Dans notre survol des tests statistiques, nous avons exploré une variété de méthodes pour tester le lien entre deux variables. Certaines de ces méthodes ne faisaient que tester pour une association (par exemple la corrélation et le khi-carré), mais d’autres assumaient un lien de cause à effet entre les deux variables (régression, ANOVA). Dans tous les cas, nous étions cependant limitées à étudier une seule cause à la fois. Pourtant, dans la vraie vie, particulièrement en écologie, il y a rarement une seule cause à un phénomène. Pensez simplement au poids d’un poisson. Ce dernier peut être influencé entre autres par son âge (croissance), la quantité de nourriture disponible, son bagage génétique, la saison, etc.
La régression multiple est l’outil par lequel nous pourrons étudier simultanément l’effet de plusieurs causes sur notre variable expliquée. La régression multiple telle que montrée ici nous permet de le faire avec plusieurs variables quantitatives, et nous verrons au Chapitre 30 comment on peut aussi y intégrer des variables catégoriques (oui oui!).
Comme pour le chapitre sur la régression linéaire, nous verrons d’abord la théorie et ensuite un exemple concret dans la partie laboratoire afin d’alléger la présentation de ce chapitre, qui pourrait facilement devenir lourde.
28.2 Modèle statistique et interprétation
Nous avons vu au Chapitre 18, que l’équation de la régression simple peut être écrite comme ceci : \[
y = b_0 + b_1x
\]
Où b0 et b1 sont respectivement les valeurs associées à nos paramètres d’ordonnée à l’origine et de pente.
La régression multiple fonctionne exactement de la même façon, mais peut compter autant de pentes que nous voulons étudier de variables dans notre modèle. La façon générale de décrire cela est donc comme ceci :
\[
y = b_0 + b_1x_1+ b_2x_2 \ldots + b_px_p
\]
Si nous avions quatre variables explicatives dans notre modèle, l’équation serait par exemple comme ceci :
\[
y = b_0 + b_1x_1 + b_2x_2+ b_3x_3+ b_4x_4
\]
L’interprétation de ces paramètres se fait un peu comme dans la régression linéaire simple, mais doit se faire de façon plus nuancée.
b0 est encore notre ordonnée à l’origine. On se rappelle que dans la régression linéaire, on interprétait l’ordonnée à l’origine comme étant la hauteur où l’on était sur l’axe des Y quand X=0. Ici, puisque nous avons plusieurs variables explicatives, l’ordonnée à l’origine devient notre valeur de Y, lorsque toutes les variables explicatives (x1, x2, x3, etc.) sont à zéro.
Chacun des autres paramètres (b1, b2, b3, etc.) sont encore des pentes, mais on parle maintenant de pentes partielles. On se rappelle que dans la régression linéaire simple, on interprétait une pente comme le changement en Y pour un changement de une unité en X. Ici, dans la régression multiple, b1 est le changement en Y pour un changement d’une unité de X1 en assumant que toutes autres variables étudiées (x2, x3, etc.) restent constantes.
Autrement dit, chacun des coefficients répond à la question : qu’apporte cette variable si l’on connaît déjà la valeur de toutes les autres.
Et enfin, la question qui vous reste peut-être en tête à ce point : jusqu’à combien de variables je peux mettre dans mon modèle? Cette limite changera en fait d’une analyse à l’autre, puisque le nombre de variables que vous pouvez entrer dans le modèle dépend du nombre d’observations que vous avez recueillies. Vous vous rappelez peut-être du concept de degrés de liberté (voir Chapitre 10)? Dans un modèle de régression multiple nous ajustons, comme suggéré dans les formules précédentes, autant de paramètres que nous avons de variables + un pour l’ordonnée à l’origine. Pour qu’un modèle statistique s’ajuste, il doit toujours lui rester au moins 1 degré de liberté. Donc, si vous avez 7 observations dans votre tableau de données, vous pouvez entrer jusqu’à 5 variables dans votre modèle. Si vous avez 1000 observations, vous pouvez ajuster jusqu’à 998 variables. Évidemment, ce genre de modèles sera très incertain, puisque l’on recommande en général d’avoir au moins 25, idéalement 40, observations par paramètre que l’on veut estimer.
28.3 Tests statistiques
Bien que le modèle de régression linéaire, avec ses paramètres et intervalles de confiance soit directement interprétable, il pourra arriver que l’on vous demande si votre modèle est statistiquement significatif, et si l’effet de certaines variables, individuellement, soit significativement différent de zéro.
Pour tester si le modèle entier est significatif, il faut simplement appliquer un test de F avec au numérateur les carrés moyens associés au modèle, et au dénominateur les carrés moyens associés aux résidus :
\[
F = MS_{régression}/MS_{résidus}
\]
Ce test pourrait aussi s’utiliser avec la régression linéaire simple, et vous donnera exactement la même valeur de p que celle du test de t associé à la pente expliqué au Chapitre 18.
Ce qu’il faut bien comprendre avec ce test, c’est qu’il nous informe que notre modèle, au total, est significatif ou non. Par contre, il pourrait arriver que parmi les variables que nous avons incluses dans le modèle, que certaines aient un effet significatif, mais que d’autres non. Il existe deux stratégies équivalentes pour déterminer si une pente individuelle est significative ou non.
La première est ce que l’on appelle les tests de F partiels. L’idée derrière ces tests est de regarder l’apport d’une variable individuelle, par rapport au bruit dans notre modèle. Si l’apport de la variable est grand par rapport au bruit, on considère cette variable comme significative. Pour déterminer l’apport d’une variable, il faut commencer par ajuster un modèle complet, regarder la variance expliquée par ce modèle et y soustraire la variance expliquée par un modèle simplifié, où notre variable d’intérêt n’est pas présente. On fait ensuite le ratio entre cette différence de variance et la variance des résidus pour trouver notre valeur de F, qui doit être comparée à la distribution théorique pour n-1 degrés de liberté.
La deuxième technique est celle des tests de t, telle que montrée au Chapitre 18. Autrement dit, on calcule une valeur de t en faisant le ratio entre la pente partielle et son erreur type, et on compare ensuite cette valeur trouvée à une distribution de t théorique pour les degrés de liberté de notre modèle (n moins le nombre de paramètres).
Les deux stratégies (test de F partiel et test de t) vous donneront toujours exactement la même valeur de p. Les tests de t ont l’avantage d’être plus simples à calculer et sont fournis directement dans les sorties de R. Par contre, l’approche des tests de F partiels est beaucoup plus flexible. Elle permet de tester des groupes entiers de variables d’un coup. On peut donc plus facilement tester des hypothèses, par exemple est-ce que les variables climatiques ont un effet significatif, est-ce que les variables physico-chimiques ont un effet significatif, etc.
28.4 Comparer la magnitude des effets
Comme nous en avons discuté dans le chapitre sur la régression linéaire, la mesure de la magnitude de l’effet d’une régression est la valeur du paramètre de pente. Plus ce chiffre est gros, plus la magnitude de l’effet est grande. On pourrait donc penser que pour savoir laquelle de nos variables a le plus grand effet dans une régression multiple, on peut simplement comparer les paramètres de pente entre eux… mais ce n’est malheureusement pas aussi simple.
La valeur du paramètre de pente dans une régression dépend grandement de l’échelle à laquelle nos données ont été mesurées. Si nous avons, par exemple, une régression dans laquelle nous tentons de prédire le nombre d’espèces d’oiseaux dans une parcelle, pour laquelle nous avons mesuré le bruit ambiant et la surface de la parcelle, nous pourrions obtenir cette équation si la surface était mesurée en km2 :
Avec la mesure en m2, la surface semble avoir un effet plus important que le bruit. Avec les km2, le bruit semble avoir un effet plus important que la surface. Vous voyez le genre de problèmes que ça peut occasionner?
Alors on ne peut jamais comparer l’ampleur des pentes Charles?
Évidemment il y a une solution! Nous l’avons même déjà évoqué au Chapitre 22 sur les matrices et les distances. Le truc est de ramener toutes nos variables à la même échelle pour les comparer. Il existe deux façons d’y arriver. Une que l’on peut appliquer après avoir ajusté notre modèle, et l’autre que l’on peut appliquer en amont, avant de lancer notre analyse.
La solution après-coup consiste à standardiser les valeurs de pentes que nous avons trouvées. Cette opération peut être décrite de façon formelle pour une variable j comme ceci :
\[
b_j^* = b_j \frac{\sigma_{X_j}}{\sigma_Y}
\]
Autrement dit, la pente standardisée est trouvée en multipliant la pente par le ratio entre les écart-types de la variable explicative et la variable expliquée.
Si l’on retourne à notre exemple avec la surface en km2, il faudrait donc aller calculer dans nos données l’écart-type de chacune des variables (par exemple σoiseaux = 3, σbruit = 1, σsurface = 2).
La pente standardisée pour la surface est donc 3 x 2/3 = 2 et celle pour le bruit est de 5 x 1/3 = 1,67. On comprend maintenant que les deux variables ont un effet à peu près équivalent, mais que l’effet de la surface est un peu plus grand.
Remarquez que l’interprétation des pentes standardisée est un peu plus abstraite. Plutôt que dire que l’on augmente de 3 espèces d’oiseaux par kilomètre carré de surface, on doit maintenant dire que la richesse d’oiseaux augmente de 2 écart-types pour chaque changement de 1 écart-type de surface.
C’est pourquoi habituellement, on combine les deux valeurs dans notre interprétation. Celles à l’échelle originale pour bien saisir la magnitude des effets en termes concrets, et celles à l’échelle standardisée pour pouvoir bien comparer les pentes entre-elles.
Enfin, la deuxième façon de standardiser les pentes en sortie de notre modèle consiste à centrer et réduire chacune de nos variables avant de lancer l’analyse. Ainsi, tous les paramètres en sortie seront déjà standardisés. Il s’agit souvent de la façon la plus simple de procéder, puisque l’on peut souvent centrer et réduire l’ensemble de notre tableau de données avec une seule commande R.
28.5 Assomptions et validations
La régression multiple comporte les quatre mêmes assomptions que la régression linéaire : normalité des résidus, homogénéité de la variance des résidus, indépendance des observations et X est fixé par l’observateur. Elle en ajoute cependant une cinquième, qui consiste à dire que les variables explicatives ne doivent pas être corrélées entre elles. C’est-à-dire qu’il doit y avoir absence de colinéarité entre les variables explicatives.
Comme pour la régression linéaire simple, les assomptions stipulant que les observations sont indépendantes et que X est fixé par l’observateur doivent être correctement réfléchies en amont de l’expérience. La validation de la normalité des résidus se fait aussi exactement de la même façon que dans la régression linéaire : on fait un histogramme des résidus.
Comme pour la régression linéaire, même si il ne s’agit pas d’une validation aussi formelle que celle effectuée sur les résidus après l’ajustement du modèle, c’est quand même toujours une bonne idée de regarder l’histogramme de chacune de nos variables et la linéarité des relations entre nos variables explicatives et la variable expliquée avant de se lancer dans la modélisation et d’appliquer les transformations nécessaires au besoin.
Là où les choses deviennent différentes/compliquées est pour la validation de l’homogénéité des résidus. Cette dernière doit maintenant être vérifiée non seulement en fonction des valeurs prédites, mais aussi en fonction de chacune des variables présentes dans notre modèle. On devra donc faire autant de nuages de points qu’il y a de variables dans notre modèle, en plus de celui des valeurs prédites. On veut s’assurer dans chacun de ces graphiques qu’il n’y a pas de patrons dans les résidus. Autrement dit, que notre modèle n’est pas meilleur ou pire à un extrême ou à l’autre des données. Si cela devait arriver, il faudra soit transformer nos données (ce qui peut souvent corriger des problèmes de variances inégales) ou se demander si il n’y a pas une variable importante qui a été négligée dans notre modèle.
28.6 La colinéarité
Et pour la colinéarité, comment peut-on valider son absence? D’abord, la première chose à savoir est que, particulièrement en écologie, vos variables explicatives seront toujours plus ou moins corrélées entre elles. Tester pour savoir s’il existe une corrélation entre vos variables est presque inutile parce qu’il en existera quasiment toujours une.
Avant d’aller plus loin, il importe de bien comprendre quels sont les effets de la colinéarité dans un modèle de régression. Il en existe deux majeurs. D’abord, les estimés de paramètres peuvent devenir instables. C’est-à-dire qu’enlever ou ajouter une seule observation au tableau de données pourrait complètement changer leur sens. On ne veut évidemment pas que ça nous arrive! L’autre problème qui survient en présence de colinéarité importante est que les intervalles de confiance vont être gonflés (i.e. plus larges). Comme nous en avons discuté plus haut, puisque nos tests statistiques pour les pentes sont basés sur notre mesure de certitude (si on parle du test de t), la colinéarité fera diminuer nos chances de trouver des pentes significatives. Cela peut même aller au point où le test de notre modèle entier serait significatif, mais qu’aucune pente individuelle ne le serait. Ce résultat plutôt surprenant est cependant tout à fait représentatif du problème : nos hypothèses sont bonnes, les deux variables ensemble ont une influence significative sur le phénomène, mais le fait qu’elles soient colinéaires ensemble nous empêche de distinguer leurs effets respectifs. On ne sait pas laquelle fait quoi.
On se rappelle, chacun des coefficients répond à la question : que nous donne de plus cette variable si on connaît déjà la valeur des autres…
Cela nous amène maintenant à parler de ce que la colinéarité n’affecte PAS. En effet, il est important de comprendre qu’avoir des variables colinéaires n’affecte en rien les prédictions du modèle, ni son r2. La seule chose qui est affectée par la colinéarité est les estimés de pente et notre confiance en ces valeurs.
Pour savoir si la colinéarité est un problème dans notre modèle, on utilise souvent une mesure nommée VIF (pour Variance Inflation Factor). Le calcul du VIF nous fournit un chiffre pour chacune de nos variables, nous informant de combien cette variable ajoute de l’instabilité au modèle. Les statisticiens disent en général que l’on commence à avoir un problème de colinéarité quand le VIF d’une de nos variables dépasse 4. Vous trouverez parfois aussi la valeur de 10 ou même plus comme valeur seuil. Il s’agit en fait d’un aide à la décision (rule of thumb) et non d’un test statistique à proprement parler.
À l’aide du VIF, on peut cependant quantifier l’impact de la colinéarité sur l’incertitude de nos estimations de paramètres. Pour se faire, il faut savoir que la racine carrée de VIF nous donne un facteur par lequel l’erreur-type (une mesure d’incertitude) sera multipliée en comparaison d’un modèle sans colinéarité. Par exemple, si notre VIF est de 4, l’erreur-type est multipliée par 2, si le VIF est de 9, l’erreur-type sera multipliée par 3, etc. Cela nous donne un ordre de grandeur du problème.
Et on fait quoi si jamais on a une colinéarité importante dans notre modèle? Comme d’habitude, il n’y a pas de solution parfaite. La solution généralement recommandée est d’enlever du modèle une (ou plusieurs) variables avec un VIF élevé. Ainsi, les estimés de paramètres des variables restantes seront plus précis. Mais il faut garder en tête (et écrire dans notre rapport) que ces estimés de paramètres sont probablement aussi biaisés. La valeur élevée de VIF nous disait que le modèle était incapable de distinguer l’effet de ces variables corrélées. Il est donc possible que la variable que nous avons enlevée du modèle était celle qui en fait causait le phénomène. C’est pourquoi il est important, lorsque l’on supprime ainsi une variable de notre modèle à cause du VIF, de toujours conserver les variables pour lesquelles nos hypothèses étaient les plus solides et enlever celles pour lesquelles nos hypothèses étaient les moins fortes.
La deuxième solution possible est de remplacer les variables de notre analyse par les axes d’une ACP sur ces mêmes variables. Par exemple, si dans notre modèle on voulait mettre la longueur, la masse et l’envergure des oiseaux, on pourrait mettre ces variables dans une ACP et on pourrait utiliser le premier axe de l’ACP, sans doute représentatif de la taille globale de l’oiseau, comme variable dans notre modèle. Comme les axes de l’ACP sont entièrement orthogonaux, nous n’aurons jamais de problème de colinéarité en les mettant dans notre modèle. Par contre, remarquez qu’ainsi, on complique aussi l’interprétation des pentes. Celle-ci ne serait plus ni en cm, ni en g, mais dans les unités conceptuelles de l’ACP.
La troisième façon de faire, que je privilégie souvent, mais qui n’est pas autant appliquée que les deux premières, est simplement de conserver les résultats ainsi dans le rapport, mais de bien discuter du problème de colinéarité. De dire directement que tel ou tel paramètre est probablement instable à cause de la colinéarité entre nos variables. Je trouve personnellement cette façon de faire plus utile pour la science, puisqu’elle met en relief les incertitudes de notre modèle, plutôt que de se créer de fausses certitudes en enlevant simplement une des variables du modèle. Cette façon de faire n’est pas particulièrement répandue, mais à mon avis, elle gagnerait à l’être.
28.7 Labo : la régression multiple
Nous reprendrons notre laboratoire du Chapitre 18 où nous avons étudié l’effet de la longueur des ailes sur le poids des manchots. Nous essayerons ici de comprendre plus globalement ce qui influence le poids des manchots, en ajoutant aussi la longueur et l’épaisseur du bec. Notre hypothèse étant que plus le bec et long et épais, plus le manchot pourra attraper de poissons, donc plus il sera lourd.
Avant de procéder à ce laboratoire, vous devrez installer les librairies car (comme dans voiture en anglais) et visreg (VISualizing REGressions), dans lesquelles nous pigerons des fonctions pour nous aider en cours de route.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
library(GGally)library(car)
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
The following object is masked from 'package:purrr':
some
On doit ensuite explorer visuellement nos données pour s’assurer que tout est OK :
ggpairs(pour_regression_multiple)
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
Warning: Removed 9 rows containing missing values or values
outside the scale range (`stat_boxplot()`).
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
Donc, à première vue, nos relations sont relativement linéaires et nos variables relativement normales. Par contre, certaines de nos variables explicatives sont plus ou moins corrélées ensemble (entre autres, 0,65 entre le longueur des ailes et la longueur du bec). Il faudra vérifier que cela n’ajoute pas trop d’instabilité à notre modèle.
On peut maintenant ajuster notre modèle de régression multiple. Pour cela, on utilise la même fonction que pour la régression linéaire, soit lm:
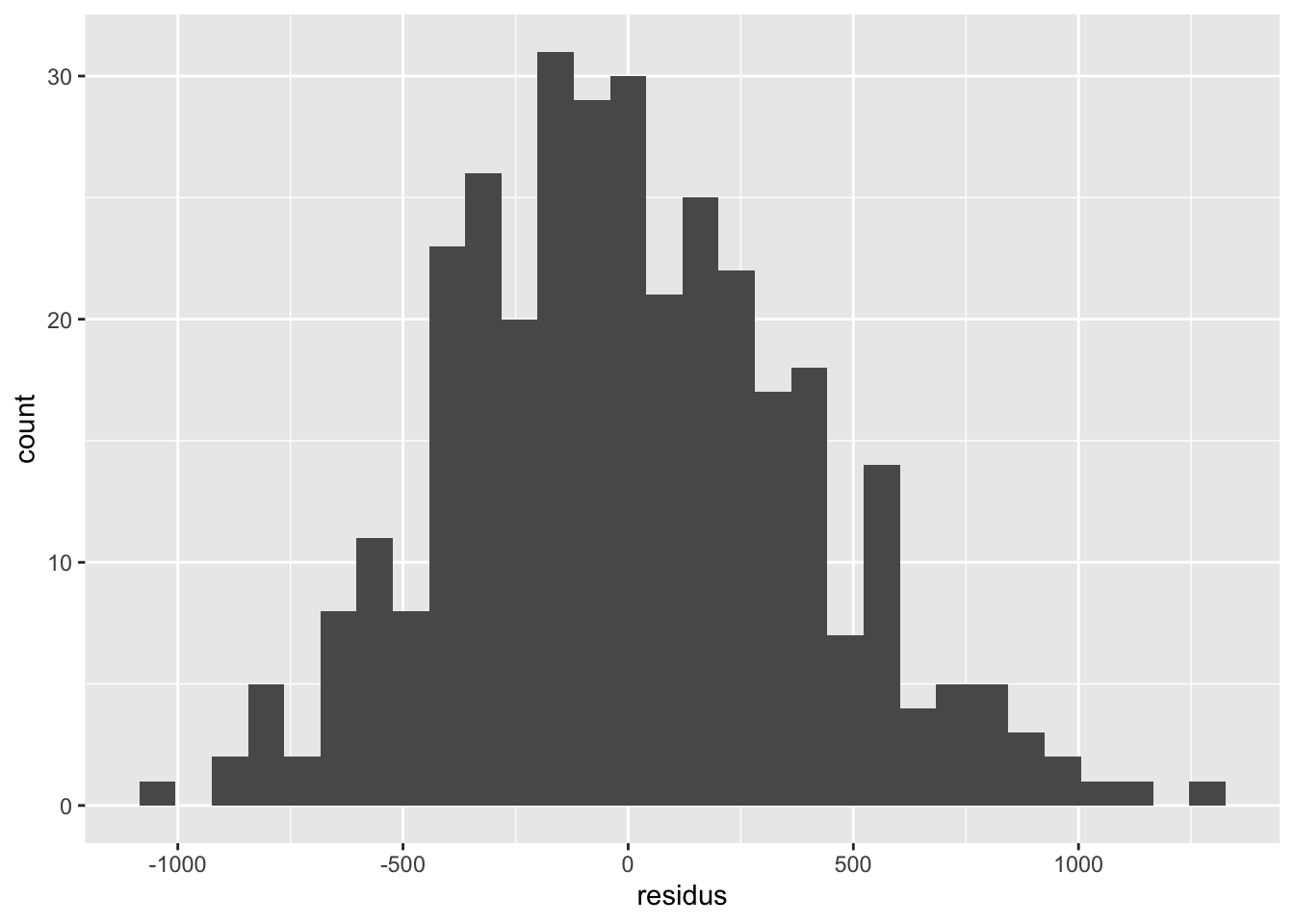
Avant d’aller voir quoi que ce soit dans nos résultats, il importe d’abord de bien valider notre modèle. Ajoutons donc d’abord pour se faire les chiffres qui nous seront nécessaires dans notre tableau de données, soit les résidus du modèle, les prédictions et les distances de Cook :
`stat_bin()` using `bins = 30`. Pick better value
`binwidth`.
Les résidus sont relativement normaux. Rien d’inquiétant de ce côté.
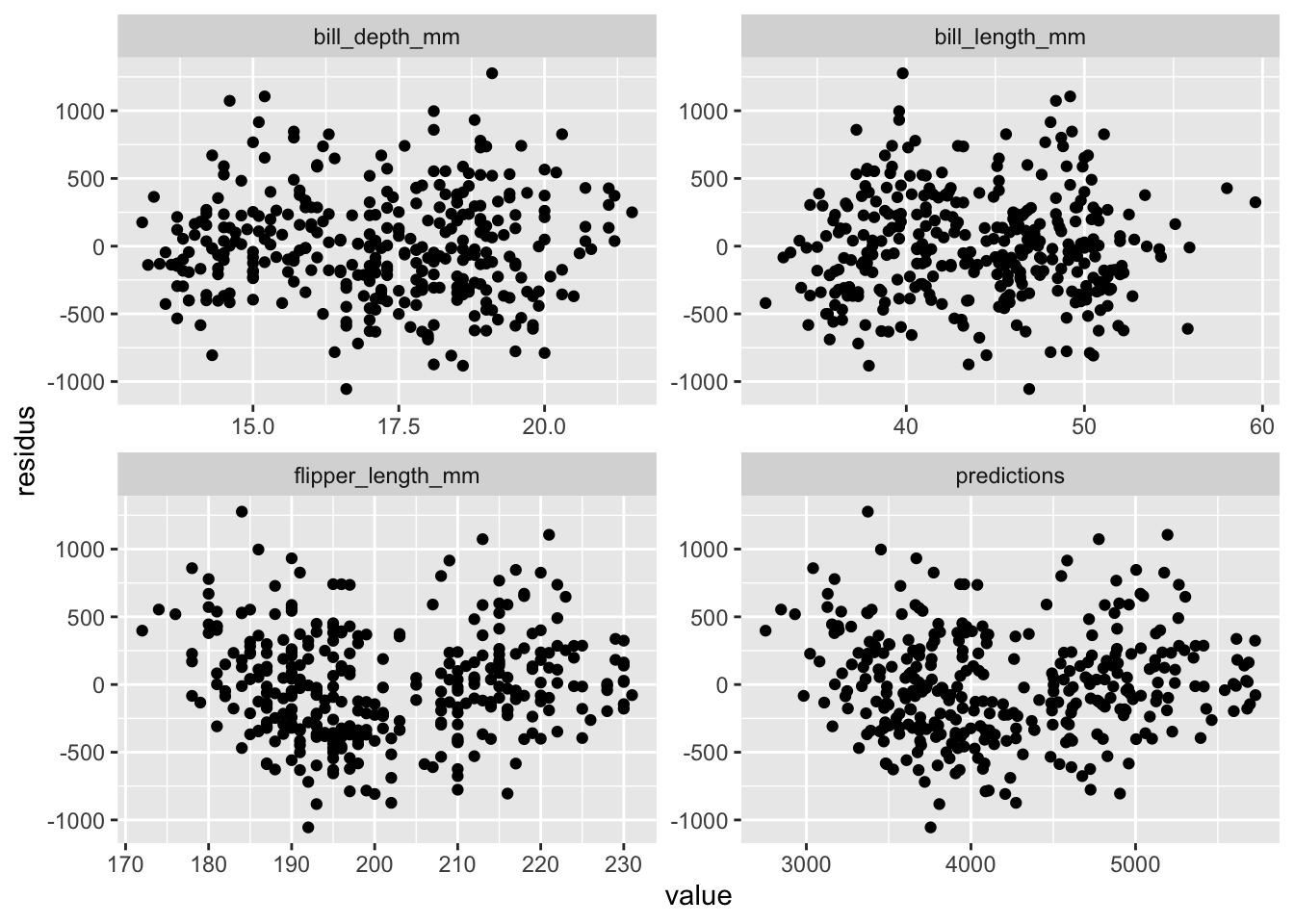
Ensuite, pour vérifier l’homogénéité des résidus, il faut, je le rappelle, faire un graphique des résidus en fonction de (1) les valeurs prédites et (2) chacune des variables entrées dans le modèle.
On pourrait faire chacun de ces graphiques individuellement, mais avec un peu de magie noire, sachez qu’il est aussi possible de faire tous ces graphiques en une seule commande :
À première vue, les quatre nuages de points sont relativement homogènes. Le modèle ne semble pas être pire sur la droite ou sur la gauche de chacun de ces graphiques.
Comme pour la régression linéaire, il est important de vérifier que nous n’avons pas d’observations individuelles qui pourraient venir biaiser nos résultats. La distance de Cook s’utilise exactement de la même façon avec la régression multiple, soit qu’il faut s’assurer qu’aucune valeur n’est plus grande que 1 :
pour_regression_multiple |>filter(D >1)
# A tibble: 0 × 11
# ℹ 11 variables: species <fct>, island <fct>,
# bill_length_mm <dbl>, bill_depth_mm <dbl>,
# flipper_length_mm <int>, body_mass_g <int>,
# sex <fct>, year <int>, residus <dbl>,
# predictions <dbl>, D <dbl>
Ici, pas de problèmes, aucune valeur >1
Enfin, il faut aussi valider l’assomption supplémentaire de la régression multiple, soit la colinéarité avec le VIF. Pour se faire, nous utiliserons la fonction vif provenant de la librairie car :
Toutes nos valeurs sont < 4, donc aucune inquiétude de ce côté.
Maintenant que tout cela est vérifié, on peut ENFIN regarder nos résultats :
summary(modele)
Call:
lm(formula = body_mass_g ~ flipper_length_mm + bill_length_mm +
bill_depth_mm, data = pour_regression_multiple)
Residuals:
Min 1Q Median 3Q Max
-1054.94 -290.33 -21.91 239.04 1276.64
Coefficients:
Estimate Std. Error t value
(Intercept) -6424.765 561.469 -11.443
flipper_length_mm 50.269 2.477 20.293
bill_length_mm 4.162 5.329 0.781
bill_depth_mm 20.050 13.694 1.464
Pr(>|t|)
(Intercept) <2e-16 ***
flipper_length_mm <2e-16 ***
bill_length_mm 0.435
bill_depth_mm 0.144
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 393.4 on 338 degrees of freedom
Multiple R-squared: 0.7615, Adjusted R-squared: 0.7594
F-statistic: 359.7 on 3 and 338 DF, p-value: < 2.2e-16
Remarquez que ces sorties sont très très semblables à celles que nous avons vues avec la régression simple. La seule différence est que le tableau Coefficients contient maintenant deux lignes supplémentaires. Notre modèle contient maintenant quatre paramètres, soit l’ordonnée à l’origine (Intercept) et les trois pentes pour les variables explicatives (longueur des ailes, longueur du bec et épaisseur du bec).
On peut donc constater qu’une seule pente est significativement différente de zéro (p<0,05). Le poids du corps augmente avec la longueur des ailes, mais les variables concernant le bec n’ont pas d’impact clair.
Comme une seule variable a un effet différente de zéro, nous n’avons pas vraiment besoin de standardiser les tailles d’effets pour voir laquelle a l’effet le plus fort. Pour les besoins de la cause, nous le ferons quand même pour que vous connaissiez la façon de le faire dans R.
Le plus simple est sans doute de refaire notre modèle en appliquant la fonction scale sur nos données. Comme notre tableau contient des variables qui ne sont pas numériques, on ne pas appliquer la fonction scale sur toutes les colonnes. On aurait pu évidemment simplifier notre tableau pour ne garder que ces dernières, mais on peut aussi utiliser un petit truc, pour appliquer la fonction scale uniquement sur les colonnes qui sont des chiffres (is.numeric).
Call:
lm(formula = body_mass_g ~ flipper_length_mm + bill_length_mm +
bill_depth_mm, data = mutate_if(pour_regression_multiple,
is.numeric, scale))
Residuals:
Min 1Q Median 3Q Max
-1.31546 -0.36203 -0.02733 0.29807 1.59191
Coefficients:
Estimate Std. Error t value
(Intercept) 1.056e-15 2.653e-02 0.000
flipper_length_mm 8.814e-01 4.343e-02 20.293
bill_length_mm 2.833e-02 3.628e-02 0.781
bill_depth_mm 4.937e-02 3.372e-02 1.464
Pr(>|t|)
(Intercept) 1.000
flipper_length_mm <2e-16 ***
bill_length_mm 0.435
bill_depth_mm 0.144
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4906 on 338 degrees of freedom
Multiple R-squared: 0.7615, Adjusted R-squared: 0.7594
F-statistic: 359.7 on 3 and 338 DF, p-value: < 2.2e-16
Remarquez dans ces sorties que les valeurs de p et le r2 sont absolument identiques à la sortie précédente. La seule chose importante qui a changé est l’échelle des estimés de paramètres (les colonnes Estimate et Std. Error).
On voit maintenant que pour chaque augmentation d’un écart-type de longueur d’aile, le poids du corps augmente de 0,88 écart-type. Presque du 1:1. À titre de comparaison, augmenter la longueur du bec d’un écart-type augmente le poids du corps que de 0,028 écart-type.
28.8 Contenu optionnel : Visualiser les pentes partielles
Nous avons discuté dans la section qui décrivait le modèle statistique que les pentes dans une régression multiple étaient en fait des pentes partielles. C’est-à-dire qu’elles décrivent un changement en Y pour un changement d’une de nos variables en X, en assumant que les autres variables ne bougent pas.
Il est possible de visualiser ces pentes partielles à l’aide de ce que l’on appelle un graphique des résidus partiels (partial residual plot). Dans ce dernier, on place comme à l’habitude notre variable explicative en X, mais en Y, plutôt que de mettre les valeurs de la variable expliquée, on place le résultat de l’addition de la pente de notre variable d’intérêt et des résidus du modèle. Cette passe-passe mathématique nous permet de recréer la pente partielle : ce que l’on met en Y sur le graphique est une recréation de nos données dans laquelle l’effet de toutes les autres variables a été éliminé.
Une des difficultés d’interprétation d’un graphique des résidus partiels vient du fait que l’échelle des Y est difficile à interpréter, puisque l’apport des autres variables est éliminé. C’est pourquoi, l’outil le plus commun pour visualiser les pentes partielles, soit la fonction visreg de la librairie du même nom, calcule plutôt un graphique conditionnel. Dans ce graphique, on a fait le calcul des résidus partiels, mais on intègre aussi au calcul l’apport des autres variables comme si elles étaient fixées à la médiane pour les quantitatives et au mode pour les catégoriques. Cette petite passe-passe permet de récupérer un axe des Y plus naturel à interpréter.
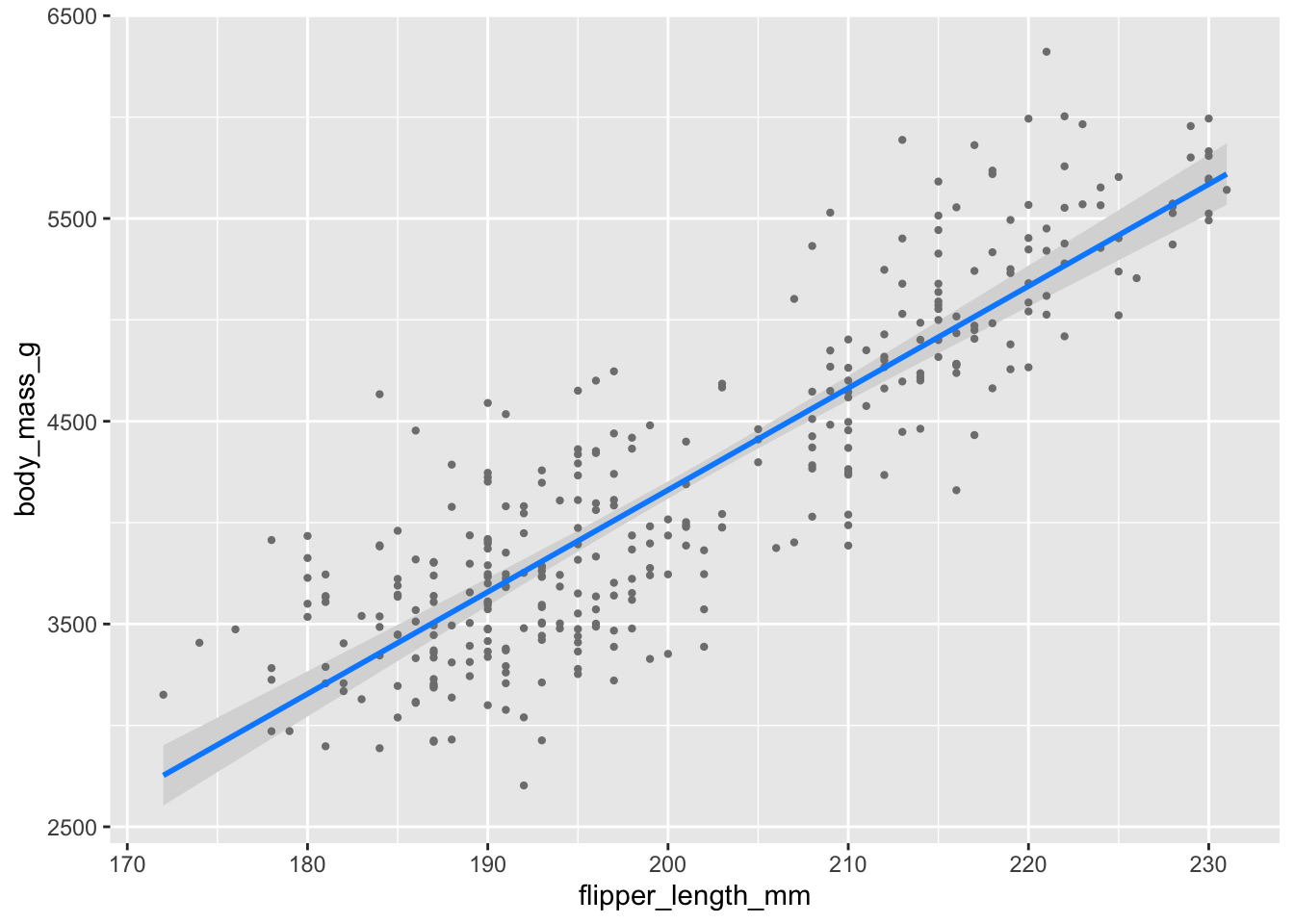
Voici par exemple le graphique des résidus partiels pour la longueur des ailes :
Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more
information.
ℹ The deprecated feature was likely used in the visreg
package.
Please report the issue to the authors.
Warning: Using `size` aesthetic for lines was deprecated in
ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
ℹ The deprecated feature was likely used in the
ggplot2 package.
Please report the issue at
<https://github.com/tidyverse/ggplot2/issues>.
Dans ce graphique, plutôt que d’avoir les vraies observations de poids en Y, on a une version simplifiée du poids, dans laquelle la variabilité attribuable aux autres variables a été enlevée. L’argument gg=TRUE est optionnel, mais informe la fonction que l’on veut obtenir un graphique compatible avec ggplot2, pour nous permettre d’ajouter des couches, de modifier les étiquettes, etc. comme on l’a fait ensemble depuis le début du cours.
28.9 Labo : Faire des prédictions
Pour faire des prédictions avec un modèle de régression multiple, on travaille exactement de la même façon qu’avec la régression linéaire, soit en appelant la fonction predict sur notre modèle et en lui fournissant un tableau avec les valeurs à prédire.
Avertissement
Ce n’est pas le cas ici, mais remarquez que si vous aviez transformé vos variables (p. ex. log) pour ajuster le modèle, il faut aussi transformer les données avant de les utiliser pour faires des prédictions.
Si on voulait par exemple prédire le poids d’un manchot avec des ailes de 220 mm, un bec long de 39 mm et 18 mm d’épais, on ferait ceci :
Toutes les intervalles de confiance décrites au Chapitre 18 fonctionnent exactement de la même façon aussi.
28.10 Labo : La régression polynomiale
Vous avez peut-être remarqué que nous n’avons PAS parlé ici du fait que la linéarité est une assomption de la régression multiple. La raison est simple : la régression linéaire peut ajuster d’autres formes de relations que de simples droites!
Nous avons tout d’abord vu dans le chapitre sur les transformations (Section 9.3) que l’on peut, par exemple, linéariser une relation avec une transformation log-log. Dans les faits, la relation n’était pas linéaire, mais nous la transformons pour y arriver.
Une autre stratégie souvent utilisée est d’intégrer des termes polynomiaux à notre régression linéaire. Maintenant que nous savons que la régression peut contenir plusieurs termes, il est intéressant de savoir qu’elle peut aussi contenir le même terme, avec différents exposants. On pourrait par exemple tenter d’ajuster une polynomiale de degré trois comme ceci:
\[y = \beta_0 + \beta_1x+\beta_2x^2+\beta_3x^3\]
Comme nous n’avons pas de données prêtes à tester ce genre de modèles, nous allons nous créer un tableau avec de fausses données pour essayer :
Et maintenant, essayons de nous créer un modèle de régression multiple pour voir si nous réussissons à récupérer les valeurs de nos paramètres :
m <-lm(y~x+I(x^2)+I(x^3), data = fausses)
Avertissement
Remarquez que nos termes polynomiaux doivent être emballés dans la fonction I(). Si on ne le fait pas, R interprétera mal ce que l’on veut faire, mais ne fera PAS de message d’erreur pour nous avertir!
summary(m)
Call:
lm(formula = y ~ x + I(x^2) + I(x^3), data = fausses)
Residuals:
Min 1Q Median 3Q Max
-0.25268 -0.06992 0.01042 0.05607 0.26723
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 9.96129 0.02728 365.15 <2e-16 ***
x 2.08659 0.11842 17.62 <2e-16 ***
I(x^2) -3.09746 0.13779 -22.48 <2e-16 ***
I(x^3) 1.03715 0.04528 22.91 <2e-16 ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.09826 on 196 degrees of freedom
Multiple R-squared: 0.8824, Adjusted R-squared: 0.8806
F-statistic: 490.4 on 3 and 196 DF, p-value: < 2.2e-16
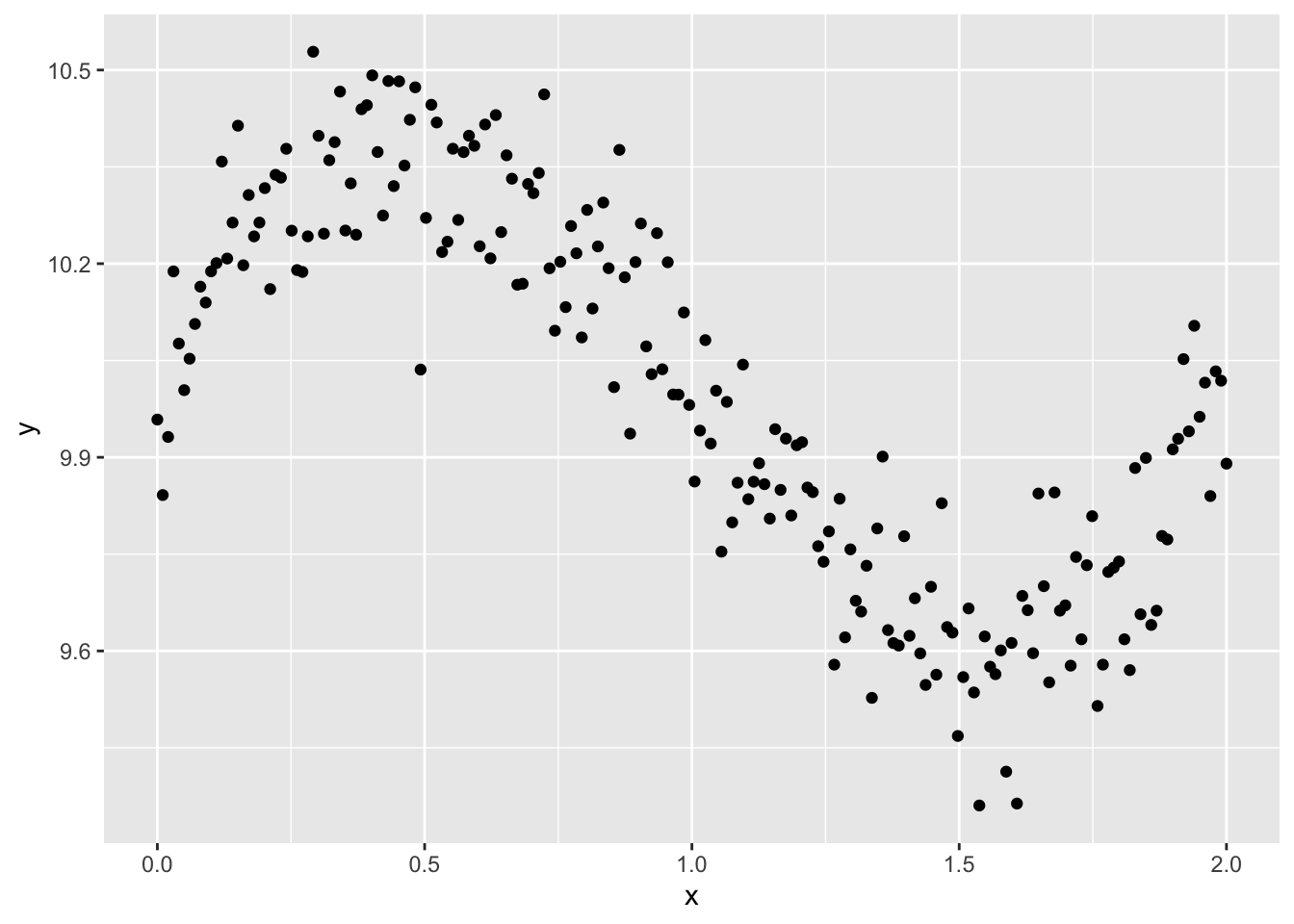
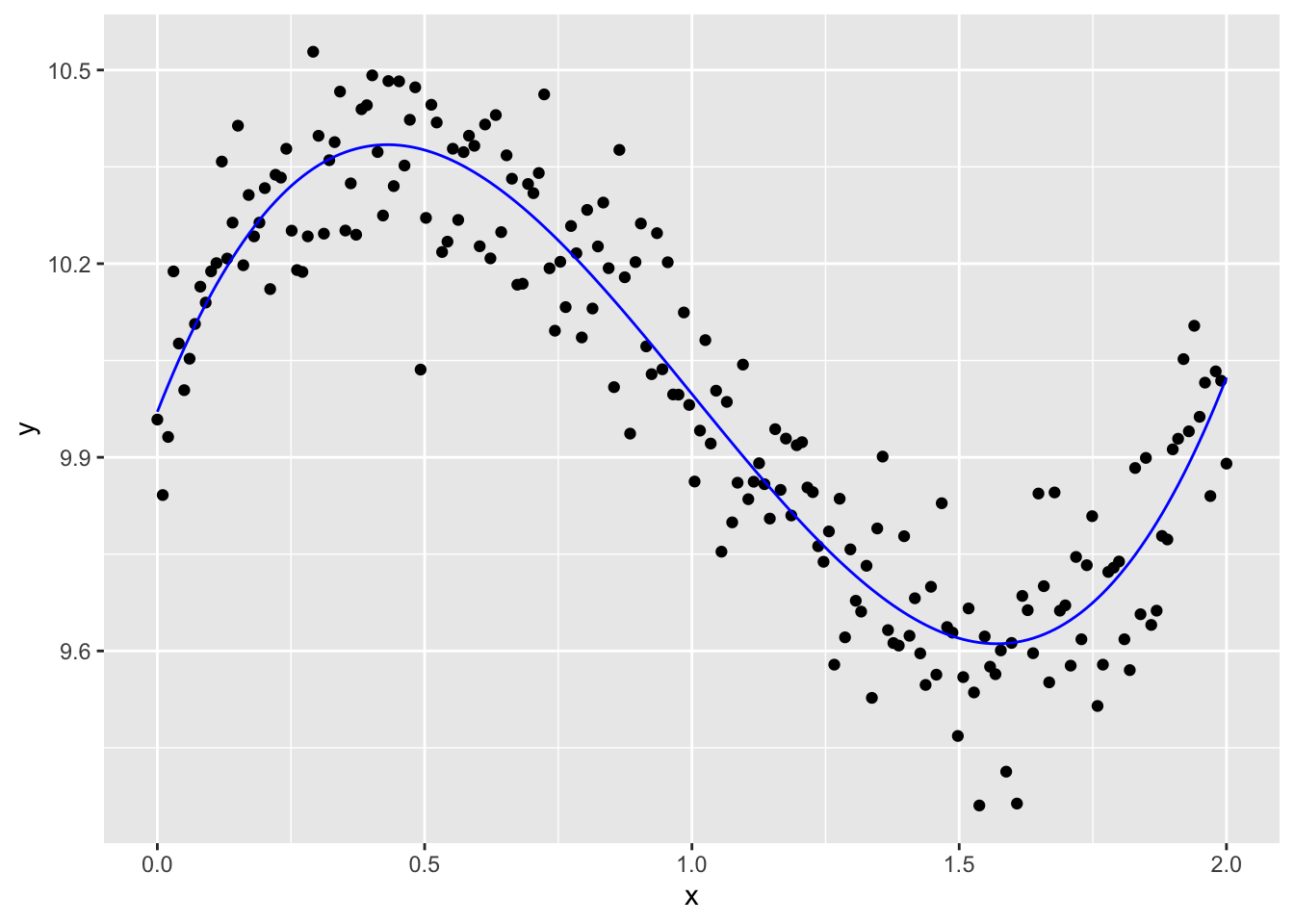
Les coeffcients que nous avons récupéré sont très près des originaux, soit 9,97 vs 10, 2,18 vs 2, -3,22 vs -3 et 1,07 vs 1.
On peut constater le bel ajustement de ce modèle avec un graphique :
fausses |>mutate(predictions =predict(m)) |>ggplot(aes(x,y)) +geom_point() +geom_line(aes(y=predictions), color ="blue")
Remarquez qu’en général, tester un modèle avec de fausses données comme nous l’avons fait ci-haut est une excellente stratégie pour comprendre les limites de nos outils.
Avertissement
Attention, vos relations non-linéaires n’aurons pas nécessairement besoin d’une polynomiale de degré 3. Parfois, une degré 2 suffira (i.e. \(y = \beta_0 + \beta_1x+\beta_2x^2\))
Note
Remarquez aussi que l’on peut combiner plusieurs variables dans un même modèle, avec ou sans des termes polynomiaux.
Par exemple, si on sait qu’un espèce a un optimal de température (et donc, son abondance devrait suivre une courbe en cloche selon cette variable) et répond de façon linéaire à la quantité de proies (plus on a de proies, plus on a d’abonance), on pourrait ajuster le modèle suivant :
Nous allons travailler pour cet exercice avec un jeu de données où l’auteur (Loyn, 1987) a tenté de modéliser l’abondance d’oiseaux dans des parcelles forestières, à partir de variables mesurées à l’échelle du paysage entourant la parcelle. Le jeu de données peut être récupéré ici en format CSV1.
Pour cet exercice, nous tenterons de déterminer quels sont les facteurs affectant l’abondance d’oiseaux (ABUND), parmi les suivants :
AREA : la surface de la parcelle en hectares
YR.ISOL : l’année depuis laquelle la parcelle est isolée
DIST : distance (km) à la parcelle la plus proche
ALT : l’altitude de la parcelle (m au-dessus du niveau de la mer)
Vous verrez qu’à partir de maintenant, vous passerez beaucoup plus de temps à préparer et vérifier vos données et les assomptions des modèles plutôt qu’à faire des statistiques comme tel. Pour vous guider dans votre exercice, assurez-vous d’effectuer toutes les étapes suivantes dans votre modélisation :
Chargement et vérification des données
Préparation des variables (enlever les colonnes inutiles, les données manquantes, transformer les données si nécessaire)
Ajustement du modèle
Vérification du modèle
Interprétation des résultats
Une fois votre modèle prêt, essayez de l’utiliser pour prédire l’abondance d’oiseaux que l’on pourrait trouver dans une parcelle de 100 ha, isolée depuis 1985, à 5 km de la parcelle la plus proche et à une altitude de 150 m au-dessus du niveau de la mer. Produisez aussi l’intervalle à 95 % de cette prédiction. Autrement dit, 95 % du temps, entre quelles valeurs devrait se situer l’abondance d’oiseaux dans une telle parcelle.