement de la même façon. Elle mesure le lien (pas nécessairement linéaire cette fois) entre deux variables. Comme pour la corrélation de Pearson, elle n’implique pas nécessairement de lien de cause à effet.
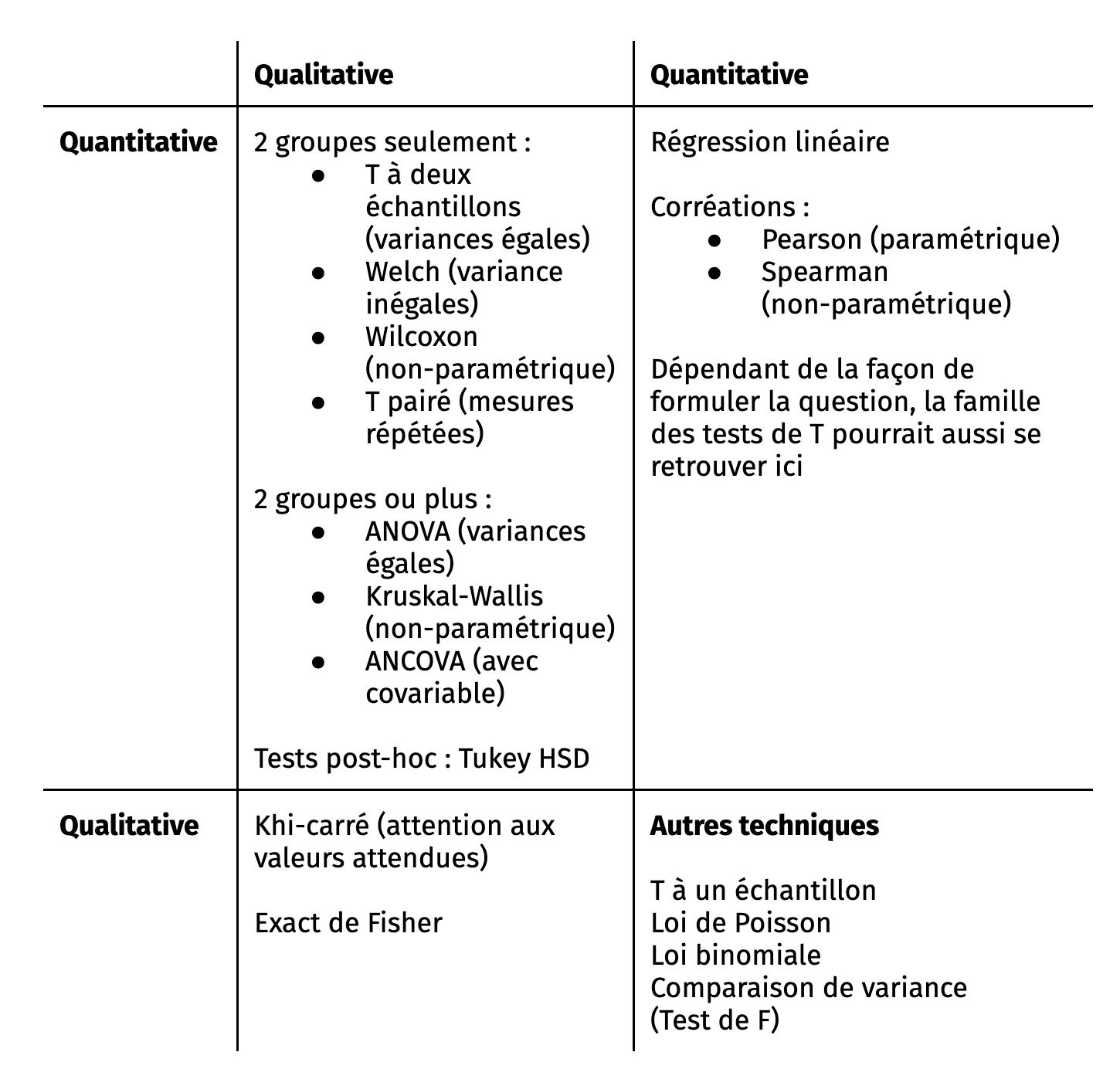
21.8 Tableau synthèse
Voici, pour terminer la section, voici un résumé de toutes les techniques que nous avons vues, organisées par le type de variable étudié
21.9 Exercices : La boîte à outils
Outre le fait d’être capable d’appliquer chacun des tests statistiques vus dans ce livre, une autre compétence importante à acquérir en tant que biologiste est de savoir quel test appliquer dans quelle situation.
Pierre Magnan, à l’époque, parlait de bien connaître sa “boîte à outils”. Je vais donc perpétuer cette tradition en vous proposant une série de mises en situations, pour lesquelles je vous demanderai non pas d’appliquer un test, mais uniquement de nommer quel test ou outil aurait été le plus approprié pour la situation. Bien que je n’ai jamais passé ces évaluations, à l’époque on nous disait que les examens de classement pour entrer aux différents ministères comportaient plusieurs questions de ce genre. Donc il vaut la peine d’être prêt!
À moins d’avis contraire, vous pouvez assumer la normalité des données et l’indépendance des observations. Si plusieurs tests pourraient faire l’affaire, choisissez celui offrant le plus de puissance statistique pour la situation. Si vous n’avez pas d’information concernant les variances, assumez qu’elles sont homogènes entre les groupes.
1. Vous avez mesuré la concentration de chlorophylle dans des feuilles d’érable rouge cueillies en sous-bois et en milieu ouvert. Vous voulez répondre à la question : est-ce que l’érable rouge augmente sa production de chlorophylle dans les milieux mieux éclairés.
2. Vous avez capturé et marqué les écureuils gris dans des milieux urbains et agricoles. Vous voulez savoir si la densité d’écureuil diffère de façon significative entre ces deux milieux. Une analyse préliminaire vous indique que la variance de la densité ne serait pas homogène entre les deux milieux.
3. Vous savez qu’en moyenne, on récolte 3,5 œufs par nid d’oiseaux. Sachant que ces données représentent des décomptes et que la variance associée à la récolte est aussi d’environ 3,5 œufs, quelle est la probabilité de ne récolter aucun œuf dans un nid?
4. Un agriculteur vous affirme qu’il n’a pas appliqué de pesticides sur sa bande riveraine. Vous savez qu’en moyenne, une bande riveraine contient 12 insectes nuisibles par mètre carré de terrain. Vous avez évalué le nombre d’insectes dans une série de parcelles sur sa bande riveraine et êtes arrivés aux chiffres suivants : [8,5,15,12,14,9,10,6]. Cet agriculteur a-t-il appliqué des pesticides sur sa bande riveraine?
5. Vous avez été mandatée pour évaluer la survie des perchaudes à l’hiver sous la glace du lac Saint-Pierre. Votre première piste est d’évaluer si les perchaudes parviennent à maintenir leur poids pendant l’hiver. Vous avez donc capturé à l’automne 50 perchaudes, que vous avez pesées et marquées. Au printemps, à l’aide des puces installées, vous en retrouvez 5 que vous pesez à nouveau.
Voici le poids des perchaudes à l’automne : [1108, 1200, 1004, 801, 1500] grammes
Et celui à l’hiver, dans le même ordre [1102, 1230, 906, 765, 1200] grammes
Évaluez si ces perchaudes ont subi une perte significative de poids durant l’hiver.
6. Vous voulez tester une théorie selon laquelle les contraintes climatiques limitent le développement physiologique des insectes. Vous avez capturé une série de papillons en toundra et en milieu tropical et vous devez maintenant évaluer si ces mesures sont plus variables en milieu tropical qu’en toundra.
7. Vous savez, par les informations fournies par le fabricant, que 3 % de vos colliers émetteurs cesseront de fonctionner pendant une saison de terrain. Combien de colliers devrez vous installer si vous voulez être certain à 95 % de récolter l’information provenant de 15 colliers au terme de la saison?
8. Vous savez qu’en moyenne, une espèce de serpent produit 8,2 petits par portée. Sachant que ces données représentent des décomptes et que la variance associée au nombre de petits est aussi d’environ 8,2 petits, quelle est la probabilité qu’une portée produise 2 petits ou moins?
9. Vous savez qu’en moyenne seulement 30 % des oiseaux survivent à leur première migration. Si vous marquez 60 oiseaux à l’automne, quelle est la probabilité d’en retrouver 25 vivants ou plus l’année suivante?
10. Vous avez mesuré le nombre d’écureuils roux dans des parcelles de conifères et des parcelles de feuillus. Vous voulez répondre à la question : est-ce que l’écureuil roux est présent en plus grande densité dans les parcelles de conifères.
11. Vous avez mesuré les taux de mercure et le poids d’une série de poissons. Vous devez maintenant déterminer si une règle simple permettrait de savoir quel taux de mercure on peut s’attendre à retrouver en moyenne dans la chair d’un poisson d’un poids donné.
12. Vous avez été mandatée pour évaluer si les efforts de réhabilitation d’anciens stationnement portent fruit pour toute la biodiversité urbaine. Vous avez, pour chaque stationnement mesuré la richesse en espèces d’insectes avant la réhabilitation et avez ensuite revisité chacun des stationnements 4 ans plus tard pour prendre les mêmes mesures. Vous voulez maintenant savoir si la réhabilitation a effectivement favorisé la richesse en espèces d’insectes.
13. Vous avez mesuré les taux de mercure dans la chair d’une série de poissons. Vous avez noté pour chacun l’espèce à laquelle le poisson appartenait (perchaude, achigan, brochet, crapet), et vous voudriez maintenant déterminer si les taux de mercure varient en fonction de l’espèce.
14. Vous avez récolté des données permettant d’explorer la relation entre la richesse en espèce végétale et la productivité primaire. Vous voulez savoir si ces variables sont reliées, mais vous ne pouvez déterminer a priori d’hypothèses à savoir si la richesse augmente la productivité ou la productivité augmente la richesse.
15. Vous avez capturé et marqué les bruants chanteurs dans des milieux urbains et agricoles. Vous voulez savoir si la densité de bruants chanteurs diffère de façon significative entre ces deux milieux. Une analyse préliminaire vous indique que la variance de la densité ne serait pas homogène entre les deux milieux.
16. Vous avez mesuré la concentration de chlorophylle dans des feuilles d’érable rouge cueillies en sous-bois et en milieu ouvert et en milieu humide. Vous voulez répondre à la question : est-ce que l’érable rouge modifie sa production de chlorophylle en fonction du milieu. Cependant, vous savez aussi que la production de chlorophylle peut-être influencée par la taille des feuilles. Vous avez donc pour chaque feuille, mesuré sa surface, sa teneur en chlorophylle et le type de milieu dans lequel elle a été trouvée.
17. Vous avez capturé et marqué les bruants chanteurs dans des milieux urbains, agricoles et forestiers. Vous voulez savoir si la densité de bruants chanteurs diffère de façon significative entre ces trois milieux. Une analyse préliminaire vous indique que vos données ne suivent clairement pas une distribution normale.
18. Vous avez mesuré le nombre de sittelles à poitrine rousse dans des parcelles de conifères et des parcelles de feuillus. Vous voulez répondre à la question : est-ce que cette espèce de sittelle est présente en plus grande densité dans les parcelles de conifères. Cependant, en explorant vos données, vous remarquez qu’elles contiennent beaucoup plus de valeurs “0” que l’on pourrait s’attendre pour une distribution normale.
19. Vous avez noté, pour une série de parcelles, le nombre de frênes d’amérique et de frênes rouges. Certaines de vos parcelles étaient inondées, d’autres non. Vous voulez déterminer si le type de frêne trouvé est associé au fait que la parcelle soit inondée ou non. Les parcelles étaient particulièrement grandes, et donc le nombre de frênes attendus dans chaque parcelle était plutôt élevé, jamais sous les 20 individus.
20. Vous avez récolté des données permettant d’explorer la relation entre la richesse en espèce végétale et la richesse en espèces d’insectes. Vous voulez savoir si ces variables sont reliées, mais vous ne pouvez déterminer a priori d’hypothèses à savoir si les insectes augmentent les plantes (par pollinisation) ou l’inverse (par broutement). À première vue, vos données sont loin de suivre une distribution normale, puisque la richesse en espèces d’insectes était souvent de 0 ou 1.
21. Vous avez dénombré le nombre de plantes envahissantes et non-envahissantes dans des milieux urbains et naturels. Vous voulez maintenant déterminer si le type de milieu et la présence d’espèces envahissantes sont reliées. Comme il y avait très peu d’espèces envahissantes en milieu naturel, votre nombre d’individus attendus pour ce milieu est < 1.
Brown, B. M., T. P. Hettmansperger, J. Nyblom, et H. Oja. 1992. « On CertainBivariateSignTests and Medians ». Journal of the American Statistical Association 87 (417): 127‑35. https://doi.org/10.2307/2290460.
Hodges, J. L., et E. L. Lehmann. 1956. « The Efficiency of SomeNonparametricCompetitors of the $t$-Test ». The Annals of Mathematical Statistics 27 (2): 324‑35. https://www.jstor.org/stable/2236996.
Kruskal, William H. 1958. « Ordinal Measures of Association ». Journal of the American Statistical Association 53 (284): 814‑61. https://doi.org/10.2307/2281954.