Un peu comme nous l’avions fait pour les tests statistiques en mettant en place plusieurs concepts (distributions, intervalle de confiance, etc.) avant d’attaquer le vif du sujet, nous devrons aussi mettre en place plusieurs concepts avant de s’attaquer au sujet des ordinations comme tel dans les prochains chapitres.
Ces nouvelles notions sont nécessaires parce que, contrairement aux tests statistiques qui étudiaient au maximum deux variables à la fois, les ordinations peuvent s’attaquer à des dizaines ou même des centaines ou des milliers de variables en même temps. À moins que vous vouliez regarder un à un des centaines de nuages de points pour comprendre vos données, vous aurez besoin d’outils appropriés à ce genre de problèmes.
Nous verrons d’abord quatre matrices, qui permettent de décrire, chacune à leur façon, nos données. Nous devrons aussi voir le concept de distance multivariée, et nous verrons quelques façons différentes de mesurer cette distance.
22.2 La matrice de données
Commençons doucement avec la matrice de données. Cette dernière n’a rien de sorcier. Il s’agit essentiellement de notre tableau de données, mais avec une nuance importante : une matrice ne peut contenir qu’un seul type de données. Soit du texte, ou soit des chiffres, mais jamais les deux mélangés.
Pour appliquer des ordinations, vous aurez donc besoin de nettoyer vos tableaux de données pour ne conserver que les variables quantitatives. Nous verrons au Chapitre 30 comment transformer des variables catégoriques en quantitatives, mais nous ne compliquerons pas les choses pour le moment.
Comme pour notre tableau de données, il sera important que votre matrice de données soit dans le bon sens, c’est-à-dire que chacune des colonnes soit une variable et que chacune des lignes soit une observation. Afin de faciliter la discussion, nous introduirons aussi une notation pour ces deux concepts. Le nombre d’observations dans une matrice (le nombre de lignes) sera noté par la lettre n, et le nombre de variables (de colonnes) par la lettre p.
Cette matrice contenant des observations sur une série de poissons capturés dans un lac pourrait être définie par n=5 et p=3 :
Longueur (cm)
Poids (kg)
Profondeur (m)
80
3
4
60
2
3
10
15
2
5
28
1
4
2
3
22.3 La matrice de la somme des carrés et des produits croisés
Cette deuxième matrice est sans doute celle dont les calculs sont les plus abstraits et complexes à effectuer parmi celles que nous verrons dans ce chapitre.
Elle contient deux informations distinctes. Sur sa diagonale, elle contient la variabilité de chacune des variables par rapport à sa moyenne respective, que l’on nomme la somme des carrés. Dans le reste de la matrice, on retrouvera une idée de comment deux variables varient ensemble ou non, que l’on nomme la somme des produits croisés.
Voici, par exemple, la matrice de la somme des carrés et des produits croisés pour la matrice de données de la section précédente :
Longueur
Poids
Profondeur
Longueur
5084.8
-932
123.6
Poids
-932
526
-48
Profondeur
123.6
-48
5.2
Remarquez d’abord que nous passons d’une matrice de données de p x n à une matrice de p x p. Peu importe que notre matrice de données ait eu 3 ou 1000 observations, la matrice de la somme des carrés et des produits croisés aura toujours autant de lignes et de colonnes que notre matrice originale avait de variables (p).
Le calcul pour arriver à chacune des ces nouvelles valeurs peut être défini par l’équation suivante :
Pour les lignes i à n de notre matrice de données, où m et l sont les deux colonnes pour lesquelles ont veut faire le calcul.
Par exemple, pour arriver à la valeur -932, nous aurions donc procédé ainsi :
Trouver la moyenne de la variable Poids : 10
Trouver la moyenne de la variable Longueur : 31,8
Pour la première ligne de la matrice : (3-10) * (80-31,8) = -337,4
…
Pour la dernière ligne de la matrice : (2-10) * (4-31,8) = 222,4
Faire la somme de toutes ces valeurs : -337,4 + … + 222,4 = -932
Il n’est pas si important d’être capable de répliquer ce calcul manuellement. Par contre, il faut être capable de bien interpréter la matrice. Voici quelque exemples de questions pour vérifier votre compréhension :
Quelle variable varie le plus par rapport à sa moyenne?
Quelle variable varie le moins par rapport à sa moyenne?
(A: Longueur, B : Profondeur)
22.4 La matrice de variance-covariance
Vous avez sans doute remarqué que puisque la matrice précédente contient une série de sommes, les valeurs de chacune des cellules seront d’autant plus grandes que nous avons de lignes dans la matrice de données. Cela rend à peu près impossible une quelconque interprétation biologique des chiffres qui s’y retrouvent. C’est pourquoi avant l’interprétation, on peut diviser chaque cellule par son degré de liberté (n - 1), pour en arriver à la matrice de variance/covariance :
Longueur
Poids
Profondeur
Longueur
1271,2
-233,0
30,9
Poids
-233,0
131,5
-12
Profondeur
30,9
-12
1,3
Sur la diagonale de cette matrice, nous retrouvons donc la variance de chacune de nos variables, et dans les autres cellules, on retrouve ce que l’on appelle la covariance entre deux variables. Autrement dit, est-ce que deux variables varient fortement ensemble ou non, et si oui, dans quel sens.
Encore une fois, il faut être capable d’interpréter correctement cette matrice en répondant à des questions du genre :
Quelle variable présente la variance la plus faible?
Quelle variable présente la variance la plus élevée?
Quelles variables covarient le plus fortement?
La profondeur et la longueur sont-elles reliées positivement ou négativement?
Quelles variables semblent le moins reliées?
(A: Profondeur, B: Longueur, C: Poids et Longueur, D: Positivement, E: Profondeur et Poids)
Remarquez que, comme la matrice précédente, la matrice de variance-covariance est symétrique. La covariance entre Poids et Longueur est exactement la même qu’entre Longueur et Poids. Il arrivera fréquemment que seul le triangle inférieur ou supérieur de la matrice vous soit présenté pour économiser de l’espace.
22.5 La matrice de corrélation
Vous avez peut-être remarqué quelque chose qui clochait lors de vos interprétations de la matrice de variance-covariance? Les valeurs associées à la variable de Poids étaient toutes très élevées (en valeurs absolues) alors que celles associées à la profondeur étaient systématiquement très petites. Ce phénomène est dû au fait que la variance (et la covariance) se mesure à la même échelle que les données. Les valeurs associées à la profondeur sont petites parce que cette dernière a été mesurée en mètres. Si elle avait été mesurée en cm, elle aurait plutôt eu des valeurs très grandes, probablement les plus grandes de la matrice. Quelles sont donc vraiment les deux variables les plus associées, si on ne peut pas se fier aux chiffres de la matrice de variance/covariance?
Une façon d’y arriver est de transformer notre matrice de variance-covariance en matrice de corrélation. Vous vous rappelez sans doute que cette dernière sert justement à remettre toutes les relations à une même échelle, allant de -1 à +1, et ce, peu importe comment les données ont été mesurées (voir Chapitre 17 pour un rappel).
Nous avions énoncé le modèle conceptuel de la corrélation comme la covariance entre deux variables, divisé par le produit de leurs écart-types. Si nous appliquons cette transformation sur la matrice précédente, nous obtenons la matrice de corrélation, comme celle-ci pour l’exemple sur les poissons :
Longueur
Poids
Profondeur
Longueur
1
-0,57
0,76
Poids
-0,57
1
-0,92
Profondeur
0,76
-0,92
1
Cette matrice contient donc, à chacune des intersections, la corrélation entre chacune des variables. La longueur et le poids sont par exemple corrélés négativement, avec un r de -0,57. Cette matrice contient évidemment une série de 1 sur la diagonale, puisque chaque variable est parfaitement corrélée avec elle-même.
22.6 Le concept de distance multivariée
La covariance et la corrélation sont des façons plutôt intuitives de définir l’association entre deux variables, soit à l’échelle originale des données (variance-covariance) ou soit à une échelle standardisée allant de -1 à 1 (corrélation).
Par contre, si on tourne le problème de côté et qu’on se demande comment sont associées deux observations dans notre tableau de données (i.e. combien deux lignes se ressemblent), nous avons besoin d’outils différents : les distances multivariées.
Eh oui, étrangement, les statisticiens ont décidé que, lorsque l’on voulait savoir si deux observations se ressemblent ou non, ou n’allions pas mesurer si elles sont proches, mais bien si elles sont loins l’une de l’autre. Il s’agit là d’une des clés pour bien saisir les sections suivantes. Plus la distance entre deux observations est élevée, plus les observations sont différentes l’une de l’autre. Plus la distance est petite, plus les observations sont semblables. Comprenez bien ici que l’on discute d’une distance conceptuelle; on ne parle pas nécessairement de cm ou de km.
L’autre chose importante à savoir est qu’il existe, selon Numerical Ecology de Legendre & Legendre, au moins 26 (!) façons différentes de mesurer la distance entre deux observations. Toutes ces mesures existent pour tenir compte des particularités statistiques et biologiques des données que vous pourriez rencontrer. Mais rassurez-vous, dans ce chapitre, nous n’en verrons que 2 1⁄2, qui devraient répondre à la majorité des besoins que vous rencontrerez.
22.7 La distance euclidienne
Si les observations dans votre matrice de données sont composées de variables continues (et non de présences/absences ou de décomptes d’individus), la façon la plus simple et la plus intuitive de décrire la distance entre elles est ce que l’on appelle la distance euclidienne.
Malgré son nom un peu ésotérique, vous avez souvent rencontré cette distance par le passé, puisque si vous n’avez que deux variables, elle est équivalente à l’hypoténuse d’un triangle rectangle, qui se définit comme ceci :
\[
c^2=a^2+b^2
\]
Où c est l’hypoténuse et a et b sont la longueur de chacun des côtés du triangle. L’hypoténuse se calcule donc comme ceci :
\[
c=\sqrt{a^2+b^2}
\]
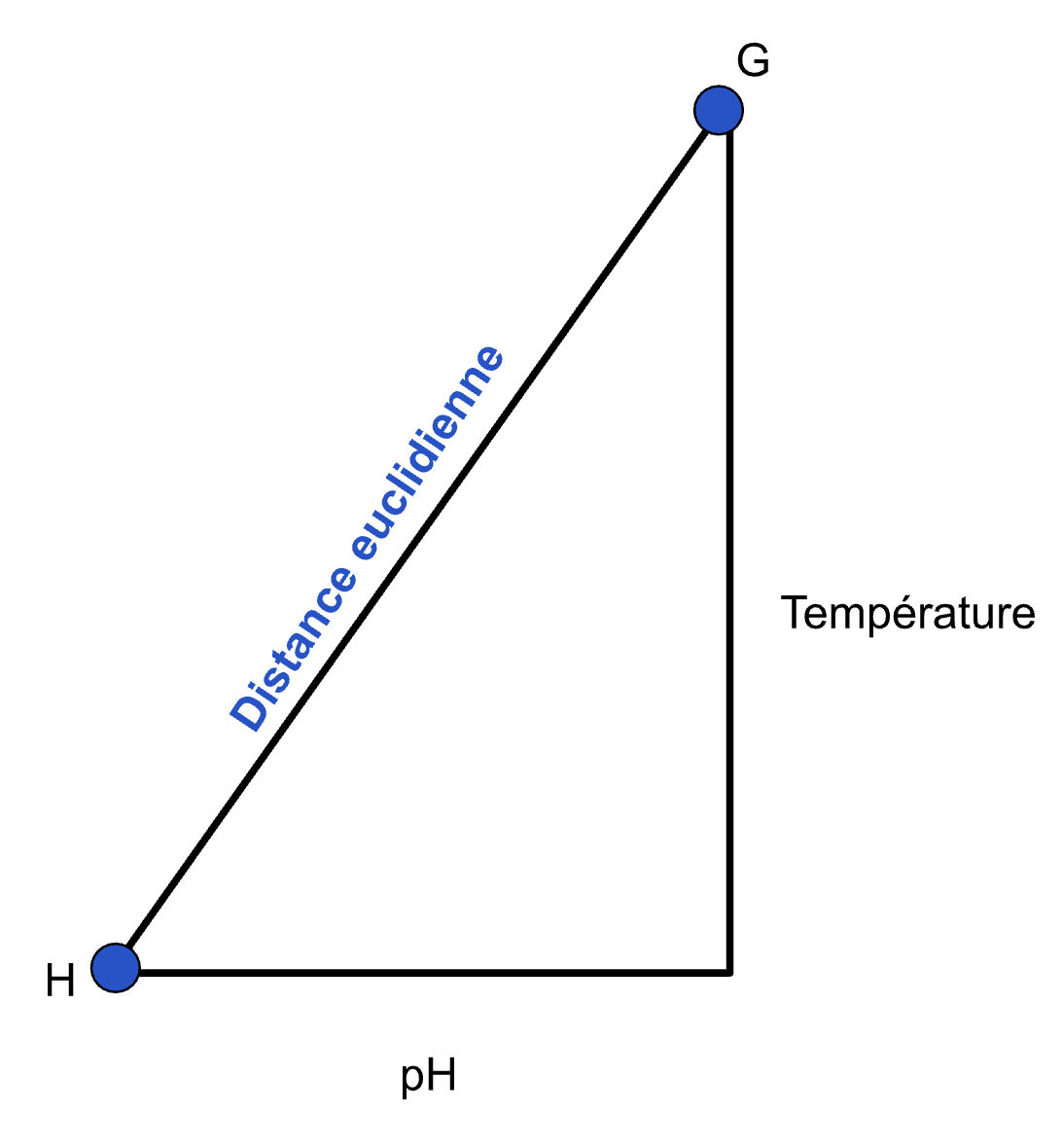
Si par exemple vous aviez un mini-tableau de données comme celui-ci :
Site
pH
Température
G
7
25
H
6.5
21
Si vous voulez connaître la distance euclidienne entre ces deux sites, vous devez d’abord visualiser un triangle où la température serait d’un côté et le pH de l’autre, un peu comme ceci :
La distance euclidienne entre ces deux observations se calculerait donc comme ceci :
\[
\sqrt{(7-6.5)^2 +(25-21)^2}=4,03
\]
Remarquez que lorsque l’on calcule des distances multivariées, le concept d’unités est un peu laissé de côté. Vous ne lirez jamais que ces deux observations sont à 4,03 pH-degrés l’une de l’autre.
Une fois cet exemple derrière nous, la définition formelle de la distance euclidienne est plutôt intuitive, puisqu’elle est l’équivalent d’une hypoténuse en p dimensions. Notre cerveau humain n’a aucun problème à imaginer une hypoténuse en 2 dimensions comme dans l’exemple précédent. Nous sommes aussi, avec un peu plus de travail, capables d’en imaginer une en 3 dimensions, mais l’ordinateur lui n’a aucun problème à la calculer en 4, 10, ou même 200 dimensions. Afin de rendre la notation plus compacte, la distance euclidienne est habituellement définie par la formule suivante :
\[
\sqrt{
\sum^p_{j=1}(y_{1j}-y_{2j})^2
}
\]
Évidemment, comme toutes les autres formules présentées dans ce livre, je vous la présente à titre de référence. Je ne vous demanderai jamais de me recracher cette formule par cœur. Si vous comprenez le principe que la distance euclidienne est comme une hypoténuse en plusieurs dimensions, vous en comprenez bien assez pour le moment. Remarquez cependant que, de par sa définition, la distance euclidienne la plus courte possible est zéro (pour des observations identiques) et qu’elle n’a pas de limite supérieure.
Comme vous vous en doutez peut-être, une distance seule, par elle-même, a peu d’utilité. On calcule habituellement une matrice de distances, à partir de toutes les observations d’une matrice de données. Si nous avions par exemple une série de mesures prises sur des espèces d’oiseaux comme ceci :
Espèce
Longueur (cm)
Envergure (cm)
Poids (g)
Durbec
23
37
56
Oriole
22
29
33
Pic
32
51
130
Canard
51
84
910
Busard
45,7
189,2
424,5
La matrice de distances euclidiennes correspondantes aurait l’air de ceci :
Durbec
Oriole
Pic
Canard
Oriole
24,37
Pic
75,84
99,96
Canard
855,75
879,20
780,92
Busard
376,19
400,33
300,51
486,18
Comme pour les matrices de variance-covariance et de corrélation, il est important de pouvoir bien interpréter une telle matrice, par exemple :
A. Quelles espèces sont les plus différentes les unes des autres?
B. Quelles espèces sont les plus semblables?
C. À quelle espèce le pic flamboyant ressemble-t-il le plus?
(A : Oriole-Canard; B : Oriole-Durbec; C: Durbec)
22.8 Centrer et réduire
La distance euclidienne présente une particularité importante à laquelle il faut être très attentifs : elle est très sensible aux différences d’échelles entre nos variables. Si les unités d’une de nos variables sont beaucoup plus grandes que celles des autres, cette dernière contrôlerait à elle-seule ou presque le calcul de l’hypoténuse. Bien que l’on entrerait toutes les variables dans le calcul, le résultat représenterait essentiellement les différences dans notre variable ayant les grands chiffres.
La solution pour éviter ce genre de problème est de centrer et réduire (to scale) nos variables avant de les entrer dans le calcul. C’est-à-dire de soustraire la moyenne (centrer) et de diviser par l’écart-type (réduire) pour chacune des données.
Prenons ce mini-tableau de données comme exemple :
Variable A
Variable B
1
1000
2
2000
Vous constatez facilement que l’échelle de mesure de la variable B est beaucoup plus grande que celle de la variable A. Si on applique l’opération de centre et réduire chacune des variables, on obtient maintenant le tableau suivant :
Variable A
Variable B
-0,707
-0,707
0,707
0,707
Autrement dit, la première observation de la variable A est 0,707 écarts-types sous la moyenne, tout comme la première de la variable B. Les deux variables (A et B) auraient donc maintenant un poids équivalent dans le calcul de la distance euclidienne.
Dans la vraie vie, vous devrez dans presque tous les cas centrer et réduire vos variables avant d’appliquer le calcul de la distance euclidienne. Le seul cas où ce n’est pas recommandé est si toutes vos variables sont déjà à la même échelle. Par exemple, si vos variables étaient toutes des températures, disons une pour le matin, une pour le midi, une pour le soir, etc.
22.9 La distance de Bray-Curtis
La distance euclidienne fonctionnera bien pour beaucoup de contextes, mais pour certains cas particuliers, elle pourrait vous causer de gros ennuis. Ce sera le cas si votre matrice de données contient des abondances d’espèces, en particulier si cette dernière contient beaucoup de zéros, par exemple comme ceci :
Geai
Viréo
Oriole
Site A
0
1
1
Site B
1
0
0
Site C
0
4
4
Si vous calculez les distances euclidiennes sur cette matrice, le calcul vous informera que le site A ressemblerait plus au site B qu’au site C :
Site A
Site B
Site B
1,73
Site C
4,24
5,74
Ces distances sont clairement erronées d’un point de vue écologique. La composition en espèces de A est en fait identique à celle de C. C’est ce que l’on appelle le paradoxe d’Orloci.
Pour cette raison, lorsque vous analysez des matrices d’abondances d’espèces, il est recommandé d’utiliser plutôt la distance de Bray-Curtis, que l’on appelle aussi parfois le coefficient de Czekanowski ou le pourcentage de dissimilarité. Cette distance peut aller de zéro (des sites complètement identiques) à un (pour des sites complètement différents dans leur composition).
Nous verrons ensemble le calcul pour que vous ayez une idée d’où les chiffres viennent, mais vous n’aurez jamais à les calculer vous-même manuellement.
Yark, ça fait peur. Mais allons-y morceau par morceau, puisque le calcul se fait en 3 étapes principales. On regarde d’abord pour chaque espèce le minimum entre les deux sites, que l’on multiplie par 2, puis on en fait la somme. On divise ensuite ce total par l’abondance totale de toutes les espèces aux deux sites. Et finalement, on fait 1 moins cette valeur.
L’intuition à comprendre derrière le calcul est que si l’abondance de chaque espèce est égale aux deux sites, la partie d’en haut et d’en bas seront absolument égales et leur ratio sera 1.
Et voici à titre d’exemple le résultat de ce calcul sur la matrice de données précédente :
Site A
Site B
Site B
1
Site C
0,6
1
On récupère donc maintenant des distances qui ont du bons sens écologiquement. Remarquez que les sites A et C ne sont pas considérés comme identiques, puisque bien que leur composition soit la même, les abondances sont différentes entre les deux sites.
22.10 L’indice de Jaccard
Le dernier scénario que nous verrons dans ce chapitre est celui où votre matrice de données, plutôt que de contenir des données continues ou des décomptes, contient en fait des données de présence-absence, c’est-à-dire des 1 ou des 0 uniquement. Dans ce genre de situation, un des calculs de distance souvent recommandé est l’indice de Jaccard.
La formule associée à l’indice de Jaccard est celle-ci :
\[
1-\frac{a}{a+b+c}
\]
Où a est le nombre d’espèces communes aux deux sites, b est le nombre d’espèces uniques au site 1 et c et le nombre d’espèces uniques au site 2. L’indice de Jaccard sera donc de 0 si toutes les espèces sont les mêmes entre les sites, et de 1 si toutes les espèces sont différentes.
Par contre, plusieurs auteurs recommandent plutôt d’utiliser le coefficient de Sorensen pour calculer les distances dans des scénarios de présence-absence. La différence majeure entre le coefficient de Sorensen et celui de Jaccard étant que celui de Sorensen donne plus d’importance dans son calcul aux espèces communes qu’aux différences.
Ce qu’il est intéressant de savoir ici est que le calcul de Sorensen est exactement identique à celui de Bray-Curtis. Si on applique la formule sur une matrice d’abondance, on parle de Bray-Curtis, et sur une matrice de présence-absence, on parle alors de coefficient de Sorensen.
22.11 Labo : Les matrices et les distances
Nous verrons maintenant comment calculer avec R les matrices vues dans les sections précédentes. Remarquez que ces codes sont fournis plutôt à titre informatif, puisque la plupart du temps, vous n’aurez pas à faire ces calculs manuellement. Ce sont des étapes intermédiaires dans le calcul des ordinations. Il n’y aura donc pas d’exercices associés.
Nous allons comme c’est notre habitude, utiliser le tableau de données des manchots de l’archipel Palmer, sur lequel nous allons d’abord calculer les matrices de la somme des carrés et des produits croisés (crossprod), de variance-covariance puis de corrélation.
Avant de commencer, nous devrons cependant limiter notre tableau de données à 3 variables pour simplifier les sorties, et éliminer les lignes contenant des valeurs manquantes.
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Remarquez que la fonction crossprod est un peu têtue et on doit absolument convertir notre tableau de données en objet matrice avant qu’elle puisse faire son calcul, alors que les deux autres le font elles-mêmes sans se plaindre.
Maintenant, pour les calculs de distances, vous aurez aussi besoin d’une librairie additionnelle qui se nomme vegan. Nous utiliserons cette librairie pour la grande majorité des calculs d’ordinations des prochains chapitres.
Nous nous créerons aussi un nouveau petit de tableau de données basé sur les manchots de Palmer. Il aurait été utile et légitime de calculer des distances entre chacun des individus, mais il sera beaucoup plus facile de comprendre si on se fait un mini-tableau avec une ligne par espèce :
Nous utiliserons aussi, pour la première fois, la fonction column_to_rownames de la librairie tibble (inclue dans le tidyverse). Il s’agit en fait d’une technicalité, mais cette fonction permet d’éliminer une colonne de notre tableau, et de plutôt mettre l’information de cette colonne dans les méta-informations du tableau. C’est un peu de gossage, mais ça permet que les fonctions calculant les matrices de distances puissent nous afficher à quelle ligne était associée chaque distance, sans que le calcul bogue parce qu’on a une colonne qui n’est pas des chiffres.
Remarquez que les noms de lignes doivent être uniques. Si vous n’avez pas une colonne permettant d’identifier de façon unique chacune des lignes, vous ne pourrez pas appliquer column_to_rownames pour retrouver chacune des observations dans les sorties de vegan. C’est tannant, mais pas dramatique.
Une fois cette librairie activée, les calculs de distances se feront avec la fonction vegdist, à laquelle il faudra passer comme argument le nom de la distance que l’on veut calculer :
Remarquez ici que j’utilise la distance de Bray-Curtis et de Jaccard sur des données continues uniquement à titre d’illustration des arguments de la fonction. Il n’aurait pas été pertinent de faire cela dans la vraie vie.
Enfin, si on veut centrer-réduire nos données avant de les envoyer au calcul de distance, R possède une fonction toute prête pour le faire, nommée scale. On pourrait par exemple l’utiliser comme ceci :
Basé sur la distance euclidienne, les deux espèces les plus semblables sont les manchots Adélie et les manchots Chinstrap Les deux plus différentes sont les Adélie et les Gentoo.
22.12 Résumé
Si l’on résume ce que l’on vient de voir, il existe deux matrices pour mesurer l’association entre les variables dans un tableau de données :
La matrice de variance-covariance, qui est affectée par l’échelle des données
La matrice de corrélation, qui permet de remettre toutes les variables à la même échelle et éviter ces problèmes
Si l’on veut mesurer la distance entre les observations, il existe au moins trois calculs différents :
La distance euclidienne pour les données continues (attention aux différences d’échelle)
La distance de Bray-Curtis pour les décomptes
La distance de Jaccard pour les présences-absences
On peut aussi utiliser la distance de Bray-Curtis (que l’on nomme alors Sorensen) pour les présences-absences, en se rappelant qu’elle donne plus de poids aux espèces communes qu’aux différences.