Nous avons souvent discuté qu’une assomption importante de l’ensemble des modèles statistiques vus jusqu’à maintenant était que les données avaient été récoltées de façon indépendante. Étonnamment, dans la vraie vie d’une biologiste, nos observations sont rarement parfaitement indépendantes. On mesure plusieurs arbres dans une même parcelle, on prend plusieurs profils de températures dans le même lac, etc.
Nous avons plusieurs fois discuté du fait que si l’on entre des observations non-indépendantes dans un modèle, cela viendra exagérer notre certitude sur nos inférences, fausser nos valeurs de p et possiblement biaiser nos résultats. Nous risquons plus souvent de commettre des erreurs de type I, puisque le n effectif (le nombre d’observations réellement indépendantes) de notre analyse est dans les faits plus petit que celui utilisé pour faire les calculs.
Pendant longtemps, la seule solution possible à cette problématique a été d’agréger nos données. Plutôt que d’utiliser 4 observations pour un même lac, on calculait la moyenne des 4 observations, et on utilisait cette valeur moyenne pour le lac entier. Cela règle le problème d’indépendance des observations, mais on gaspille aussi beaucoup de nos données, sans compter le fait qu’on perd de l’information sur la variabilité à l’intérieur de chaque lac.
Heureusement, depuis une vingtaine d’années, les modèles linéaires mixtes permettent de gérer ce problème de façon élégante et efficace. C’est de cette technique dont il sera question dans ce chapitre.
32.2 L’équation complète de la régression linéaire
Avant de s’attaquer aux modèles mixtes, nous devrons d’abord compléter l’équation que nous avons utilisée pour décrire la régression linéaire et la régression multiple. Jusqu’à maintenant, nous avions décrit la régression linéaire comme ceci :
\[
y=b_0+b_1x_1...+b_px_p
\]
Hors, cette façon de décrire est une version simplifiée, que nous devrons compléter avant de pouvoir passer aux modèles mixtes.
La première chose que nous devrons faire est de clarifier que cette équation s’applique pour chacune de nos observations. L’ajout de l’indice i aux termes y, x1 et xp nous permettra d’accomplir cela :
\[
y_i=b_0+b_1x_{1,i}+ ... + b_px_{p,i}
\]
Il est maintenant plus clair que cette équation s’applique ligne par ligne (i=1 … i=n) dans notre tableau de données.
Ensuite, si on prend quelques secondes pour réfléchir à cette formulation, on réalise que l’égalité n’est pas complète. Le modèle à droite n’est pas exactement égal au y à gauche. Notre modèle devrait aussi comprendre un résidu, que l’on peut écrire comme ceci :
Autrement dit, la valeur observée de y est égale à l’ordonnée à l’origine, plus une pente partielle pour chaque variable, plus un terme d’erreur associé à chaque observation (le résidu).
Enfin, pour terminer, on pourrait ajouter une seconde équation à cette définition, soit la notation mathématique indiquant que les résidus sont distribués normalement, avec une moyenne de zéro et un écart-type de sigma, comme ceci :
\[
\epsilon_i \sim N(0,\sigma^2_\epsilon)
\]
32.3 Ordonnées à l’origine aléatoires
Pour bien comprendre les effets aléatoires, nous allons discuter d’un exemple où l’on aurait voulu mesurer, comme pour la régression linéaire, la relation entre la surface d’un parc et la richesse en espèces d’oiseaux qu’on y retrouve. L’équation de cette relation pourrait être écrite comme ceci :
\[
Richesse_i=b_0+b_1Surface_i+\epsilon_i
\]
Or, après avoir planifié l’expérience, on réalise que les parcs sont organisés par villes (4 parcs dans la ville A, 2 parcs dans la ville B, etc.). Comme on sait que le mode de gestion des parcs par chacune des villes peut avoir un impact sur le nombre d’espèces d’oiseaux, on réalise rapidement que nos données ne sont pas entièrement indépendantes. Elles sont organisées de façon hiérarchique.
Une première chose que l’on pourrait vouloir est de permettre à l’ordonnée à l’origine de notre modèle de varier en fonction de la ville où le parc se situait. Comme cela, si une ville a tendance à avoir plus d’oiseaux qu’une autre, notre modèle pourra en tenir compte. On écrirait donc ce nouveau modèle comme ceci :
Le problème avec un tel modèle est que l’on ajuste autant de paramètres que le nombre de villes - 1, même si au fond, cet effet de la ville ne nous intéresse pas vraiment. On veut que notre modèle en tienne compte dans son calcul, mais on ne s’intéresse pas à savoir si la ville A est meilleure que la ville B, etc.
Le modèle avec ordonnée à l’origine aléatoire nous permet d’éviter d’ajuster un paramètre pour chacune des villes, en ajoutant la contrainte que les ordonnées à l’origine de chaque ville suivent une distribution normale définie comme ceci :
\[
a_i\sim N(0,\sigma_a^2)
\]
Notre modèle contient donc maintenant deux termes d’erreur normalement distribués, un pour les résidus et un pour les différences entre les villes.
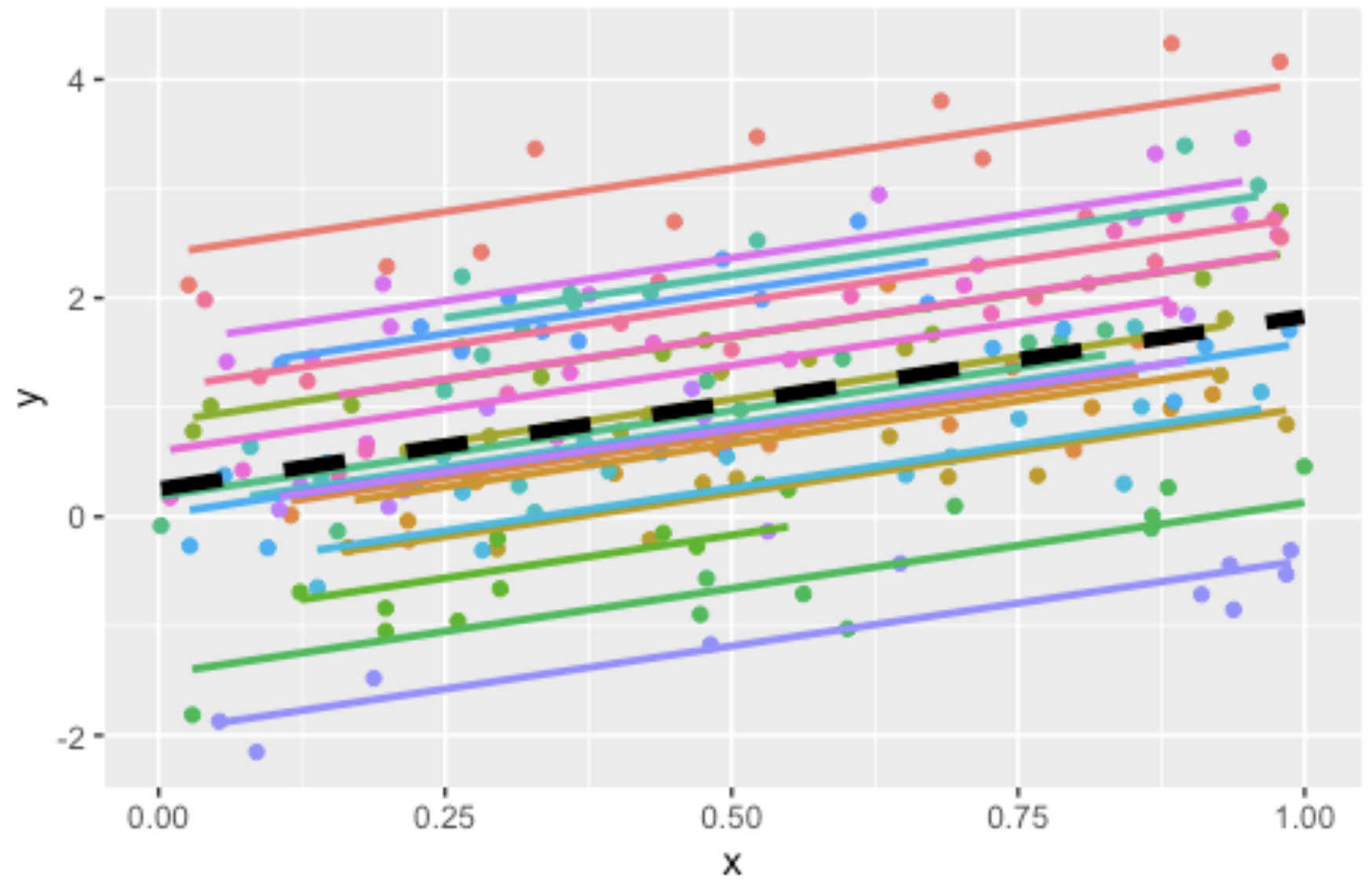
Visuellement, notre modèle ajusterait quelque chose de semblable à ceci :
Où la ligne noire pointillée représente les paramètres de pente et d’ordonnée à l’origine, et chacune des lignes de couleur représente les ordonnées à l’origine individuelles de chacune des villes, qui suivent une distribution normale, entre elles. Beaucoup de pentes sont très près de la pente globale, et peu de pentes en sont fortement éloignées.
À ce point-ci, vous vous demandez peut-être quel est le gain en termes d’ajustement si notre modèle a tout de même à estimer une ordonnée à l’origine par groupe. La clé est qu’il n’a pas à le faire. Plutôt que de chercher la meilleure valeur pour chacune des ordonnées à l’origine, il cherche seulement à estimer la meilleure valeur pour leur variance (\(\sigma_a^2\)). Les valeurs des ordonnées à l’origine apparaissent dans le modèle, mais le modèle ne travaille pas spécifiquement pour les trouver.
32.4 Corrélations intra-classe
Puisque la prémisse des modèles mixtes est que les observations à l’intérieur d’un groupe se ressemblent entre elles, il peut être intéressant de savoir jusqu’à quel point elles le sont. De pouvoir mettre un chiffre sur cette ressemblance. C’est pourquoi les statisticiens ont inventé le coefficient de corrélation intra-classe (ICC; intraclass correlation coefficient). Dans un modèle simple, à un seul effet aléatoire comme celui ci-haut, ce coefficient peut être calculé comme ceci :
Autrement dit, l’ICC est la variance de l’effet aléatoire, divisée par la somme des variances de l’effet aléatoire et des résidus. Ce coefficient sera toujours entre 0 et 1.
Un ICC de 0 nous dirait que les observations à l’intérieur d’un même groupe sont aussi différentes que si elles provenaient de groupes différents. Un ICC de 1 nous dirait que les observations à l’intérieur d’un même groupe sont parfaitement identiques.
L’ICC peut s’interpréter comme un R2, mais qui nous indique la proportion de variance expliquée par l’effet aléatoire de notre modèle.
Dans des modèles avec des structures d’effets aléatoires plus complexes comprenant par exemple plusieurs niveaux, la définition de l’ICC est loin d’être aussi simple et son calcul dépasse ce qu’il est réaliste de voir dans ce cours …
32.5 Pentes aléatoires
Une fois l’ordonnée à l’origine aléatoire ajoutée au modèle, on pourrait se poser la question : est-ce uniquement l’ordonnée à l’origine qui varie entre les villes, ou la pente (i.e. la nature de la relation) pourrait aussi varier?
Dans la plupart des cas, la question sera légitime. Ici, par exemple, si les pratiques d’une ville peuvent ajouter ou soustraire des espèces d’oiseaux dans chacun des parcs, leurs pratiques peuvent probablement aussi influencer l’effet d’ajouter un hectare supplémentaire à un parc existant.
Pour tenir compte de cette possibilité, il convient d’ajouter un terme d’interaction (ci) entre la ville et la surface dans notre modèle, comme ceci :
Mais, tout comme la valeur d’ordonnée à l’origine associée à chaque ville ne nous intéresse pas directement, la valeur associée à la différence de pente pour chaque ville ne nous intéresse pas non plus. On peut donc placer cette interaction en effet aléatoire, en spécifiant que les termes d’interaction seront aussi distribués de façon aléatoire, suivant une distribution normale, comme ceci :
\[
c_i\sim N(0,\sigma_c^2)
\]
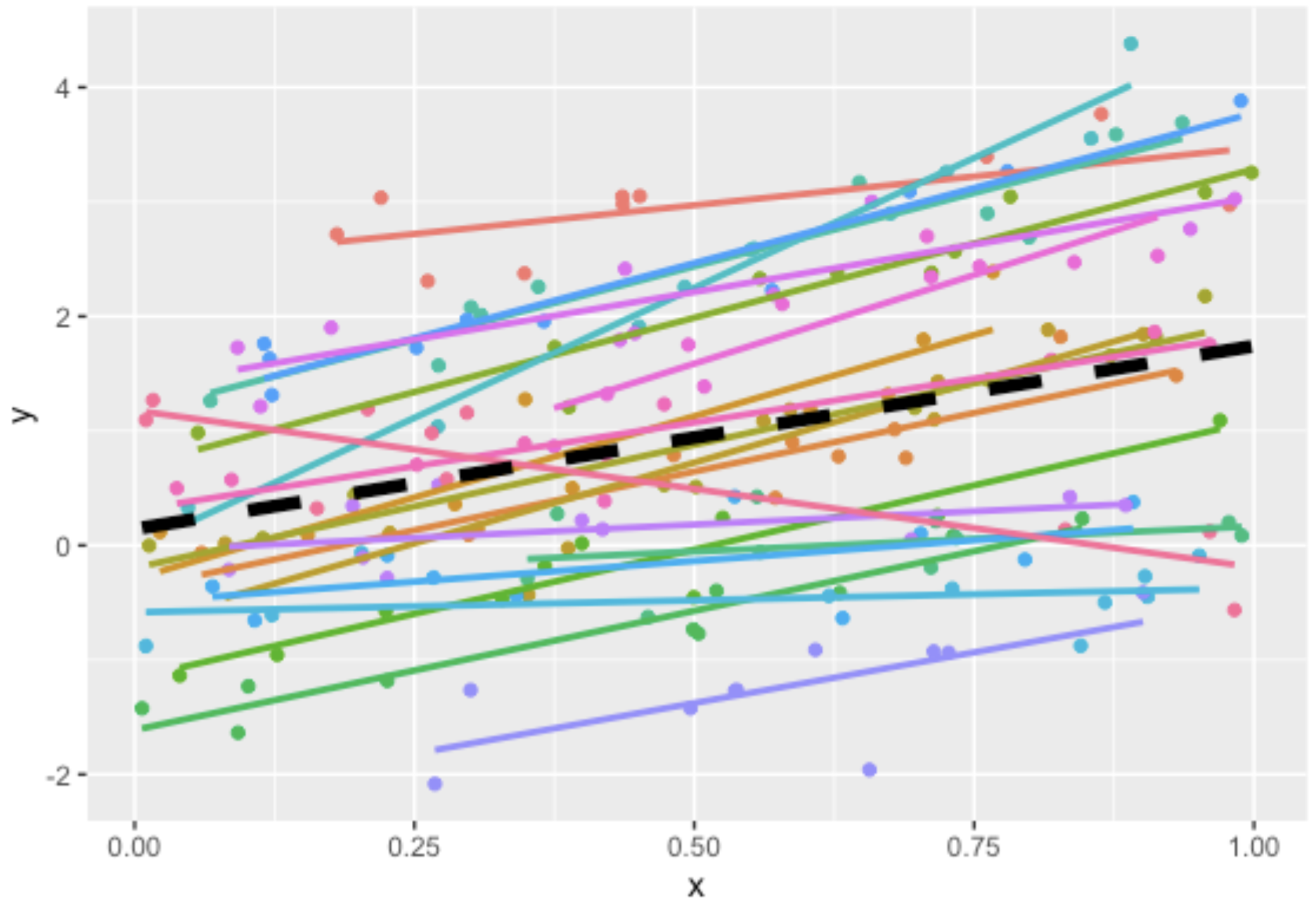
Visuellement, notre modèle ressemble maintenant à la figure ci-dessous. Il contient une pente et une ordonnée à l’origine globale, mais aussi, pour chacun des groupes, une pente et une ordonnée à l’origine, dont les valeurs suivent chacune une distribution normale.
32.6 Nuances sur les techniques d’ajustement
Contrairement à la régression linéaire multiple, un modèle linéaire mixte ne peut pas être ajusté à partir d’une opération d’algèbre matriciel. Il doit passer par un processus itératif qui se rapproche progressivement de la solution qui maximise la vraisemblance du modèle. Encore une fois, les détails ici ne sont pas si importants, mais la vraisemblance d’un modèle est la probabilité qu’on ait observé les données pour des valeurs de paramètres en particulier. Le processus d’ajustement essaie des valeurs pour chacun de nos paramètres, jusqu’à arriver à la solution la plus vraisemblable, i.e. la plus probable étant donné les données observées.
Il n’existe malheureusement pas de solution parfaite pour effectuer ce processus. Les deux techniques existantes sont la vraisemblance maximale (Maximum Likelihood; ML) et la vraisemblance maximale restreinte (Restricted Maximum Likelihood; REML). Vos collègues, directrices, etc. utiliserons probablement les abréviations anglaises de ces termes (i.e. ML et REML) et nous ferons donc de même ici.
La différence importante à savoir entre les deux techniques est la suivante :
Important
Les composantes de variance estimées par la technique ML seront biaisées, mais les estimés de paramètres seront fiables. Au contraire, la REML fournira des composantes de variances exactes, mais, parce qu’elle utilise une transformation des données pour y arriver, elle fournira des estimés de paramètre biaisés.
32.7 Processus de sélection de modèle
Donc, une fois que l’on sait tout cela, le processus typique de construction et sélection d’un modèle mixte se déroule habituellement comme ceci :
Construire le modèle complet, probablement surajusté, incluant toutes les variables et les effets aléatoires d’intérêt
Si désiré, épurer les termes aléatoires du modèle, en se basant sur l’ajustement REML.
Épurer les termes fixes du modèle en se basant sur l’ajustement ML.
Présenter le modèle final, ajusté avec la technique REML.
J’ai ajouté la mention “si désiré” à l’étape 2, car à mon avis et de l’avis de plusieurs de mes collègues, cette étape est rarement pertinente. Si vos données ne sont pas indépendantes de par la structure de votre expérience (i.e. réplicats sur un même site, sur un même individu, etc.), il est justifié et pertinent de laisser l’effet aléatoire dans votre modèle, que ce dernier soit considéré important ou non en termes de variance expliquée.
Par souci d’économie d’espace, toutes nos comparaisons de modèles seront effectuées avec l’AIC, mais il existe aussi des façons de comparer les modèles mixtes qui fournissent des valeurs de p, par exemple les tests de ratios de vraisemblance (likelihood ratio test).
32.8 Validation du modèle
Un modèle mixte doit être validé selon les mêmes principes qu’un modèle à effet fixe (i.e. sans effets aléatoires). C’est-à-dire que l’on doit s’assurer que (1) la distribution des erreurs suit une loi normale et (2) que les résidus sont homogènes à travers le gradient de prédictions.
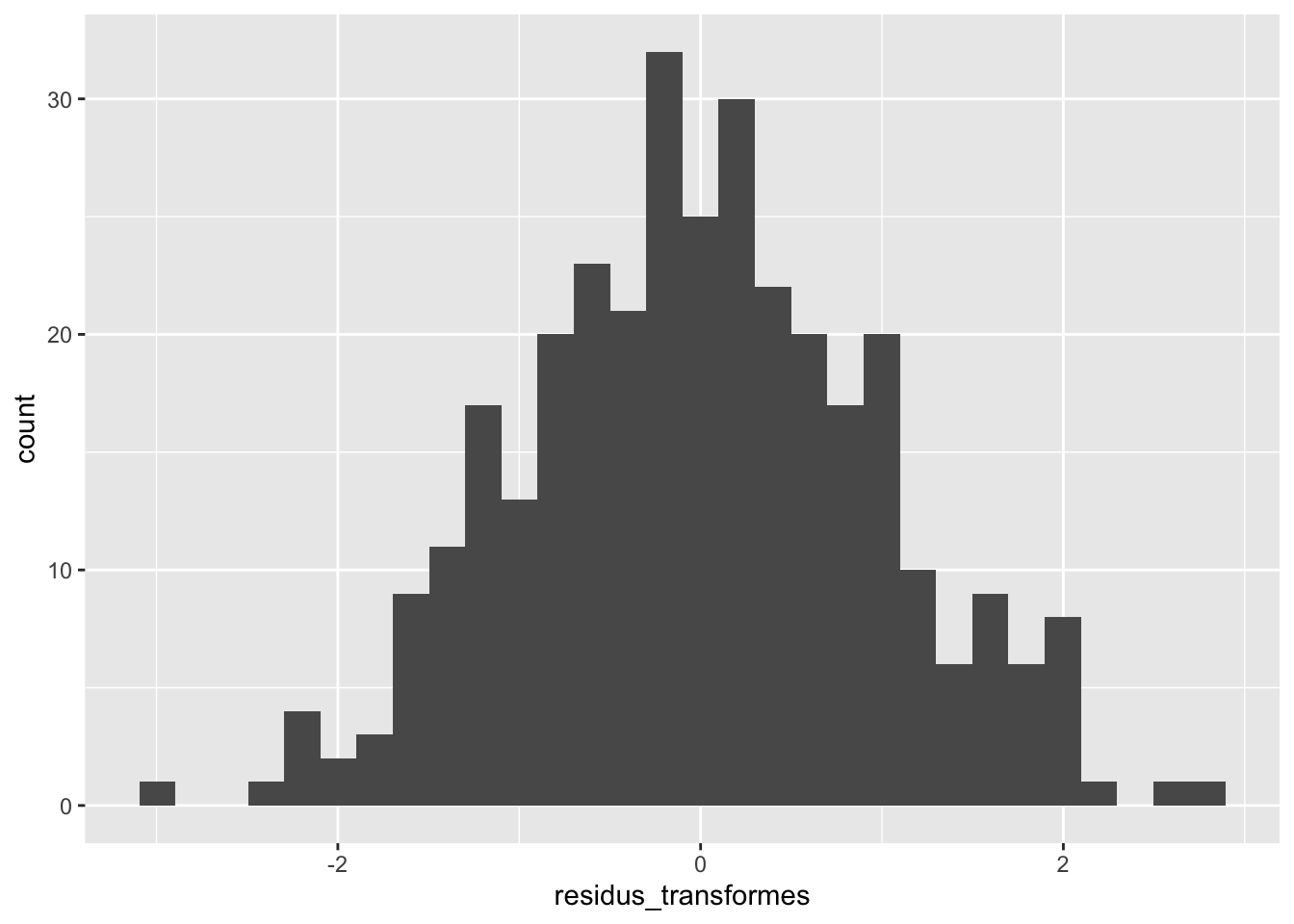
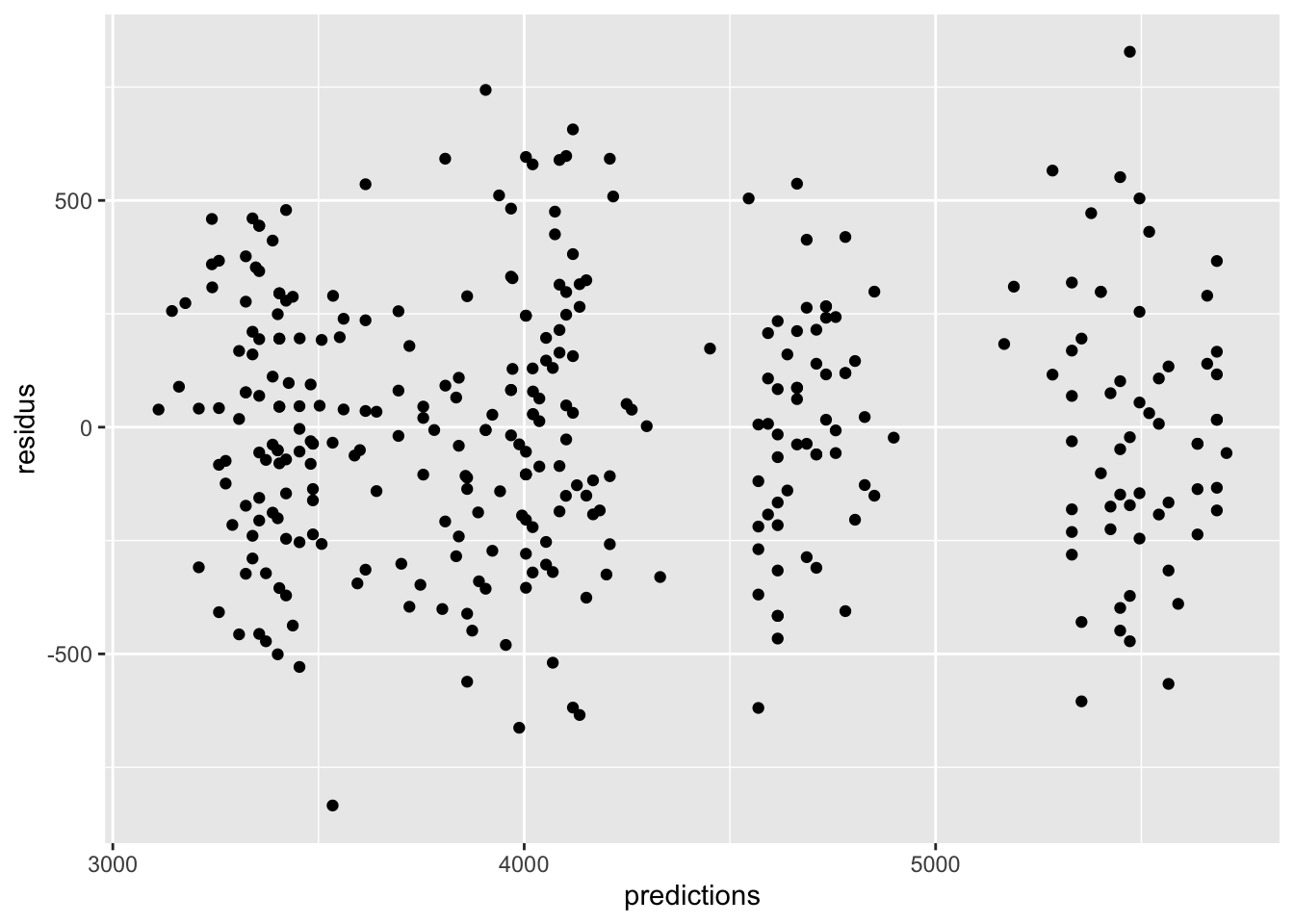
Comme notre modèle mixte contient, par définition, des observations corrélées entre-elles, les résidus bruts sont difficilement utilisables pour vérifier la normalité des erreurs. C’est pourquoi la plupart des auteurs recommandent d’utiliser une transformation, basée sur une décomposition de la matrice de variance-covariance. Le détail de cette transformation n’est absolument pas important ici. Ce qu’il faut retenir, c’est qu’après cette transformation, les résidus devraient maintenant suivre une distribution normale (si notre modèle est adéquat).
Une fois que l’on sait tout cela, on doit donc s’assurer que :
Les résidus transformés forment effectivement une distribution normale
Les résidus non-transformés ne présentent pas de patrons à travers le gradient de prédictions.
Une fois que vous savez tout cela, sachez par contre que récemment, des chercheurs ont montré par simulation que l’on peut torturer de beaucoup un modèle linéaire mixte, et qu’il continuera de donner des résultats fiables malgré les problèmes de non-normalité, hétéroscédasticité, etc (Schielzeth et al. 2020).
32.9 Labo : Le poids des manchots, avec effets aléatoires
Depuis le début de nos travaux avec le tableau de données des manchots de Palmer, nous avons travaillé comme si les individus étaient entièrement indépendants les uns des autres. Cependant, il est clair dans les méthodes de cueillette de données que ce n’est pas exactement le cas. Les données ont été recueillies sur 3 îles. On pourrait donc s’attendre à ce que les individus provenant d’une même île se ressemblent plus entre eux, puisqu’ils vivent dans les mêmes conditions.
Les différences inter-îles sont l’exemple parfait d’une variable pouvant être traitée en effet aléatoire. Dans le cas de nos projets, les valeurs associées à chaque île en particulier ne nous intéressent pas vraiment. Si on refaisait l’expérience, elle pourrait tout à fait être faite sur une autre série d’îles. On veut seulement tenir compte correctement de la non-indépendance des données dans nos analyses.
Remarquez, encore une fois, que ce choix dépend du point du vue de l’analyste. Si nous étions un gestionnaire de la faune qui s’occupe de ces 3 espèces, les particularités de chacune des îles pourraient tout à fait nous intéresser. Il faudrait alors mettre l’identité de l’île en effet fixe dans nos modèles.
Nous allons donc ré-analyser notre modèle prédisant le poids des manchots en fonction de l’espèce, du sexe, de la longueur des ailes et de l’interaction entre le sexe et l’espèce, mais en tenant compte cette fois de la non-indépendance de nos observations.
Tout d’abord, nous allons préparer nos données et charger les librairies nécessaires. Nous utiliserons pour nos exemples la librairie de modèles mixtes nlme, puisqu’elle possède la syntaxe la plus facile à comprendre, mais sachez qu’il en existe de nombreuses autres. Entre autres, la librairie lme4 est un autre classique et glmmTMB gagne de plus en plus en popularité.
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(nlme)
Attaching package: 'nlme'
The following object is masked from 'package:dplyr':
collapse
Donc, selon le protocole établi plus haut, notre première étape consistera à préparer un modèle complet, surajusté, contenant tous les effets fixes possible, afin de tester notre structure aléatoire. Comme expliqué plus haut, cette étape de sélection statistique de la présence ou non d’effets aléatoires est rarement justifiée. Néanmoins, elle nous permettra ici de voir comment inscrire dans R les différents types d’effets aléatoires.
Afin d’avoir un point de comparaison, nous allons d’abord nous créer un modèle sans effet aléatoire. Par contre, pour que nos modèles soient comparables avec la méthode REML, nous utiliserons la fonction gls pour ajuster ce premier modèle plutôt que la fonction lm :
modele_simple <-gls( body_mass_g ~ flipper_length_mm + sex + species + sex:species + species:flipper_length_mm, data = pour_modele_mixte, na.action ="na.fail",method ="REML")
Pour votre information, la fonction gls permet de spécifier des structures de variance, permettant de corriger les problèmes comme les effets d’entonnoirs ou de variances inégales dans nos résidus. Cependant, si on ne spécifie pas de structure de variance, comme ici, le modèle ajuste une régression normale, mais par la méthode REML plutôt que par les moindres carrés.
Étape 2 : Déterminer la structure aléatoire optimale
Nous allons ensuite ajuster un modèle avec une ordonnée à l’origine aléatoire sur la variable d’île. Nous utiliserons pour cela la fonction lme de la librairie nlme :
ordonnee_aleatoire <-lme( body_mass_g ~ flipper_length_mm + sex + species + sex:species + species:flipper_length_mm, random =~1| island,data = pour_modele_mixte, na.action ="na.fail",method ="REML")
Remarquez que la syntaxe est identique à une régression multiple normale, mais on ajoute dans l’argument random une deuxième formule, contenant uniquement la partie de droite (à partir du ~), qui décrit la structure des effets aléatoires dans notre modèle.
Remarquez la syntaxe étrange avec le 1 | island. Le 1 dans les formules de R symbolise l’ordonnée à l’origine. Nous n’avons jamais eu à le spécifier parce que R l’ajoute toujours pour nous lorsque l’on entre une formule. Par exemple, pour notre régression, on aurait pu tout aussi bien écrire
body_mass_g ~ 1 + flipper_length_mm
Si on avait voulu omettre l’ordonnée à l’origine dans un modèle, il aurait fallu le spécifier explicitement, en mettant un 0 plutôt qu’un 1, par exemple :
body_mass_g ~ 0 + flipper_length_mm
Dans la syntaxe des effets aléatoire, il faut lire la barre verticale (|) comme étant “par”. Par exemple, on demande ici une ordonnée à l’origine par valeur de la variable island. Implicitement, lme comprend que ces ordonnées à l’origine seront distribuées selon une loi normale (i.e. elles deviendront notre effet aléatoire).
Enfin, on aurait aussi pu vouloir tester la pertinence d’ajuster une pente différente par île plutôt qu’uniquement une ordonnée à l’origine. Autrement dit : ajuster un modèle dans lequel on a aussi une pente aléatoire. Dans R, la syntaxe pour ajuster un tel modèle aurait été la suivante :
pente_aleatoire <-lme( body_mass_g ~ flipper_length_mm + sex + species + sex:species + species:flipper_length_mm, random =~1+ flipper_length_mm | island,data = pour_modele_mixte, na.action ="na.fail",method ="REML")
Error in lme.formula(body_mass_g ~ flipper_length_mm + sex + species + : nlminb problem, convergence error code = 1
message = singular convergence (7)
On ajuste une ordonnée à l’origine (1) et une pente pour la variable de longueur des ailes par niveau de la variable d’île. Autrement dit, non seulement on pense que le poids moyen varie entre les îles, mais que l’effet de la longueur des ailes serait aussi différent entre les îles.
Malheureusement, notre jeu de données et sa structure de variance ne nous permettent pas d’évaluer ce modèle correctement.
Évidemment, on aurait pu compliquer les choses encore plus en se demandant si l’île change l’effet du sexe, de l’espèce, etc. Mais on en a déjà bien assez ici pour comprendre le principe. L’idée générale étant que notre modèle doit refléter la structure hiérarchique de nos données.
Donc, une fois tous ces modèles ajustés, avec le méthode REML, on peut les comparer afin de déterminer la meilleure structure aléatoire. Pour ce faire, une façon simple est d’utiliser la fonction model.sel de la librairie MuMIn, qui nous calculera l’AIC de chacun des modèles :
model.sel(modele_simple, ordonnee_aleatoire)
Model selection table
(Int) flp_lng_mm sex spc
modele_simple 278.8 23.5 + +
ordonnee_aleatoire 278.8 23.5 + +
flp_lng_mm:spc sex:spc class random
modele_simple + + gls
ordonnee_aleatoire + + lme i
df logLik AICc delta weight
modele_simple 10 -2317.56 4655.8 0.00 0.745
ordonnee_aleatoire 11 -2317.56 4657.9 2.14 0.255
Models ranked by AICc(x)
Random terms:
i: 1 | island
Ici, le meilleur modèle basé sur l’AIC est celui ne contenant pas une ordonnée à l’origine aléatoire pour chaque île. Ce modèle est 3x plus probable que celui avec une ordonnée aléatoire ( 0.745 / 0.255 = 2.92).
Donc, si on avait voulu, il aurait été légitime de continuer notre modélisation sans l’effet aléatoire. Cependant, je privilégie toujours de le laisser en place, puisque ce terme rend explicite la structure hiérarchique de nos données.
Étape 3 : Sélection de modèle pour la partie fixe
Une fois la structure aléatoire choisie, il faudrait maintenant effectuer la sélection de modèle sur la partie fixe du modèle. La procédure est exactememnt la même que celle suggéré au Chapitre 29, mais il faut penser d’ajuster les modèles avec la méthode “ML” si on ne veut pas biaiser nos résultats.
MuMIn vous avertira d’ailleurs si vous tentez de comparez les termes fixes d’un modèle avec la méthode REML.
avec_ML <-lme( body_mass_g ~ flipper_length_mm + sex + species + sex:species + species:flipper_length_mm, random =~1| island,data = pour_modele_mixte, na.action ="na.fail",method ="ML")dredge(avec_ML)
Nos résultats n’ont pas vraiment bougé en ajoutant l’effet aléatoire, ce qui était prévisible étant donné sa faible importance.
32.10 Labo : Validation du modèle avec effets aléatoires et interprétation
Comme discuté précédemment, nous devons maintenant extraire deux résidus différents de notre modèle, soit les résidus bruts, et les résidus transformés :
pour_modele_mixte <- pour_modele_mixte |>mutate(residus =residuals(ordonnee_aleatoire),residus_transformes =residuals(ordonnee_aleatoire, type ="normalized"),predictions =predict(ordonnee_aleatoire) )
Il faut ensuite valider la normalité des erreurs avec les résidus transformés :
Donc, dans l’ordre, le modèle nous présente d’abord certaines statistiques d’ajustement (AIC, BIC , etc.).
Le deuxième bloc d’information nous présente la partie aléatoire de notre modèle. Il nous rappelle la structure de notre effet aléatoire, puis nous informe de l’écart-type associé à chacune des composantes de variance de notre modèle : 0,022 pour l’effet de l’île (Intercept) et 287,11 pour les résidus. Avec ces deux chiffres, on peut calculer manuellement l’ICC soit : 0,0222 / (0,0222 + 287,112) = 5,87x10-9. Autrement dit, les manchots d’une même île sont aussi différents qu’entre les îles. Cette valeur d’ICC minuscule confirme aussi le diagnostic de l’AIC, qui nous suggérait que l’île n’avait pas vraiment d’impact.
Le troisième bloc d’information nous fournit les coefficients de la partie fixe du modèle, qui s’interprète exactement comme dans la régression multiple.
Le reste de l’information fournie ne sera pas utilisée dans ce cours.
32.11 Conclusion
Les modèles linéaires mixtes sont un sujet relativement complexe, mais qui vient résoudre un problème plutôt commun en écologie : le manque d’indépendance entre les observations. Il y a énormément de cas particuliers qui pourraient survenir lorsque vous analyserez vos propres données avec des modèles mixtes, que nous n’avons pas traité ici. Je vous laisse donc en référence la Foire aux Questions (FAQ) préparée par Ben Bolker, l’auteur des librairies de modèles mixtes lme4 et glmmTMB : https://bbolker.github.io/mixedmodels-misc/glmmFAQ.html. Elle vous sera probablement d’une grande utilité dans vos aventures statistiques!
Schielzeth, Holger, Niels J. Dingemanse, Shinichi Nakagawa, David F. Westneat, Hassen Allegue, Céline Teplitsky, Denis Réale, Ned A. Dochtermann, László Zsolt Garamszegi, et Yimen G. Araya‐Ajoy. 2020. « Robustness of linear mixed‐effects models to violations of distributional assumptions ». Édité par Chris Sutherland. Methods in Ecology and Evolution 11 (9): 1141‑52. https://doi.org/10.1111/2041-210X.13434.