La totalité des modèles rencontrés jusqu’ici dans le cours assument que la relation entre les variables étudiées est linéaire (ou du moins, qu’elle peut être linéarisée à l’aide de transformations). Évidemment, cette assomption ne tient pas toujours la route dans la vraie vie.
Dans ce chapitre, nous verrons une technique, les arbres de régression, qui assument plutôt que les réponses fonctionnent sous forme de seuils, de coupures, où les valeurs comportent des plateaux et des changements abrupts.
34.2 Exemple de sortie
Comme les arbres de régression sont conceptuellement très différents de ce que nous avons vu jusqu’à présent, commençons par voir à quoi peuvent ressembler les sorties de cette technique. Nous en verrons ensuite le fonctionnement et les particularités.
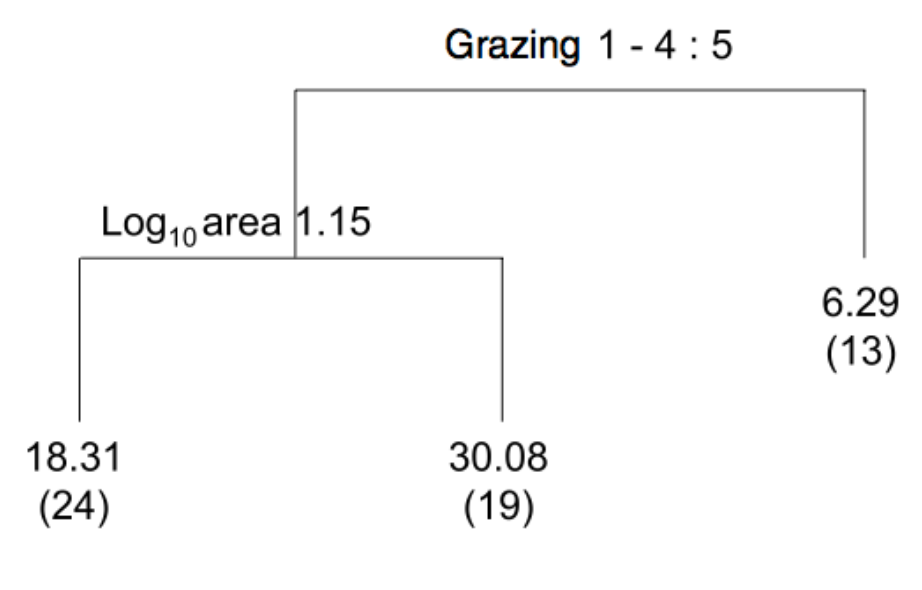
Cette figure est le résultat d’une modélisation de la richesse en espèces d’oiseaux à partir de variables décrivant le paysage (area, la surface de la parcelle et grazing le niveau de broutement, et d’autres, qui n’ont pas été retenues) à l’aide d’un arbre de régression.
La figure se lit de haut en bas, avec à chaque intersection un choix à faire, qui nous amène à l’une ou l’autre de sorties du modèle.
Cette figure s’interprète comme suit :
Si le niveau de broutement est 5, le modèle prédit 6,29 espèces
Si le broutement est entre 1 et 4 et que la surface est plus petite que que 1,15 (à l’échelle log), on prédit 18,31 espèces
Si le broutement est entre 1 et 4 et que la surface est plus grande que 1,15 (à l’échelle log), on prédit 30,08 espèces.
Les chiffres entre parenthèses indiquent le nombre d’observations qui arrivent à ce point dans notre tableau de données, lorsque l’on parcourt l’arbre avec chacune d’entre elles.
On nomme noeuds (node) les intersections dans l’arbre, qui contiennent les conditions et feuilles (leaf) les points où on prédit une valeur. L’arbre ci-dessus contient donc 2 nœuds et 3 feuilles.
Remarquez que l’arbre est à l’envers, avec les feuilles vers le bas. Ce n’est pas la chose la plus logique du monde, mais c’est comme ça que les inventeurs de la méthode ont proposé de faire les graphiques de sortie.
34.3 Avantages et inconvénients
Le principal avantage des arbres de régression est que les sorties sont faciles à interpréter, particulièrement lorsque vient le moment de discuter des résultats avec des praticiens ou des décideurs. Les points de coupure s’interprètent beaucoup plus facilement que l’ordonnée à l’origine et les pentes partielles d’une régression multiple.
L’autre avantage de cette méthode est que, outre l’assomption de normalité de la variable expliquée, elle n’a pas d’assomption quant à linéarité des relations avec les autres variables.
Conceptuellement, le principe des points de coupure est particulièrement approprié lorsque l’on modélise des processus décisionnels, p. ex. si on tente de déterminer si une espèce va occuper ou non une parcelle.
Cette méthode comporte par contre aussi certains inconvénients. Puisque les prédictions de l’arbre sont groupées, ces prédictions peuvent être parfois grossières lorsque l’on tente d’ajuster l’arbre de régression à des réponses linéaires (dans ces cas, la régression linéaire aurait été plus appropriée…). L’autre désavantage majeur de cette technique est que la structure de l’arbre peut parfois être instable, où un petit changement dans les données modifiera la structure de l’arbre résultant1.
34.4 Comment se construit l’arbre
Lorsque les anglophones décrivent le mécanisme de construction d’un arbre de régression, ils utilisent les termes top down (i.e. du haut vers le bas) et greedy (i.e. avide ou gourmand).
Top down, d’abord, parce que la construction de l’arbre se fait du haut vers le bas. On part du point où toutes les données sont dans un même groupe, on les sépare, on sépare ensuite les séparations, etc. Mais on ne remonte jamais pendant la construction. Un point de coupure n’est jamais modifié après qu’il ait été établi.
On dit aussi que l’algorithme est greedy, parce qu’au moment de définir un point de coupure, il ne se soucie que de cette coupure en particulier, et pas comment elle va influencer la qualité totale du reste de l’arbre. Il ne regarde pas les conséquences plus loin dans le processus.
L’algorithme doit fonctionner de cette façon parce que, même en 2026, tester tous les points de coupure et toutes les configurations d’arbres possibles avec nos données serait juste impossiblement long.
À chaque fois que l’algorithme essaie de trouver une séparation, il choisira celle qui minimise la somme des carrés des résidus.
L’algorithme va couper et couper les données, jusqu’à atteindre une condition pré-déterminée. Cette condition peut être différentes choses, mais on se base souvent sur un nombre minimal d’observation par feuille (p. ex. 5).
34.5 Labo : Les arbres de régression
Comme initiation aux arbres de régression dans le logiciel R, nous allons continuer de travailler avec les manchots de Palmer pour tenter de prédire leur poids. Nous utiliserons les mêmes variables qu’aux chapitres précédent, soit la longueur des ailes, le sexe et l’espèce.
Remarquez qu’ici, nous n’aurons pas besoin de spécifier de termes d’interaction. Ces derniers sont plutôt implicites dans l’enchaînement des noeuds. Une interaction entre le sexe et l’espèce sera représentée par un premier noeud avec le sexe, puis, dans chacune des branches (une pour les mâles et une pour les femelles), on en aurait une seconde pour le choix de l’espèce, etc.
Il est également inutile de se soucier des niveaux de références pour nos facteurs. Toutes les catégories sont directement présentes dans le modèle.
Pour ajuster notre arbre de régression, nous utiliserons la librairie nommée tree. Vous devrez donc l’installer avant de lancer le code. Sachez qu’il existe d’autres implémentations de l’algorithme d’arbre de régression dans R, entre autres dans la librairie cart. Cette dernière est souvent considérée comme plus puissance, mais treee est plus facile d’approche pédagogiquement.
Donc, activons d’abord nos librairies et préparons notre jeu de données :
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.2.1
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
La seule chose à vérifier avant de lancer notre modèle est que la distribution de notre variable expliquée (body_mass_g) suit une distribution normale. Pour les autres, l’algorithme trouvera sans problèmes les points de coupure sans besoin de transformations. Comme il s’agit du Xe chapitre dans lequel nous utilisons les manchots de Palmer, on sait que le poids des manchots est distribué normalement!
Enfin, nous avons discuté dans le Chapitre 30 que les variables catégoriques peuvent exister sous 2 formats (character et factor) et que la majorité des fonctions de R ne font pas la différence entre les deux. Hors, la fonction tree, elle, s’en soucie. Donc, si jamais vos variables catégoriques n’étaient pas encore en facteur avant d’arriver ici, il faudrait le faire explicitement. Mais dans notre cas, c’est déjà fait pour nous dans les données originales.
La fonction pour ajuster un arbre de régression se nomme tree, et s’utilise à l’aide d’une formule et d’un argument data, exactement comme la fonction lm :
m <-tree( body_mass_g ~ flipper_length_mm + sex + species, data = pour_arbres)
Par la suite, on peut inspecter notre objet de résultats :
summary(m)
Regression tree:
tree(formula = body_mass_g ~ flipper_length_mm + sex + species,
data = pour_arbres)
Variables actually used in tree construction:
[1] "species" "sex"
Number of terminal nodes: 4
Residual mean deviance: 97680 = 32140000 / 329
Distribution of residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-760.30 -219.20 15.16 0.00 220.30 815.20
On voici ici, entre autres, que notre arbre contient 4 feuilles (terminal nodes). Il s’agit plus ou moins de la seule information intéressante pour nous dans cette sortie.
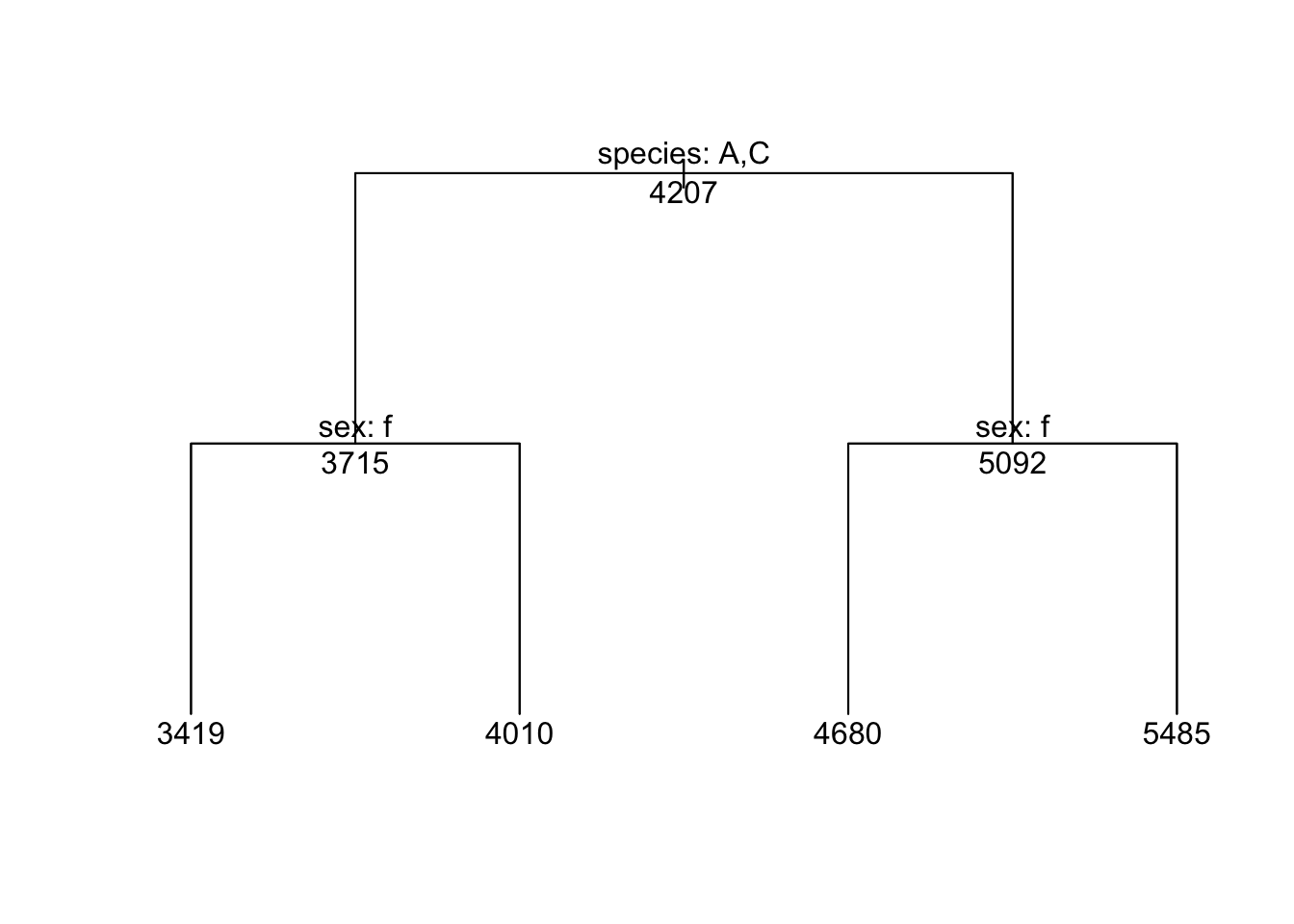
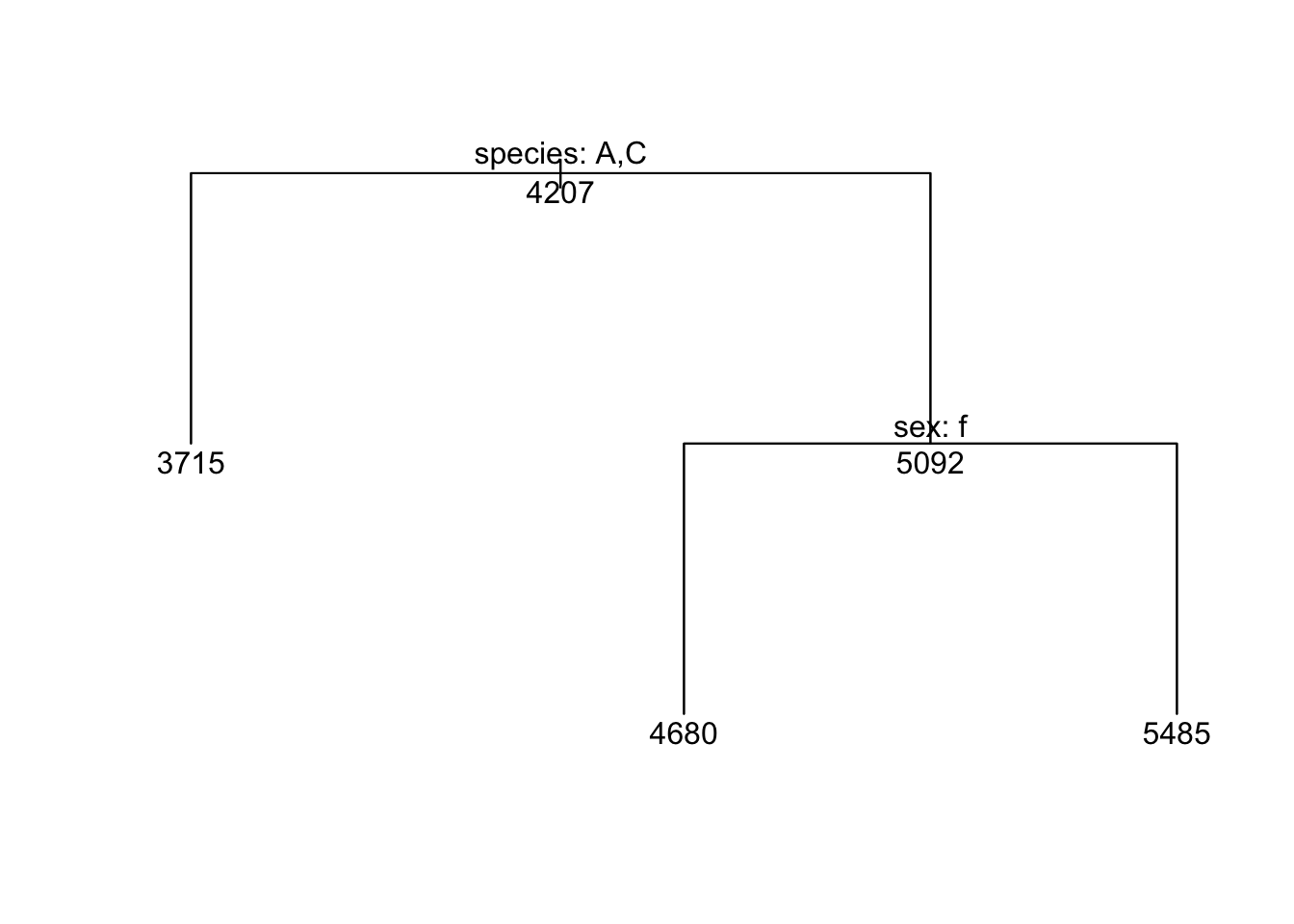
Ensuite, on peut faire afficher la structure de notre arbre, à l’aide d’une combinaison de la fonction plot et text :
plot(m, type ="uniform")text(m,pretty =1, all =TRUE)
Dans cette sortie, on peut donc constater que le premier point de coupure est basé sur l’espèce. À gauche Adélie (A) et Chinstrap (C), pour une moyenne de 3715 g et à droite le reste (i.e. le manchot Gentoo) pour une moyenne de 5092 g. Ensuite, pour la combinaison Adélie et Chinstrap, le deuxième point de coupure est basé sur le sexe, avec les femelles à gauche, pour 3419 g et les mâles à droite pour 4010 g. Le même phénomène se reproduit du côté des manchots Gentoo, avec les femelles à gauche (4680 g) et les mâles à droite (5485 g). Donc, contrairement au modèle linéaire, l’arbre de régression n’a pas utilisé la longueur des ailes pour prédire le poids des manchots.
Remarquez que cette fonction n’utilise pas ggplot. À l’heure actuelle, il n’existe malheureusement pas de façon simple de reproduire ce graphique avec ggplot. Vous devrez donc vous en tenir aux graphiques de base de R, ou sortir vos talents de Photoshop ;-)
Enfin, si on veut avoir une idée de la performance de notre modèle, on peut en extraire les prédictions, et calculer soit une valeur de pseudo-r2, ou soit une mesure de l’erreur moyenne des prédictions (mean absolute error).
preds <-predict(m)
Pour calculer le pseudo-r2, on calcule la corrélation entre les prédictions du modèle et les valeurs observées, et un met ce chiffre au carré. On parle de pseudo-r2 plutôt que de r2 pur parce qu’on ne parle pas ici de variance expliquée ou de variance résiduelle comme dans la définition originale, mais le chiffre s’interprète de la même manière.
cor(preds,pour_arbres$body_mass_g)^2
[1] 0.850702
Donc, c’est légèrement moins bon que notre modèle linéaire avec des variables catégoriques (Chapitre 30) qui atteignait 87%, mais aussi plus facile à interpréter pour un non-initié.
Pour calculer l’erreur de prédiction moyenne du modèle, nous allons calculer la différence, pour chaque observation, entre la valeur prédite et la valeur observée, prendre la valeur absolue de ces différences, et en faire la moyenne. Ça sonne compliqué, mais ça se calcule en une seule ligne de R :
mean(abs(preds-pour_arbres$body_mass_g))
[1] 249.5585
Donc, notre arbre de régression explique 85% de la variance du poids des manchots, et ses prédictions se trompent en moyenne de 249 g.
Note
Notez que l’erreur de prédiction moyenne peut aussi être calculée pour des modèles de régression. Il est simplement plus rare que les régression soit entraînées pour effectivement calculer des prédictions comme tel.
34.6 L’élagage
Il est reconnu dans la littérature qu’un arbre de régression construit à l’aide de la procédure décrite précédemment aura tendance à être trop complexe. Autrement dit, sur-ajusté aux données. Il ne généralisera pas très bien sur de nouvelles données qu’il ne connaît pas.
Il faut donc par la suite simplifier l’arbre, afin de régler ce problème. Dans le jargon des arbres de régression, on nomme cette opération élagage (pruning).
34.7 La validation croisée
Avant d’aller plus loin dans le processus d’élagage, il importe de définir un concept important, qui est la validation croisée. Depuis le début de nos analyses, lorsque nous voulions valider la performance d’un modèle, nous observions ses résidus.
Par contre, à chaque fois, nous utilisions les mêmes données pour évaluer la performance du modèle que celles utilisées pour l’ajuster. Cela nous laisse toujours dans le doute quant à savoir si le modèle fonctionnera aussi bien sur un autre jeu de données. On ne sait pas à quel point il généralise bien.
La validation croisée permet de régler ce problème en séparant nos données avant de commencer l’ajustement. Le principe est de prendre une partie de nos données pour ajuster le modèle, et l’autre pour en valider la performance réelle sur des données nouvelles.
Note
Notez que cette technique n’est pas restreinte aux arbres de régression. Elle pourrait s’appliquer à tout type de modèle prédictif pour lesquels on veut valider leur performance réelle, c’est-à-dire leur capacité à prédire de nouvelles données. Il existe entre autres une fonction nommée cv.lm dans la librairie DAAG qui permet d’appliquer la validation croisée sur une régression linéaire. Nous avions simplement évité le sujet jusqu’ici car la régression linéaire a beaucoup moins tendance à produire des modèles sur-ajustés que les arbres de régression.
Astuce
Nous avons escamoté ce détail dans les chapitres précédents, mais sachez que l’AIC a été conçu pour remplacer le processus de validation croisée. De par sa structure mathématique, l’AIC va tendre à classer les modèles dans le même ordre que la validation croisée l’aurait fait, sans devoir faire la validation croisée comme tel. Remarquez que cette propriété est asymptotique, c’est-à-dire que plus le jeu de données est grand, plus elle sera vraie.
34.8 La validation croisée à k groupes
Une des façons classique de faire la validation croisée est d’utiliser la validation par k groupes (K-fold cross-validation). Cette technique consiste à :
Séparer le jeu de données en k groupes aléatoires.
Ajuster un modèle avec les données de k-1 groupes
Tester avec les données restantes
Recommencer ce processus par chacune des k fractions.
Par exemple, si j’ai 60 observations dans mon tableau de données et que je fais ma validation croisée avec k=3, j’obtiens trois groupes au hasard, contenant les données que l’on numérote respectivement 1-20, 21-40 et 41-60. Je devrais donc ajuster et tester mon modèle 3 fois :
Ajuster avec 1-40 et tester avec 41-60
Ajuster avec 21-60 et tester avec 1-20
Ajuster avec 1-20+41-60 et tester avec 21-40.
On calcule ensuite l’erreur moyenne des k modèles pour obtenir une idée de la performance globale.
En général, on utilise un k de 4 ou 5, afin d’obtenir un bon compromis entre la quantité de données dans chacun des modèles, mais aussi que nos différents modèles ne soient pas trop corrélés ensemble.
Il existe d’autres façons de faire, par exemple le Leave One Out cross-validation (LOOCV) où k est égal au nombre d’observations dans la base de données. Cette stratégie est particulièrement utile lorsque notre jeu de données est très petit, ce qui cause beaucoup de variabilité entre les k modèles ajustés. Le désavantage du LOOCV est que les k modèles testés sont extrêmement corrélés entre eux, puisqu’ils ne diffèrent que par une seule observation.
34.9 Stratégie d’élagage
Même en utilisant le principe de la validation croisée, on ne règle pas magiquement notre problème de modèle sur-ajusté car nous n’avons toujours pas la possibilité d’explorer tous les arbres possibles et imaginables. Je le répète, ça serait beaucoup trop long, même pour un ordinateur moderne.
Pour contourner ce problème, il faut se munir d’une mesure d’ajustement complémentaire, qui pénalise pour les modèles trop complexes, un peu comme le R2-ajusté peut le faire pour la régression linéaire multiple.
Plusieurs algorithmes d’arbres de régression utilisent donc une mesure d’ajustement où on ajoute à la somme des carrés des résidus le nombre de feuilles multiplié par un paramètre nommé α (alpha), qui définit un coût associé à la complexité de l’arbre.
La stratégie à adopter par la suite est donc de faire augmenter progressivement la valeur de α à partir de zéro et pour chaque valeur de α que l’on veut tester, on cherche (plus précisément, l’ordinateur cherchera pour nous!) l’arbre qui minimise cette valeur.
L’avantage de cette méthode est que chacun des arbres trouvés pour des valeurs de α différentes sera un sous-ensemble simplifié de notre arbre original. Celui où α=0 correspondant à notre arbre complet, avant l’élagage, puisqu’il n’en coûte rien d’avoir beaucoup de feuilles.
On calcule alors l’erreur de prédiction de chacun de ces arbres à l’aide de la validation croisée et on conserve l’arbre le plus performant sur de nouvelles données.
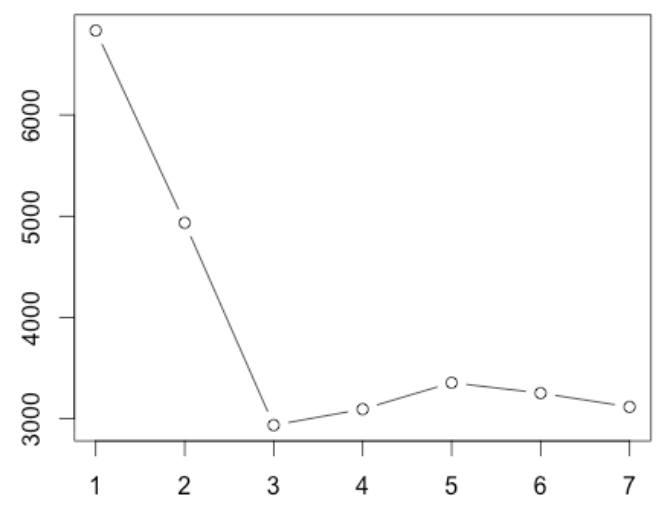
On pourrait obtenir un graphique semblable à ceci, où on met en relation l’erreur moyenne de la validation croisée avec la taille de l’arbre :
Dans ce cas précis, nous conserverons pour interprétation l’arbre contenant 3 feuilles, puisqu’il possède l’erreur la plus faible.
34.10 Labo : L’élagage d’un arbre de régression
Donc, voyons maintenant comment on peut essayer d’élaguer l’arbre ajusté précédemment, pour s’assurer qu’il n’est pas sur-ajusté à nos données et qu’il généralise bien sur de nouvelles données.
La fonction pour effectuer l’élagage de notre arbre en se basant sur la validation croisée et un paramètre de coût de complexité se nomme cv.tree (Cross-Validation TREE). Comme nous avons eu jeu de données sufisamment grand, nous pourrons utiliser la validation croisée avec k=5 groupes.
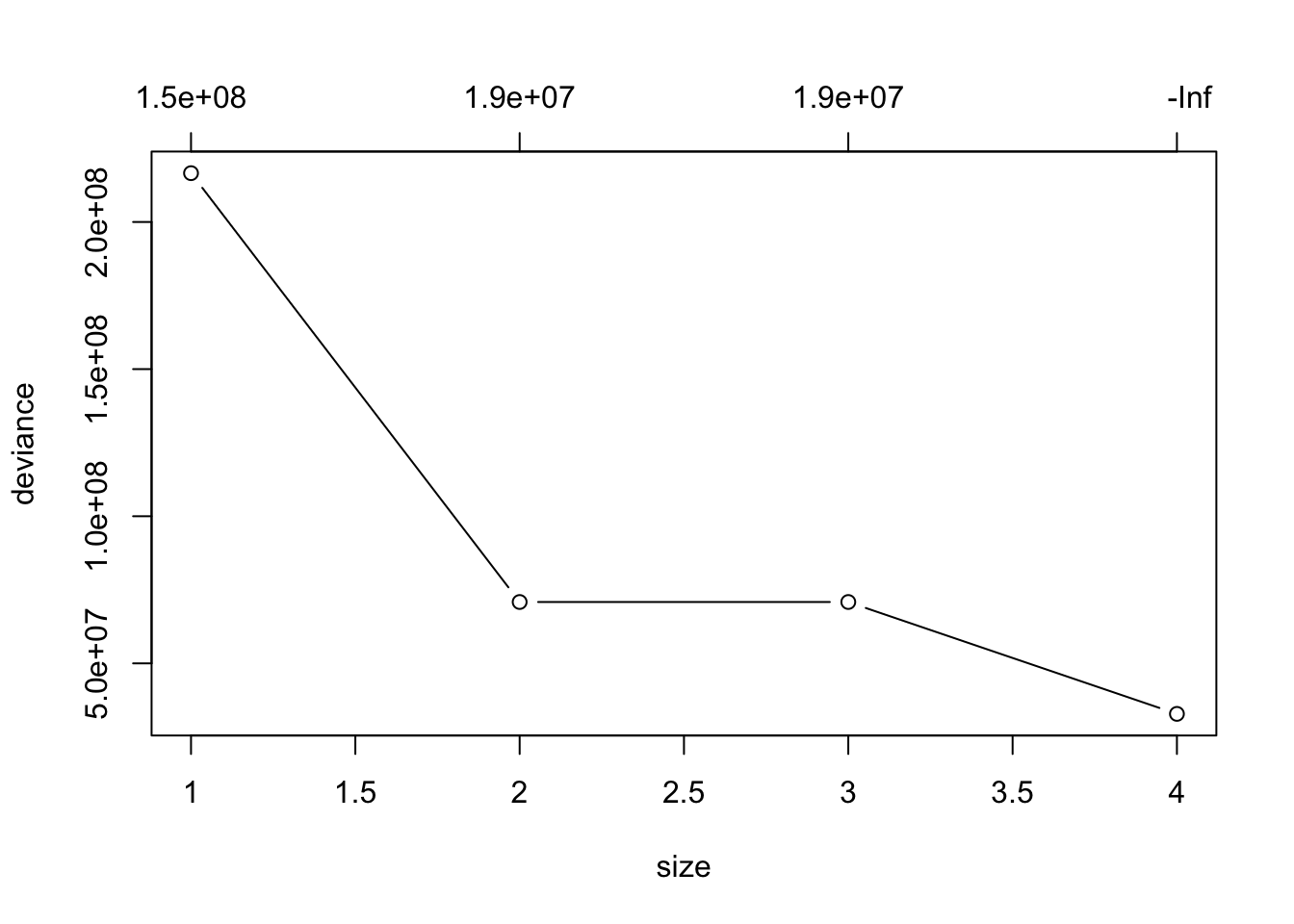
validation_croisee <-cv.tree(m,K =5)plot(validation_croisee, type ="b")
Il se peut que votre graphique soit légèrement différent du mien, puisque les groupes sont générés de façon aléatoire, mais la conclusion qualitative devrait rester la même.
Dans ce graphique, on cherche la taille d’arbre (size) qui minimise notre mesure d’erreur (deviance). Dans notre cas, l’arbre idéal contiendrait encore 4 feuilles.
Note
Pour des raisons techniques, la librairie tree calcule l’erreur en terme de déviance plutôt qu’en somme des carrés des erreurs. Mais nos interprétations restent les mêmes, pluisque la déviance est toujours proportionnelle à la somme des carrés.
Si jamais la hauteur des points est difficile à interpréter parce qu’ils sont très près les uns des autres, on peut aussi aller voir directement les chiffres dans notre objet :
Donc, dans la vraie vie, on aurait pu arrêter ici. Notre arbre original n’a pas besoin d’être élagué.
Mais pour l’exercise, allons voir comment on aurait dû s’y prendre pour récupérer le meilleur arbres à 3 feuilles plutôt qu’à 4. Pour se faire, on doit utiliser la fonction prune.tree (égaluer.arbre).
arbre_a_3_feuilles <-prune.tree(m,best =3)plot(arbre_a_3_feuilles, type ="uniform")text(arbre_a_3_feuilles,pretty =1, all =TRUE)
Remarquez que dans cet arbre, on aurait pas séparé par sexe les individus de l’espèce Adélie ou Chinstrap.
On peut par la suite mesurer la performance de ce nouvel arbre, de la même façon dont nous avions mesuré la performance du premier :
En enlevant la dernière feuille, on aurait perdu presque 10% d’explication et presque doublé notre erreur de prédiction.
Note
Notez qu’à cette étape, presque à tout coup, votre arbre élagué performera moins bien que votre arbre original. Comme discuté plus haut, les arbres de régression ont tendance à être surajusté. Votre arbre élagué sera cependant assurément le meilleur pour faire des prédictions sur de nouvelles données.
34.11 Un monde qui s’ouvre devant vous.
Il existe plusieurs autres techniques pour essayer d’ajuster des modèles statistiques à des réponses non linéaires, par exemple avec les modèles de type GAM (Generalized Additive Models) qui permettent d’ajuster une courbe de lissage plutôt qu’une réponse linéaire.
J’ai choisi de vous enseigner les arbres de régression car ils ouvrent la porte sur un monde de possibilités. Les arbres de régression peuvent, entre autres, être utilisés pour travailler avec des variables expliquées catégoriques, par exemple pour prédire la mort ou la survie d’un individu. On parlera alors d’arbres de classification.
Ils sont aussi à la base d’une technique nommée Random Forests (littéralement des forêts aléatoires) qui sont parmi les techniques d’apprentissage automatique (machine learning) les plus puissantes utilisées à ce jour (à l’exception bien évidemment de l’apprentissage profond des réseaux neuronaux).
34.12 Exercice : Les arbres de régression
Pour cet exercice, je vais vous demande de réanalyser le jeu de données de Loyn vu au Chapitre 28, où l’on tentait de prédire l’abondance d’oiseaux dans des parcelles (ABUND), à partir du paysage environnant (AREA, YR.ISOL, DIST, ALT). Mais cette fois-ci, vous utiliserez les arbres de régressions plutôt que la régression multiple.
Je vous demande donc de :
Charger le jeu de données et les librairies nécessaires
Vérifier ce qu’il y a à vérifier avant de lancer un arbre de régression
Ajuster un modèle d’arbre de régression
Évaluer la performance de cet arbre (probablement surajusté)
Comparer la performance de cet arbre à celle de la régression multiple du Chapitre 28.
Élaguer cet arbre en vous basant sur la validation croisée
Préparer un arbre final, bien élagué et visualisez-le
Évaluer la performance de cet arbre élagué.
Selon cet arbre, quel est le pire scénario possible à avoir comme paysage si on veut avoir de fortes abondances d’oiseaux (en vos mots). Et au contraire, quelle est la meilleure façon d’obtenir de fortes abondances?
34.4 Comment se construit l’arbre
Lorsque les anglophones décrivent le mécanisme de construction d’un arbre de régression, ils utilisent les termes top down (i.e. du haut vers le bas) et greedy (i.e. avide ou gourmand).
Top down, d’abord, parce que la construction de l’arbre se fait du haut vers le bas. On part du point où toutes les données sont dans un même groupe, on les sépare, on sépare ensuite les séparations, etc. Mais on ne remonte jamais pendant la construction. Un point de coupure n’est jamais modifié après qu’il ait été établi.
On dit aussi que l’algorithme est greedy, parce qu’au moment de définir un point de coupure, il ne se soucie que de cette coupure en particulier, et pas comment elle va influencer la qualité totale du reste de l’arbre. Il ne regarde pas les conséquences plus loin dans le processus.
L’algorithme doit fonctionner de cette façon parce que, même en 2026, tester tous les points de coupure et toutes les configurations d’arbres possibles avec nos données serait juste impossiblement long.
À chaque fois que l’algorithme essaie de trouver une séparation, il choisira celle qui minimise la somme des carrés des résidus.
L’algorithme va couper et couper les données, jusqu’à atteindre une condition pré-déterminée. Cette condition peut être différentes choses, mais on se base souvent sur un nombre minimal d’observation par feuille (p. ex. 5).