Alors, nous y voici, le chapitre des notes de cours avec le titre le plus long et compliqué : le cadrage multidimensionnel non-métrique! Vous me pardonnerez, je l’espère, de ne pas utiliser le nom complet de cette technique chaque fois que nous y ferons référence. Nous utiliserons plutôt son acronyme anglais NMDS (nonmetric multidimensional scaling), puisque c’est par ce nom que tous les biologistes le connaissent.
Le NMDS, comme la PCoA, ne s’intéresse pas à la ressemblance entre les variables (covariance, corrélation), mais bien aux distances entre les observations. Par contre, contrairement à la PCoA, le NMDS ne se contente pas de pivoter le nuage de points en plusieurs dimensions. Elle peut aussi au besoin le déformer pour clarifier encore plus les gradients.
26.2 Terminologie
Il y a beaucoup de termes techniques dans le nom du NMDS, mais au final vous verrez que ce n’est pas si mal quand on prend le temps de les regarder un par un. Tout d’abord, qu’entend-on par non-métrique? Ce terme signifie, dans ce contexte, que le NMDS ne conserve pas nécessairement les distances exactes entre les observations. Non seulement il tourne le nuage de points (comme la PCoA), mais en plus, il peut changer la position individuelle de certains points dans le nuage pour que les observations similaires soient le plus près possibles les unes des autres et que les différentes soient plus éloignées. Évidemment, il ne déplace pas les observations n’importe comment. Dans tous les cas, le rang original des distances sera conservé. C’est à dire que la paire d’observations la plus semblable demeurera toujours la plus semblable, la paire d’observations la plus différente demeurera toujours la plus différente, etc. Cela fonctionne en fait, exactement comme les tests non-paramétriques (Spearman, Wilcoxon, etc), mais ici on est en plusieurs dimensions (i.e. multi-dimensionnel).
26.3 Fonctionnement
Contrairement à toutes les techniques statistiques que nous avons vues jusqu’à présent, le NMDS ne peut pas être décrit par une simple opération d’algèbre matriciel. Le NMDS s’effectue plutôt en suivant un algorithme, qui en une succession d’itérations, s’approche progressivement de la configuration optimale du nuage de points.
Voici un aperçu du processus suivi lors d’une analyse par NMDS :
Il faut, comme pour les autres analyses, préparer notre matrice de données, en s’assurant de fournir uniquement des colonnes contenant des chiffres.
Il aussi choisir combien de dimensions (i.e. d’axes; k) nous voulons obtenir dans le résultat du NMDS. Il s’agit d’une différence importante comparé à l’ACP et l’AFC. Nous y reviendrons plus loin.
R calcule pour nous ensuite la matrice de dissimilarités, basées sur le distance que nous avons choisie (voir Chapitre 22).
R choisit alors pour chacune de nos observations, une coordonnée aléatoire dans l’espace en k dimensions.
Les observations sont ensuite déplacées itérativement (e.g. une à la fois) de façon à ce que la distance entre les observations dans l’espace en k dimensions s’approche le plus près possible des vraies distances entre les observations (celles mesurées à l’étape 3)
La position des observations est jugée finale lorsque le déplacement des objets n’améliore plus la correspondance entre les distances en k-dimensions et les distances réelles
Cette façon de faire par algorithme itératif apporte une différence importante par rapport aux deux ordinations précédentes. Puisque la configuration de départ est aléatoire, il peut arriver que le NMDS n’arrive pas toujours à la même solution. Lorsque nous lancerons la fonction R, vous remarquerez donc qu’elle calcule 20 NMDS sur notre matrice de données et nous fournit ensuite le résultat du meilleur NMDS trouvé parmi les 20 essais.
L’autre différence majeure, comme suggéré dans l’algorithme, est que contrairement à la PCoA, on choisit d’avance combien on veut d’axes dans la solution finale (i.e. la valeur de k). Dans la PCoA (comme dans l’ACP), le calcul nous fournissait autant d’axes qu’il y avait de variables dans nos données originales. C’était à nous de choisir lesquels interpréter ensuite. Ici, on choisit d’avance combien on veut en recevoir.
Mais comment choisir la valeur de k? Il n’y a pas de réponse facile à cette question. Moins on a d’axes, et plus notre résultat sera facile à interpréter pour notre petit cerveau humain. Rappelez-vous comment pour l’ACP, il devenait difficile d’interpréter les axes 3 et 4. Par contre, si le nombre d’axes que l’on choisit est trop petit, la solution que le NMDS trouvera pourrait ne pas être représentative de la structure de nos données originales (e.g. elle pourrait l’avoir trop simplifiée, la rendant inutilisable).
Comment savoir si on a choisi une valeur de k trop petite? C’est là qu’entre en ligne de compte un nouveau concept : le stress. Le stress dans une NMDS sert à mesurer combien loin est la configuration trouvée par le NMDS par rapport à la configuration originale de nos points. Il se calcule comme une régression, où chacun des points sera une paire d’observations dans notre matrice de données. On mettra en X la distance originale entre les deux observations et en Y la distance calculée avec les axes du NMDS (rassurez-vous, R s’occupe de tout ça pour nous). Comme le NMDS est un cadrage multi-dimensionnel non-métrique, cette régression sera calculée sur les rangs des observations plutôt que sur les valeurs elles-mêmes. Enfin, le stress comme tel se trouve à être la moyenne des résidus de cette relation. Si la relation est bonne, le stress sera très faible. Au contraire, si les distances trouvées par le NMDS sont très différentes des originales, le stress sera élevé.
Comment savoir à quel moment le stress est trop élevé? Il n’y a, comme d’habitude, pas de réponse absolue à cette question. Voici ce qu’en disent habituellement les manuels de statistiques :
Une valeur de stress >= 0.3 nous indique que la configuration trouvée par le NMDS ne vaut pas grand chose. On aurait lancé les points au hasard et on aurait fait aussi bien que lui.
On dit que si la valeur de stress est >= 0,2, on ne devrait pas interpréter les sorties. Certaines sources mettent ce seuil à 0,15 plutôt que 0,2
Idéalement, le stress d’un NMDS devrait être < 0,1
Remarquez que ces guides d’interprétation assument que le calcul de stress utilisé est celui de Kruskal. Si jamais vous utilisez un autre logiciel que R, assurez-vous que le stress est bien calculé de la même façon avant d’utiliser ce tableau d’interprétation.
Une fois le concept de stress bien assimilé, le vrai compromis à comprendre lorsque l’on travaille avec un NMDS est qu’un modèle avec plus de dimensions (k plus grand) présentera un stress plus faible, mais sera aussi plus difficile à interpréter. Au contraire, un modèle avec moins de dimensions sera (k plus faible) sera facile à interpréter, mais présentera un stress plus élevé, pouvant aller jusqu’au point où on ne devrait pas interpréter les sorties du modèle.
26.4 Labo : Le NMDS
Pour essayer le NMDS dans la vraie vie, nous allons l’appliquer à la base de données oiseaux comme au Chapitre 24 et Chapitre 25, pour essayer de résumer les différences entre les sites (les lignes de notre base de données).
L’étape de préparation sera donc identique :
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
La fonction que nous utiliserons pour calculer le NMDS se nomme metaMDS et provient de la librairie vegan. Elle attend au minimum 3 arguments, soit la matrice de données sur laquelle faire le calcul, le type de distance à utiliser et le nombre d’axes que devra comporter notre solution. Comme notre matrice contient des décomptes d’espèces, nous allons utiliser la distance de Bray-Curtis (voir Chapitre 22 pour la justification), et nous allons commencer par demander deux axes :
resultat <-metaMDS(oiseaux,distance ="bray",k=2)
Vous voyez que R lance à ce moment une série de calculs de NMDS, et pour chacun, il nous fournit la valeur de stress trouvée :
Run 0 stress 0.08878298
Run 1 stress 0.07541769
... New best solution
... Procrustes: rmse 0.1109761 max resid 0.244984
Run 2 stress 0.1958539
Run 3 stress 0.1178968
Run 4 stress 0.1717245
Run 5 stress 0.07541769
... New best solution
... Procrustes: rmse 1.854749e-06 max resid 4.103491e-06
... Similar to previous best
Run 6 stress 0.07541769
... Procrustes: rmse 8.037654e-07 max resid 1.682034e-06
... Similar to previous best
Run 7 stress 0.1560246
Run 8 stress 0.07541769
... New best solution
... Procrustes: rmse 1.310091e-06 max resid 2.345469e-06
... Similar to previous best
Run 9 stress 0.1317843
Run 10 stress 0.2464662
Run 11 stress 0.07541769
... Procrustes: rmse 5.437188e-07 max resid 1.305125e-06
... Similar to previous best
Run 12 stress 0.07541769
... Procrustes: rmse 1.31098e-06 max resid 3.101059e-06
... Similar to previous best
Run 13 stress 0.08878298
Run 14 stress 0.1178968
Run 15 stress 0.08878298
Run 16 stress 0.08878298
Run 17 stress 0.1664907
Run 18 stress 0.08878298
Run 19 stress 0.1202882
Run 20 stress 0.1422574
*** Best solution repeated 3 times
Les chiffres sur vos ordis seront probablement différents des miens, puisque, rappelez-vous, la configuration de départ de chaque calcul de NMDS est choisie aléatoirement. La dernière ligne de la sortie nous informe que l’algorithme a trouvé la solution optimale après les 20 essais. Nous verrons plus loin comment ajouter des essais si jamais la solution n’est pas trouvée.
Voyons un peu le résumé de notre calcul de NMDS :
resultat
Call:
metaMDS(comm = oiseaux, distance = "bray", k = 2)
global Multidimensional Scaling using monoMDS
Data: oiseaux
Distance: bray
Dimensions: 2
Stress: 0.07541769
Stress type 1, weak ties
Best solution was repeated 3 times in 20 tries
The best solution was from try 8 (random start)
Scaling: centring, PC rotation, halfchange scaling
Species: expanded scores based on 'oiseaux'
La chose importante à voir dans cette sortie est surtout la valeur de stress, qui est de 0,075. Comme elle est < 0,1, on peut interpréter sans crainte les sorties de notre modèle.
Si on essaie la fonction plot avec notre objet de résultats, vous verrez que les sorties sont plus ou moins intéressantes :
plot(resultat)
Je ne sais pas où ils avaient la tête quand ils ont préparé cette fonction, mais clairement, on ne peut rien en tirer d’intéressant. La librairie vegan nous fournit par contre quelques fonctions permettant d’afficher le nom des espèces et des sites dans le graphique pour le rendre plus utile :
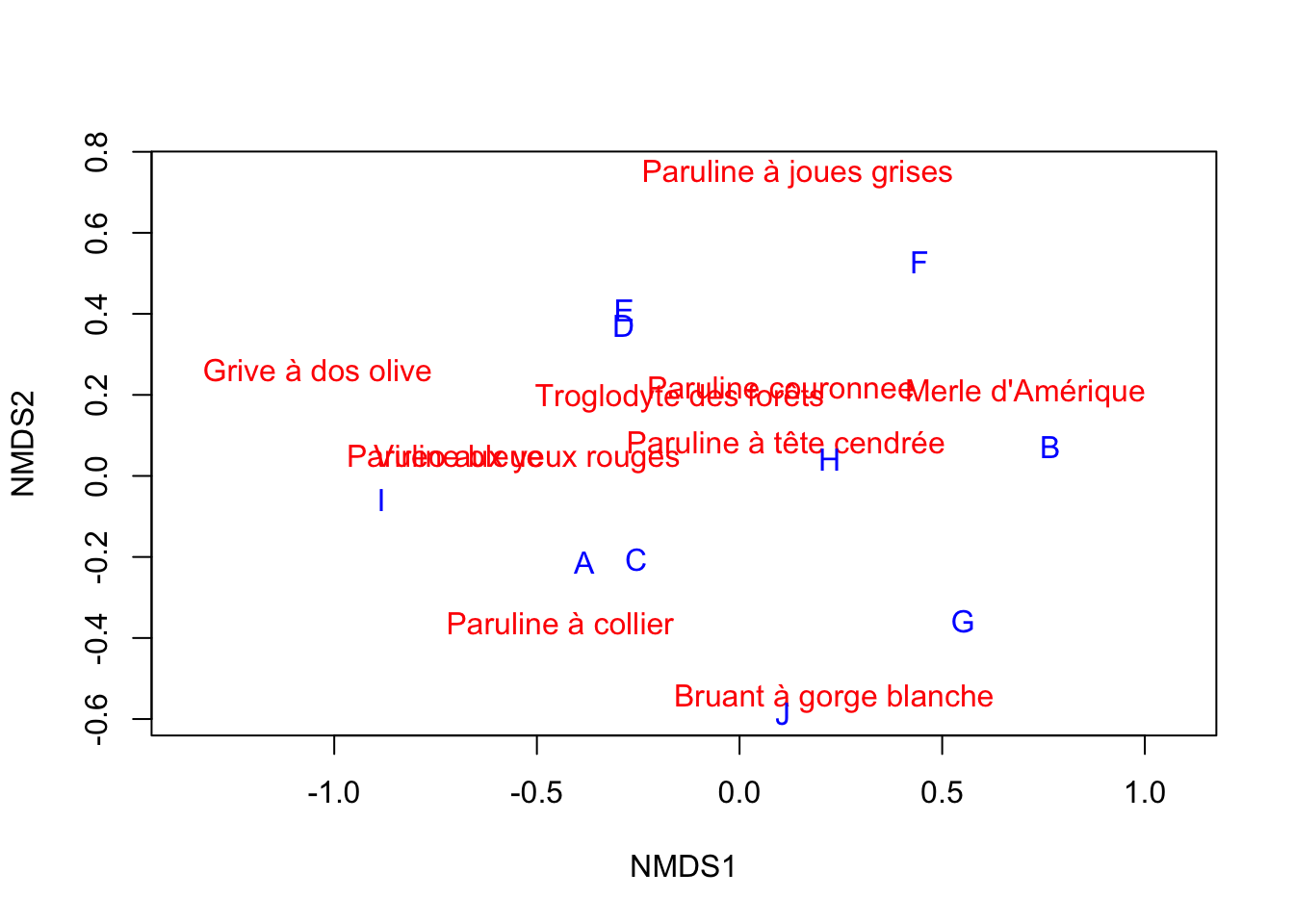
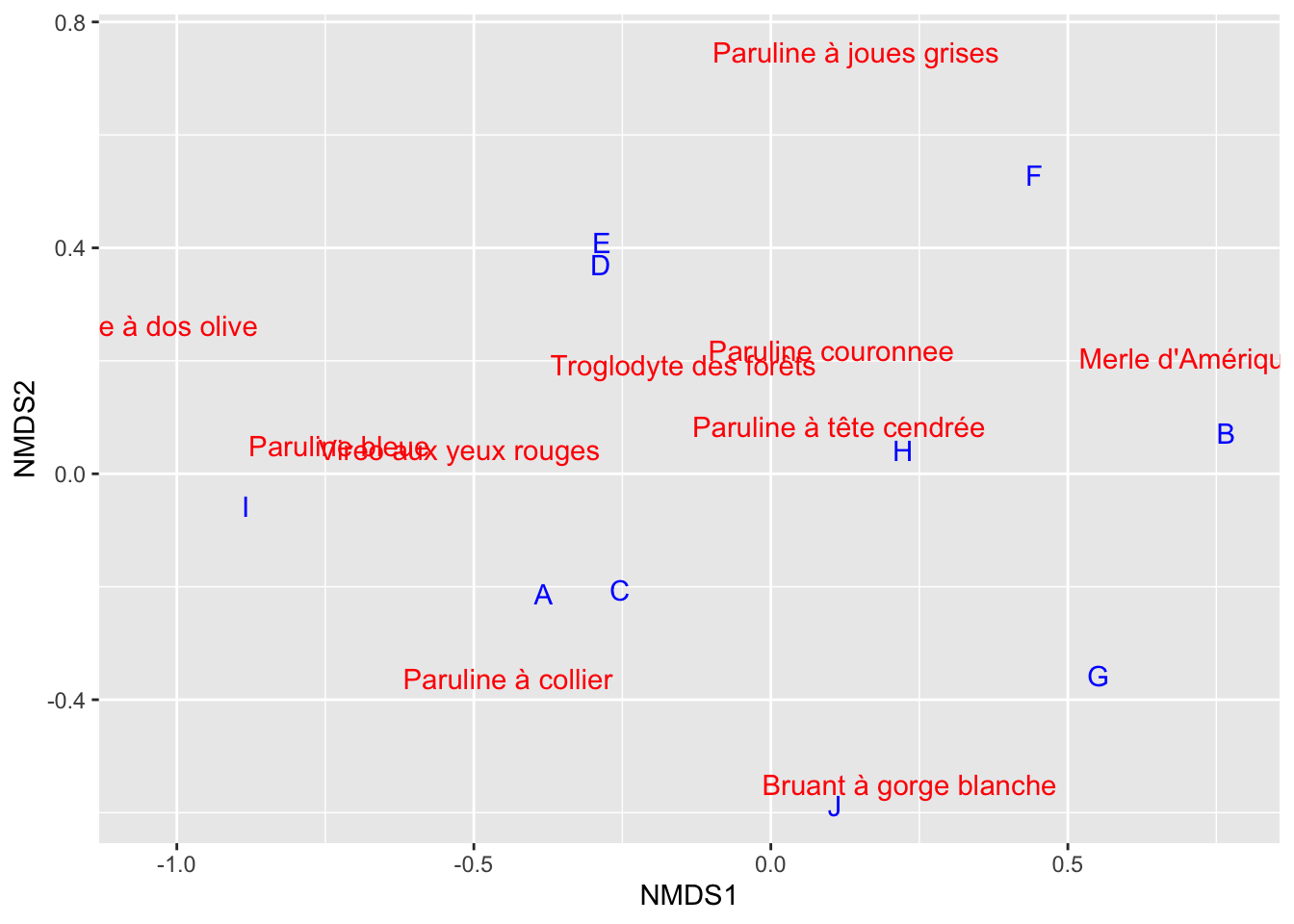
plot(resultat, type ="n")text(resultat, display ="species", col ="red")text(resultat, display ="sites", col ="blue")
Nous avons donc maintenant en bleu chacun des sites dans notre matrice de données, et on a affiché aussi les espèces, en rouge. Si jamais vous voudriez personnaliser davantage le graphique sortant du NMDS, sachez que la façon de faire avec ggplot2 et la PCA montrée au Chapitre 23 fonctionnera aussi avec le NMDS, pour autant que vous utilisiez les axes nommés NMDS1, NMDS2 et la fonction plot plutôt que biplot.
Aussi il est possible que le graphique sur votre ordinateur soit inversé par rapport au mien, avec le merle à gauche et la grive à droite. C’est tout à fait normal. Comme pour l’ACP, le sens des axes n’a pas d’importance dans l’absolu.
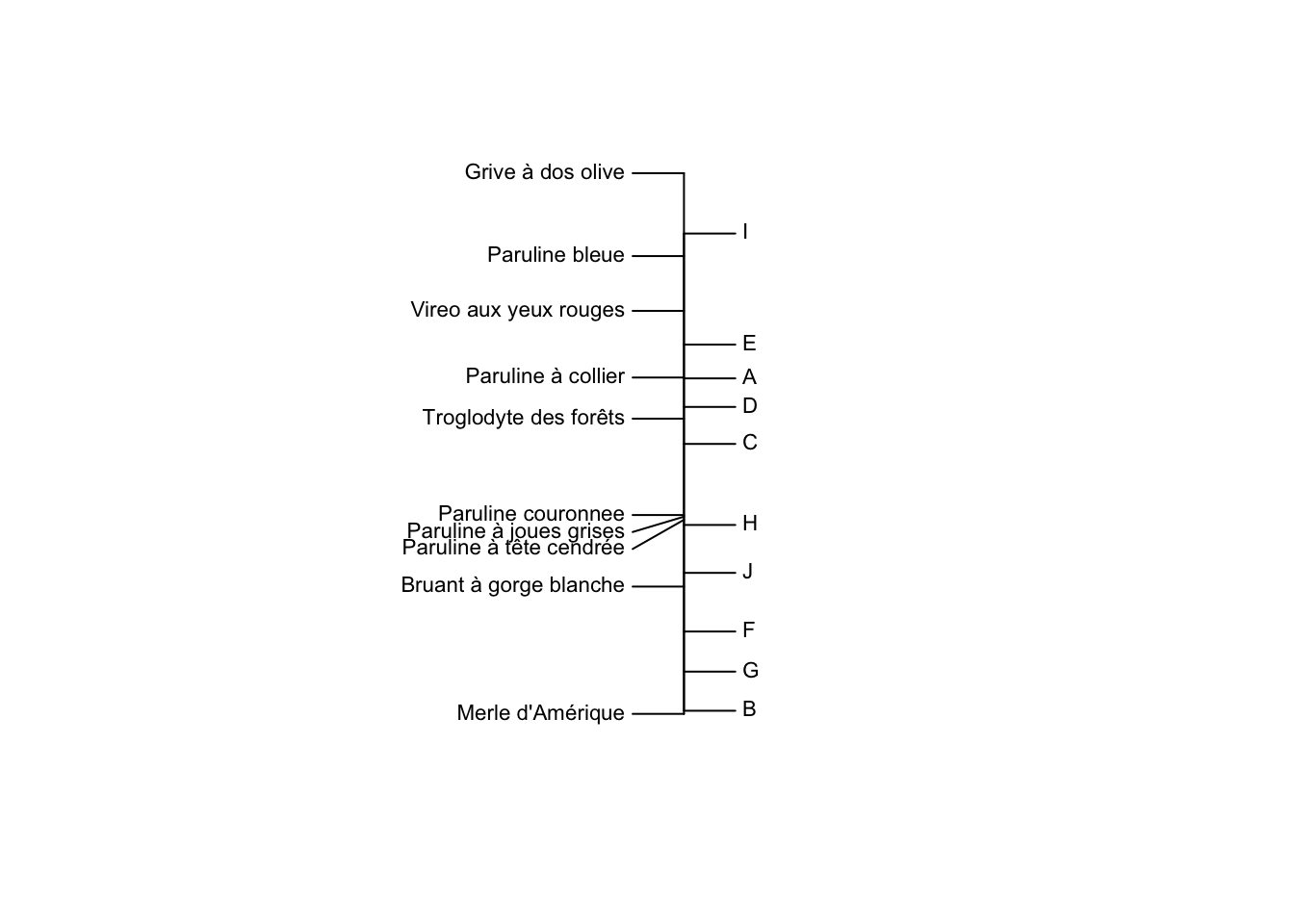
Les deux sites les plus différents dans nos communautés sont donc le B d’un côté et le I de l’autre. Comme pour l’AFC, les différences principales semblent être définies par une différence d’abondance avec beaucoup de Merles d’un côté, à des sites avec beaucoup des Grives de l’autre. Mais le gradient ici est encore plus clair.
Le deuxième axe quant à lui est défini par les sites F d’un côté et J de l’autre, et est surtout caractérisé par une différence d’abondance entre la Paruline à joues grises et le Bruant à gorge blanche.
Voyons maintenant ce qui arriverait si on avait choisi de produire un NMDS à un seul axe plutôt que deux :
Run 0 stress 0.2453025
Run 1 stress 0.2804428
Run 2 stress 0.5162195
Run 3 stress 0.4182913
Run 4 stress 0.4596998
Run 5 stress 0.3791019
Run 6 stress 0.2493371
Run 7 stress 0.2378191
... New best solution
... Procrustes: rmse 0.1165823 max resid 0.1934693
Run 8 stress 0.4248511
Run 9 stress 0.2753924
Run 10 stress 0.4222918
Run 11 stress 0.4963395
Run 12 stress 0.5162195
Run 13 stress 0.2675811
Run 14 stress 0.4079899
Run 15 stress 0.2695295
Run 16 stress 0.2437508
Run 17 stress 0.4935012
Run 18 stress 0.4941544
Run 19 stress 0.3371183
Run 20 stress 0.4490375
*** Best solution was not repeated -- monoMDS stopping criteria:
20: scale factor of the gradient < sfgrmin
R nous répond à la fin de la fonction qu’il n’a pas réussi à trouver de bonne configuration, 20 essais n’étaient pas assez :
*** No convergence -- monoMDS stopping criteria:
La première chose à faire lorsque vous vous heurtez à ce message est de relancer la fonction en lui permettant de faire plus d’essais. Pour se faire, il faut ajouter un argument nommé trymax. Pour être vraiment sûrs de notre affaire, on lui demande ici de refaire notre NMDS de k=1, mais avec 1000 essais plutôt que 20 :
Vous devriez maintenant obtenir ce message, après quelques centaines d’essais, chez moi j’en ai eu besoin de 273 :
*** Solution reached
On peut maintenant inspecter ce résultat pour voir la valeur de stress de la meilleure configuration trouvée :
resultat_k1
Call:
metaMDS(comm = oiseaux, distance = "bray", k = 1, trymax = 1000)
global Multidimensional Scaling using monoMDS
Data: oiseaux
Distance: bray
Dimensions: 1
Stress: 0.2353499
Stress type 1, weak ties
Best solution was repeated 1 time in 94 tries
The best solution was from try 77 (random start)
Scaling: centring, PC rotation, halfchange scaling
Species: expanded scores based on 'oiseaux'
Cette fois, la valeur de stress trouvée est de 0,235.
Comme cette valeur est > 0,20, on ne doit pas interpréter ces résultats. Ce NMDS n’est pas suffisamment représentatif de nos données originales.
Pour des raisons pédagogiques, je vous suggère tout de même de faire le graphique de ce NMDS, pour bien comprendre à quoi ça peut ressembler un NDMS à un seul axe :
plot(resultat_k1)
Remarquez comment ce graphique est construit plus ou moins comme si on avait pris le graphique de k=2, et qu’on l’avait écrasé verticalement en une seule ligne (et qu’on l’avait ensuite tourné de 90° dans le sens anti-horaire).
Il y a aussi une dernière nuance importante à savoir à propos de la fonction metaMDS. Si jamais vous décidez d’utiliser la distance euclidienne, sachez que la fonction tentera de transformer vos données sans vous en parler! Rappelez-vous que la librairie vegan a d’abord été créée pour analyser des communautés, avec une colonne par espèce. Dans ces cas, il est souvent pratique d’appliquer une transformation wisconsin aux données. Ce genre d’opération excède de loin le cadre du cours, mais ce qu’il est important de savoir est que, si vous utilisez metaMDS et la distance euclidienne, il faut aussi modifier l’argument autotransform, pour le mettre à FALSE.
26.5 Exercice : Le NMDS
Comme au chapitre Chapitre 25, répondez aux questions suivantes en vous basant sur le tableau de données dunede la librairie vegan :
Quelle distance devra-t-on utiliser pour calculer un NMDS sur ces données?
Calculez un NMDS avec un seul axe
Est-ce que ce NMDS peut être interprété?
Calculez un NMDS avec trois axes. Est-il plus interprétable?
Comparez la formation des axes avec la PCoA. Est-ce plutôt semblable ou plutôt différent?
Quels sont les deux sites les plus différents sur l’axe 1?
Défi supplémentaire
À l’aide des données environnementales fournies dans un second tableau de données (data(dune.env)), colorez les sites en fonction du taux d’humidité (Moisture) et choisissez une forme en fonction du type de gestion (Management).
Le gradient principal semble-t-il expliqué par une de ces variables?