Le Chapitre 3 nous a permis de mettre en place différentes façons de voir les données. Lorsque nous désirons comprendre nos données, il est primordial de commencer par cette étape de visualisation. Il est néanmoins utile (et parfois même nécessaire) de pouvoir mettre des chiffres sur ce que l’on voit. Le présent chapitre sera donc dédié à la description des données par des chiffres.
5.1 Mesures de tendance centrale
La tendance centrale est un terme technique pour dire de façon plus simple : autour de quelle valeur tournent nos chiffres. Cela peut sembler anodin, mais il existe en fait plusieurs façons d’y arriver.
Pour une variable quantitative, la façon la plus simple pour décrire cette tendance centrale est la médiane. La médiane consiste à déterminer quel est le point milieu de nos données. Nous avons, par définition, 50 % de nos observations qui sont plus petites que la médiane et 50 % qui sont plus grandes. Pour calculer la médiane, il faut trier nos observations par ordre de grandeur. Ensuite, si notre nombre de données est impair, la valeur de la médiane est la valeur en plein centre. Si notre nombre d’observations est pair, la médiane est le point milieu entre les deux nombres les plus au centre.
Si nous avions mesuré les nombres [5, 4, 3, 10, 2], la médiane serait de de 4, et si on avait mesuré [5,4,3,10], elle serait de 4,5.
L’autre façon intuitive de décrire la tendance centrale des données est de calculer la moyenne. Ce que nous appelons couramment “moyenne” est en fait la moyenne arithmétique. Sachez qu’il existe aussi la moyenne géométrique (où l’on multiplie les nombres plutôt que les additionner), mais nous n’entrerons pas dans ces détails ici. Pour calculer la moyenne, il faut faire la somme de toutes nos données, puis diviser par le nombre de données.
La moyenne possède plusieurs propriétés intéressantes, entre autres le fait que multiplier la moyenne par le nombre de données, nous redonne toujours la somme des données originales (ce qui n’est pas le cas pour la médiane).
Par contre, la moyenne est plus sensible aux données extrêmes que la médiane. Si vous prenez la suite de nombre suivants : [1, 2 , 3 , 4 , 5 , 6 , 7 , 9 , 1000], la moyenne de ces données sera de 115,2, alors que la médiane sera de 5.
En général, si il n’y a pas de données extrêmes pour tirer la moyenne d’un côté ou l’autre, la moyenne est un meilleur indicateur de tendance centrale, mais en cas d’asymétrie (un côté clairement différent de l’autre), la médiane devient plus intéressante.
Pour les variables catégoriques, vous conviendrez avec moi qu’il est difficile de faire des additions et des divisions! C’est pourquoi, pour ce type de variables, la tendance centrale est habituellement définie par le mode. Le mode se trouve en déterminant la valeur la plus commune d’une variable. Par exemple, si une variable contient les valeurs [“A”, “B”, “A”, “B”, “B”], le mode de cette variable sera “B”.
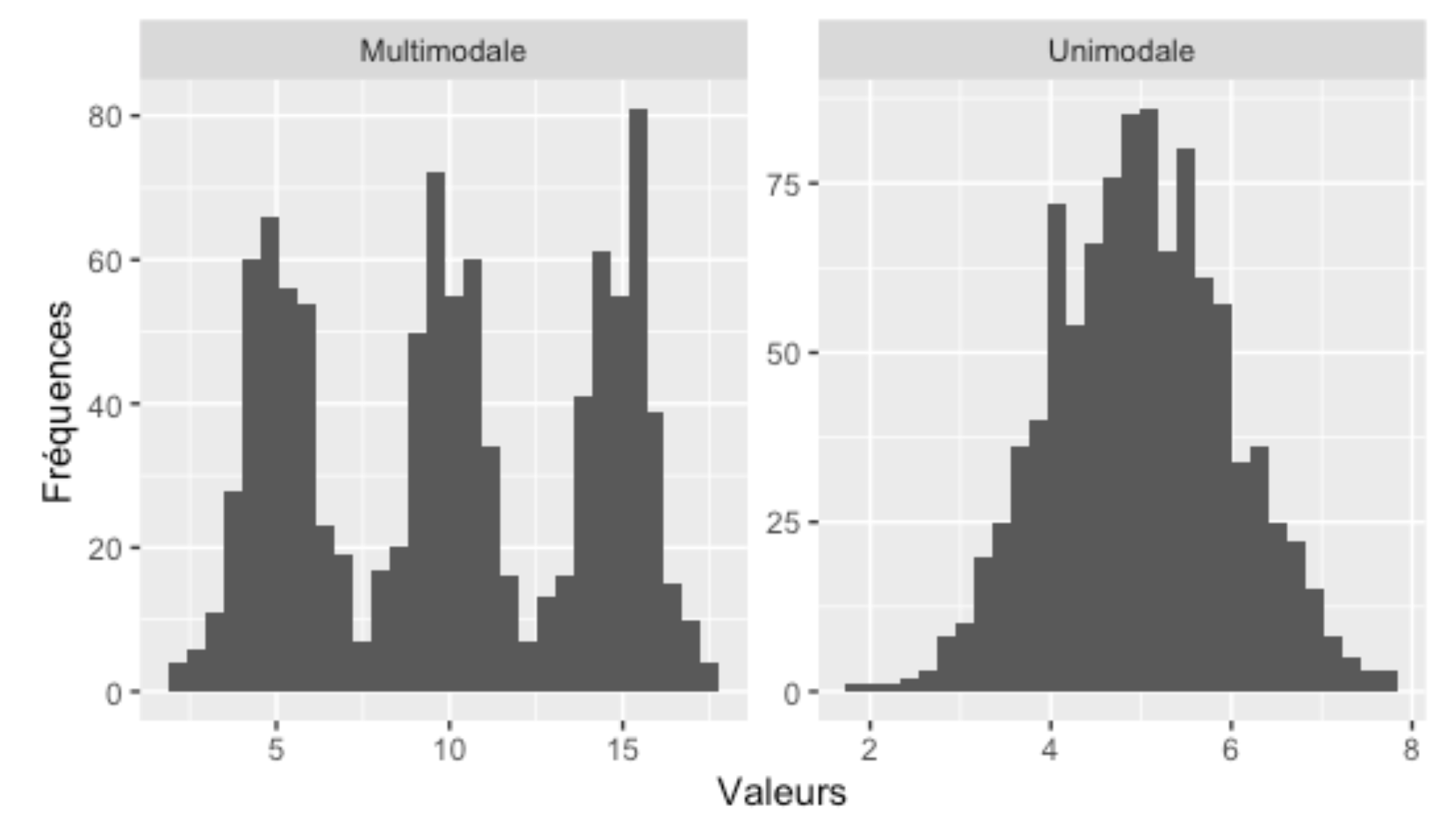
Le mode peut être aussi utile pour décrire ce que l’on voit dans un histogramme de fréquences. Puisque les données sont groupées en catégories, le mode de l’histogramme sera la bande dans laquelle il y aura le plus d’observations.
On peut aussi étendre la définition du mode, pour nous informer sur la forme d’une distribution dans un histogramme, à savoir si ce dernier est multimodal (plusieurs modes) ou unimodal (un seul mode).
Notez qu’il faut utiliser notre jugement pour déterminer quels sont les modes et quelles sont des variations normales de forme de l’histogramme puisque la nature est variable.
5.2 Mesures de variabilité (syn. dispersion)
Une fois que nous avons pu décrire la tendance centrale de nos données, l’autre aspect dont nous discuterons abondamment est la variabilité de ces données, c’est-à-dire combien les observations sont différentes les unes des autres. On parle aussi souvent de dispersion des données (autour de la moyenne).
La façon la plus simple de définir la variabilité des données est d’en mesurer l’étendue. On calcule l’étendue en trouvant la valeur la plus élevée et en lui soustrayant la valeur la plus faible. L’étendue est très simple à calculer et à interpréter : c’est la différence entre la plus grande et la plus petite valeur.
Par contre, elle possède aussi un sérieux handicap. De façon probabiliste, plus nous avons d’observations dans notre tableau de données, plus l’étendue sera grande, ce qui est un grave problème, qui rend complexe l’utilisation de cette mesure pour comparer divers jeux de données.
Pour contourner ce problème, les scientifiques calculent en général la variance de leurs données pour décrire leur variabilité. La variance peut être décrite comme la moyenne des distances à la moyenne, au carré. C’est un concept un peu abstrait auquel il vaut la peine de s’attarder, parce qu’il reviendra fréquemment. Voici d’ailleurs notre première formule mathématique : \[
\sigma^2 = \sum_{i=1}^n \frac{ (x_i-\bar{x})^2 }{n-1}
\] Puisqu’il s’agit de notre première équation ensemble, prenons le temps de la décortiquer. \(\sigma^2\) se prononce sigma au carré, il s’agit du symbole de la variance d’un échantillon (nous reviendrons plus tard sur le concept d’échantillon). \(\Sigma\) (aussi sigma, mais cette fois-ci majuscule) représente une somme. Le \(i=1\) en dessous nous informe que nous devons démarrer notre somme à la première observation de nos données et le petit \(n\) nous informe d’arrêter à la dernière (\(n\) étant le nombre d’observations). Autrement dit, répéter la partie de droite pour chacune des valeurs et faire la somme de tout ça. Dans la partie de droite, \(x_i\) signifie : pour la valeur de x à laquelle nous sommes rendus (on dit parfois la ième valeur). Enfin, \(\bar{x}\) se prononce généralement “x-barre” et représente la moyenne de la variable x.
Donc, si l’on résume la formule : on calcule d’abord la moyenne de x. Ensuite, pour chacune des valeurs de x, on leur soustrait la moyenne. On met ces différences au carré, et on les divise par n-1. Ensuite, quand on a toutes ces valeurs, on en fait la somme. On obtient ainsi la variance.
Si nous avons par exemple les nombres [2, 4, 6]. La première étape est de calculer la moyenne, qui sera de 4. Ensuite, pour chaque nombre on lui soustrait la moyenne [2, 4, 6] - 4 = [-2, 0, 2]. Ensuite, on met chacun des nombres au carré, ce qui devient [4, 0, 4]. Ensuite, on divise chaque nombre par n-1 (donc 2), ce qui devient [2, 0, 2]. Enfin on les additionne pour obtenir une variance de 4.
Plus les valeurs sont différentes de la moyenne, plus la variance sera élevée. P. ex. ces deux séries de nombres ont la même moyenne : [-1, 0, 1] et [-10, 0, 10] soit zéro, mais leurs variances sont respectivement 1 et 100.
Comme discuté précédemment, l’avantage de la variance est qu’elle n’est pas affectée systématiquement par la taille de l’échantillon. Cependant, elle présente aussi un problème majeur au niveau de l’interprétation, soit que ses valeurs sont au carré. Si p. ex. nous mesurons le poids de 3 oiseaux en grammes et obtenons [20, 22, 26], la variance du poids de nos oiseaux sera de 9,33 gramme2 (e.g. grammes-carrés). Difficile de se représenter mentalement un “gramme-carré” n’est-ce pas? C’est gros ou pas 9 grammes-carrés?
C’est pourquoi, pour discuter de la variabilité des données, on utilise généralement l’écart-type (\(\sigma\)), qui est défini comme la racine-carrée de la variance. L’écart-type possède la même robustesse au nombre d’observations que la variance, mais il est lui à la même échelle que les données, donc beaucoup plus facile à interpréter. Dans notre exemple précédent, l’écart-type du poids de nos oiseaux serait de 3,06 grammes.
5.3 Asymétrie
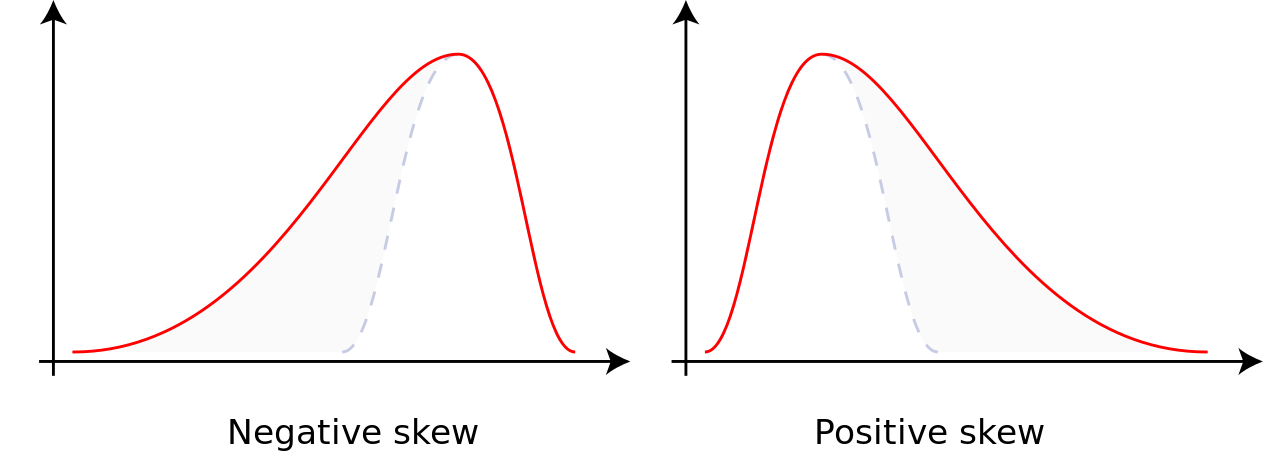
L’asymétrie d’une distribution (si elle est étirée à droite ou à gauche) peut aussi se quantifier, à l’aide d’un chiffre nommé le coefficient d’asymétrie (skew). Nous n’entrerons pas dans les détails de ce calcul. La chose importante à savoir pour le moment est qu’un coefficient positif est associé à une longue queue à droite, et qu’un coefficient négatif est associé à une longue queue à gauche.
De la même façon, il existe aussi une façon de mesurer combien une distribution est pointue ou aplatie. Cette caractéristique se mesure à l’aide du coefficient d’aplatissement (kurtosis). Un coefficient d’aplatissement > 3 possède plus de données au centre (plus pointue) qu’une distribution normale. On parle d’une courbe leptokurtique. Un coefficient d’aplatissement < 3 est plus aplatie qu’une distribution normale (nous expliquerons plus en détail la loi normale au Chapitre 11), on parle alors de courbe platikurtique.
5.4 Labo : Décrire les données dans R
La plupart des descripteurs de données définis ci-dessus sont prêts à être utilisés dans R, à l’exception du coefficient d’asymétrie et du coefficient d’aplatissement, que nous ne ré-utiliserons de toute façon pas dans le restant de ce livre. Voici comment les calculer pour la variable body_mass_g de notre base de données penguins :
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Remarquez que pour calculer la médiane, vous n’avez pas besoin de trier les données au préalable, la fonction median s’en occupe elle-même pendant son calcul.
5.5 Exercice : Intuitions quant aux descripteurs de données
Voici les observations concernant trois variables :
A = [0, 5, 10, 15, 20]
B = [10, 15, 20, 25, 30]
C = [8, 9, 10, 11, 12]
Répondez aux questions suivantes, d’abord par intuition (i.e. sans effectuer de calcul).
Laquelle de ces variables possède la moyenne la plus élevée?
Laquelle de ces variables possède la variance la plus élevée?
Laquelle de ces variables possède l’écart-type le plus élevé?
Quelle est la médiane de chacune des trois variables?
Laquelle de ces variables possède l’étendue la plus petite?
Puis validez vos réponses à l’aide d’un calcul manuel (i.e. avec votre calculatrice).
Ensuite, lancez le code suivant dans R pour créer un tableau de données contenant ces 3 variables :
Enfin, en adaptant le code de la section Section 5.4, calculez la moyenne, la médiane, la variance et l’écart-type de chacune de ces variables. Vos résultats devraient être identiques à ceux calculés manuellement…
.svg){kind=link}