Au Chapitre 28, nous avons vu comment ajuster un modèle de régression multiple. Nous avons aussi vu qu’au terme de l’analyse, nous obtenions un tableau des estimés de paramètres, qui nous indiquait la pente partielle pour chaque variable, ainsi qu’une valeur de p et une erreur-type associée, nous indiquant notre certitude quant à l’estimation de chacune de ces pentes.
Basé sur la valeur de p, certains paramètres ont un effet clair (longueur des ailes), d’autres un effet plus mitigé (longueur et épaisseur du bec).
Ce qu’il est par contre important de savoir est que la valeur de p est une technique parmi d’autres permettant d’évaluer quelles variables garder et quelles éliminer d’un modèle.
Ce processus, de passer d’un modèle complexe contenant toutes les variables pour lesquelles nous avions des hypothèses à un modèle simplifié ne retenant que celles que nous jugeons importantes après le processus de modélisation se nomme la sélection de modèle. Ce sujet fera l’objet d’un chapitre entier, puisqu’il existe de multiples philosophies et techniques différentes, avec chacune de bons et des mauvais côtés.
29.2 Comment juger de l’explication?
Comment savoir si un modèle statistique explique bien un phénomène naturel? Une façon classique de le déterminer est de se demander si toutes les variables importantes sont effectivement contenues dans le modèle. Et à l’inverse, si une variable n’est pas importante, est-elle effectivement laissée de côté?
29.3 Comment juger des prédictions?
Outre fournir de bonnes explications, il est possible que notre objectif de modélisation soit plutôt de fournir les meilleures prédictions possibles pour un phénomène.
Naturellement, on aurait tendance à penser que plus un modèle possède de petits résidus, plus il offre de bonnes prédictions, donc plus il est bon, non?
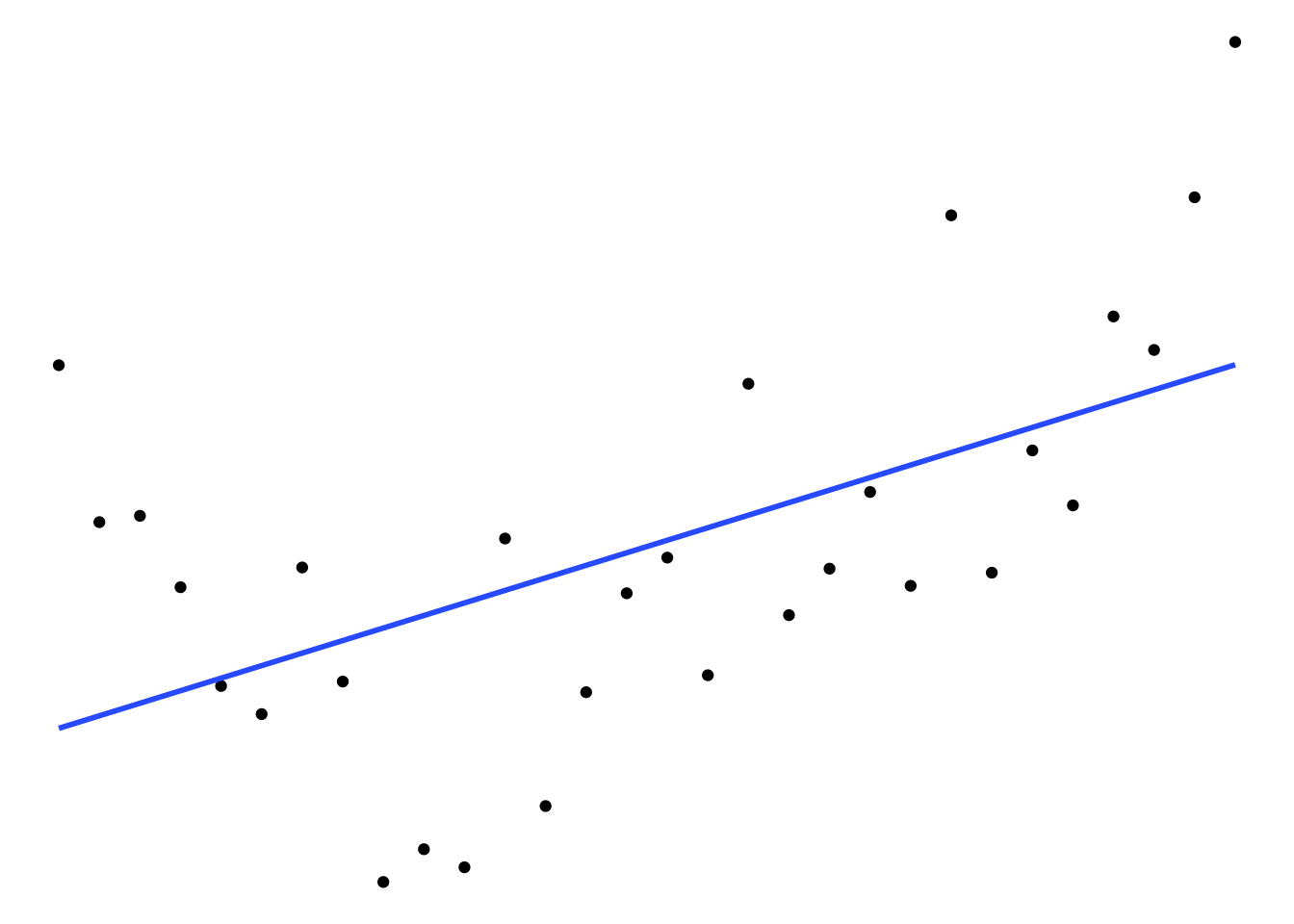
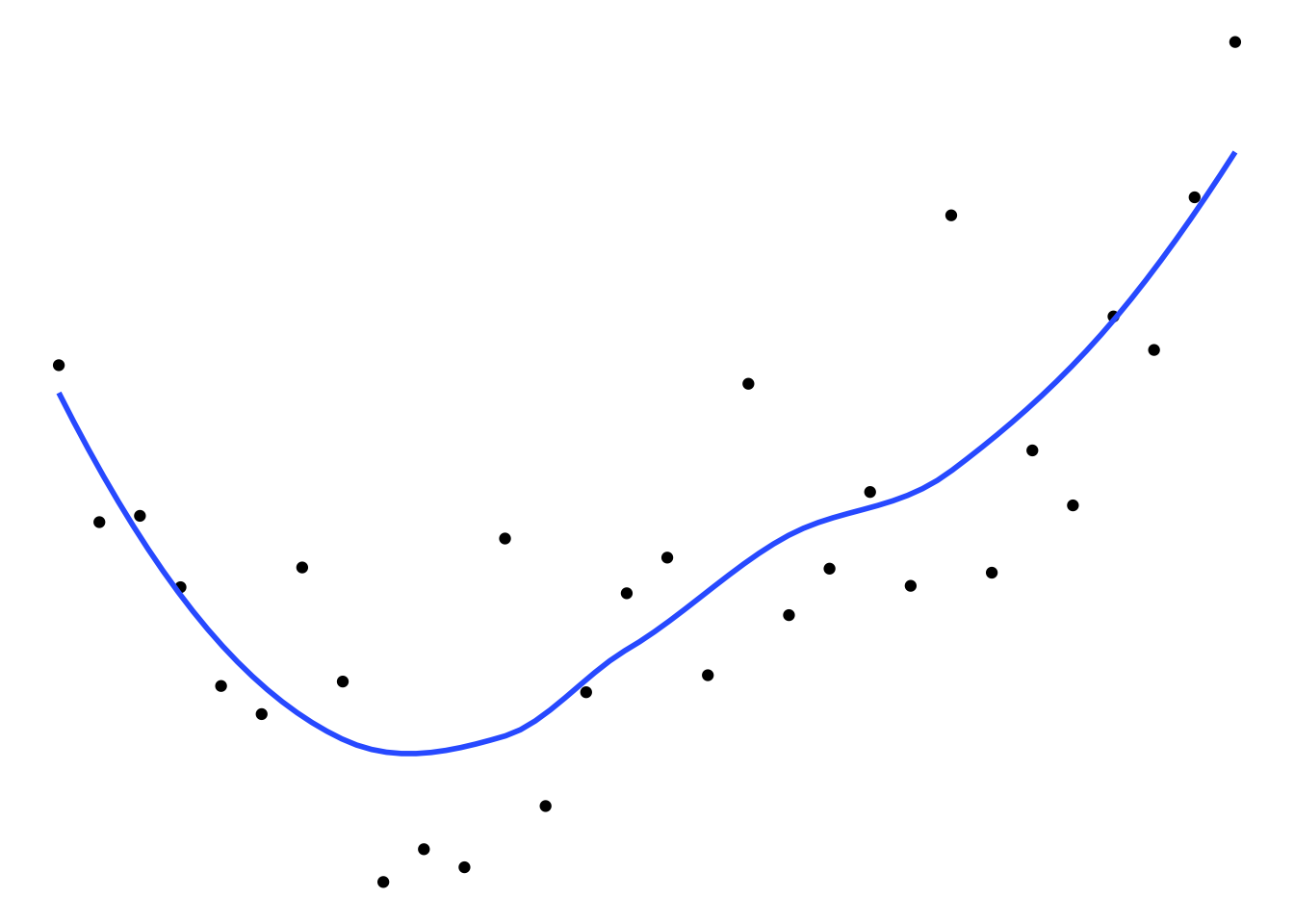
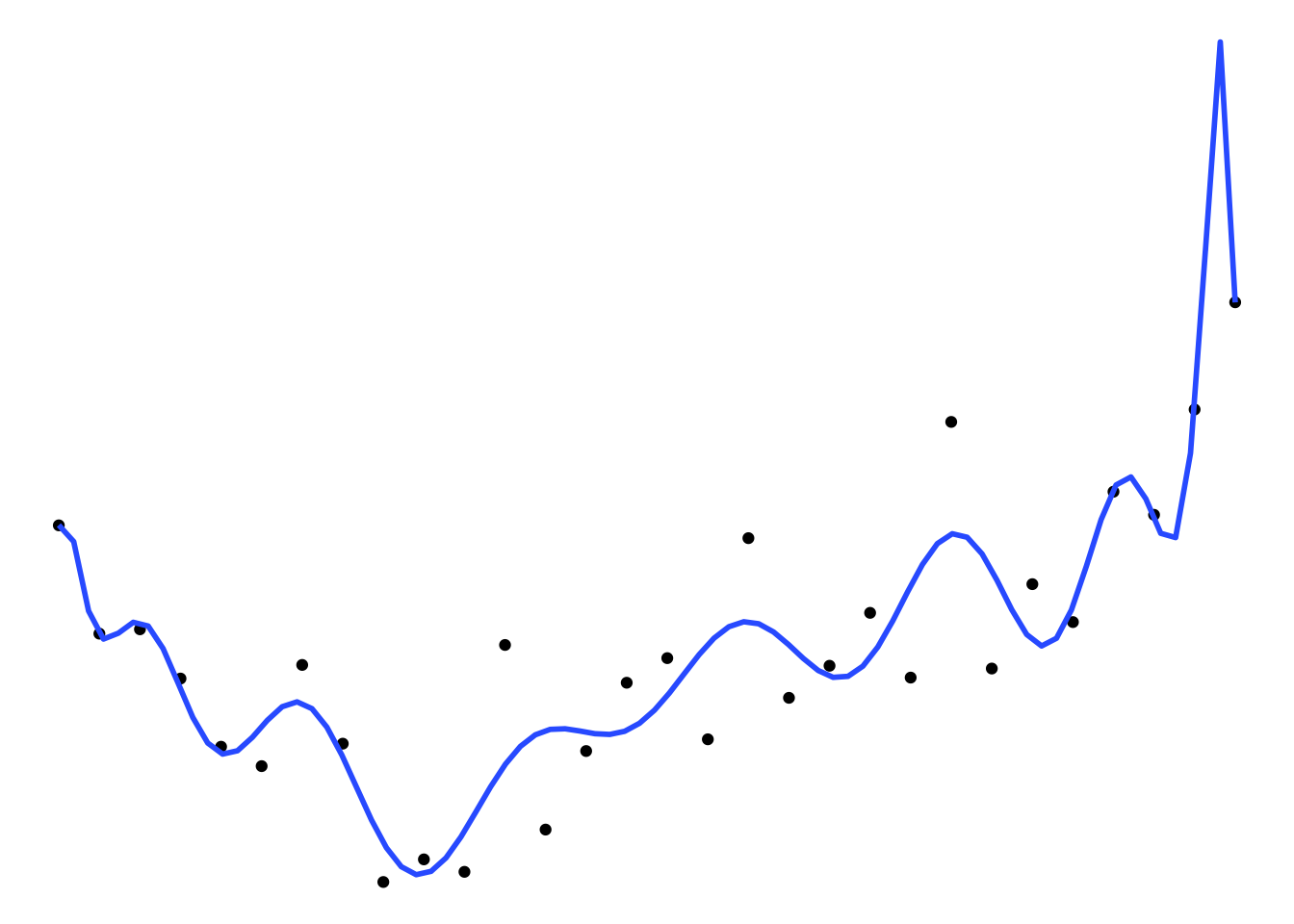
Dans la figure ci-dessous, on voit clairement par exemple que le modèle B est meilleur que le A, ses résidus seront plus petits, et il est mieux ajusté aux données. Mais qu’en est-il du modèle C? Sur les données affichées sur la figure, le modèle C a clairement les plus petits résidus, mais il a aussi un important défaut : il ne généralise pas bien.
A. Modèle sous-ajusté
B. Modèle correctement ajusté
C. Modèle sur-ajusté
Si on va cueillir un nouvel échantillon sur le terrain et qu’on passe les données dans ces modèles, les résidus du modèle C seront inévitablement plus grands que ceux du B, parce que le modèle est non seulement ajusté au patron dans nos données, mais il s’est aussi ajusté au bruit.
On qualifie en général les modèles comme le C de sur-ajustés. Ils ont un pouvoir prédictif plus faible si on leur présente de nouvelles données.
Dans notre quête du meilleur modèle statistique pour décrire un phénomène, notre but sera donc de trouver un modèle qui à la fois (1) explique bien (2) prédit bien mais (3), qui n’est pas sur-ajusté.
29.4 Équivalence
En écologie, en plus des questionnements mentionnés ci-dessus, nous devons souvent gérer un problème supplémentaire. Puisque les variables prédictives sont souvent corrélées entre-elles, il peut être difficile d’en distinguer les effets, au point où il peut arriver que plusieurs modèles puissent faire un travail équivalent.
C’est quelque chose qu’il est important de garder en tête.
Avertissement
Il ne sera pas toujours possible de trancher!
29.5 Alors, comment choisir le meilleur modèle?
La façon de choisir le meilleur modèle est un sujet extrêmement complexe, où il y a des divergences d’opinions extrêmes. Dans certains cas, nous pouvons presque parler de guerres saintes tellement les arguments sont campés et basés sur de fortes croyances.
Puisque nous ne pouvons pas savoir à l’avance ce que vos supérieurs (directeurs de thèses, patrons etc.) exigeront de vous, nous n’avons d’autre choix que de voir chacune des façons de faire, avec leurs points forts et leurs points faibles.
La sélection du meilleur modèle peut être divisée en deux grands thèmes, soit :
La stratégie de sélection (quelles sont les étapes, comment on ajoute ou on enlève des variables) et
L’évaluation du modèle (sur quoi se base-t-on pour dire si un modèle est meilleur qu’un autre).
29.6 Les 5 stratégies de sélection
Voyons d’abord les différentes stratégies par lesquelles on peut partir d’un modèle statistique (tel que nous l’avions imaginé au début de l’expérience) au meilleur modèle, tel qu’il devra être communiqué aux lecteurs ou aux gestionnaires.
29.6.1 Tout garder
La première stratégie de sélection du meilleur modèle est aussi la plus simple. Elle consiste simplement à tout garder. C’est-à-dire, ne pas tenter de simplifier notre modèle en enlevant des variables.
Cette stratégie est peu employée. On la voit surtout dans les approches bayésiennes. Elle est particulièrement appropriée si votre modèle est simple (i.e. peu de variables) et que, surtout, vous avez choisi vos variables avec soin. Si vos variables ont toutes d’excellentes raisons biologiques de se retrouver dans le modèle et qu’il n’y a pas de long shot, i.e. de variables insérées “juste pour voir”, cette stratégie peut alors être appropriée.
Les partisans (en général) de cette approche voient la nature comme un système où tout est relié. Leur but est alors non pas de tester des hypothèses, mais d’estimer le mieux possible chacun des paramètres. De quantifier chacune des forces, aussi faible soit-elle.
29.6.2 Exhaustive
Cette deuxième stratégie consiste à tester toutes les combinaisons de variables pour trouver la meilleure. Si notre jeu de données contient par exemple les variables explicatives A, B et C, nous devrons ajuster et comparer les modèles :
Y ~ A + B + C
Y ~ A + B
Y ~ A + C
Y ~ B + C
Y ~ A
Y ~ B
Y ~ C
Y ~ 1 (i.e. aucune variable).
En principe, il s’agit de la meilleure stratégie, parce qu’on est certain que la meilleure combinaison de variables sera trouvée.
Par contre, l’ajustement des modèles peut être particulièrement long. Si votre jeu de données contenait six variables, vous devrez tester 64 (26) modèles différents. Cette approche est d’ailleurs parfois critiquée parce qu’elle va “à la pêche au modèle” en essayant beaucoup de combinaisons.
29.6.3 Par ajout (forward selection)
Le but de la méthode par ajout est de s’éviter de tester toutes les combinaisons possibles de variables, en utilisant une méthode itérative de construction qui nous permet de rapidement faire le tri.
Dans cette stratégie, on commence par ajuster un modèle vide, n’incluant aucune variable explicative. Ensuite, on ajoute progressivement des variables, en commençant par la meilleure (nous reviendrons sur comment le savoir), jusqu’à une valeur seuil où les variables non-ajoutées n’améliorent plus le modèle.
Ce seuil peut être un test d’hypothèse ou une statistique d’ajustement.
29.6.4 Par élimination (backward selection)
Cette stratégie est l’inverse de la précédente. On commence par un modèle complet contenant toutes les variables. On supprime ensuite progressivement des variables du modèle, jusqu’au seuil où ne peut plus supprimer de variables sans dégrader le modèle de façon importante.
Encore une fois, ce seuil peut être un test d’hypothèse ou une statistique d’ajustement.
29.6.5 Comparaison
Contrairement à la méthode exhaustive, les méthodes par ajout et par élimination ne garantissent pas que le meilleur modèle sera trouvé.
La méthode par ajout aura tendance à bien fonctionner lorsque les variables sont indépendantes (non-corrélées) alors que la méthode par élimination aura tendance à donner un meilleur portrait de la situation lorsque les variables sont corrélées entre-elles.
29.6.6 Hybride (stepwise)
La méthode hybride combine les meilleurs côtés des approches par ajout et par élimination.
Elle démarre avec un modèle vide. Puis, à chaque étape, elle teste pour l’ajout de chaque variable présentement absente du modèle ET la suppression de chaque variable déjà incluse dans le modèle.
Par contre, cela ne garantit pas non plus que le meilleur modèle sera nécessairement trouvé, mais ça augmente nos chances.
29.6.7 Controverses
Les stratégies par ajout, par élimination et hybride sont particulièrement controversées.
D’abord, parce que changer la valeur seuil du test d’hypothèse changera souvent le modèle sélectionné. On voit souvent p. ex. un seuil d’ajout à p < 0,1 plutôt que p < 0,05, ce qui inévitablement inclura plus de variables dans le modèle final.
Ces méthodes augmentent aussi l’erreur de type I, puisque l’on applique souvent beaucoup de tests. Même si notre seuil est à p < 0,05, si on effectue 10 tests, notre taux d’erreur de type I effectif sera plutôt de 0,5 (10 x 0,05; i.e. une chance sur deux de trouver quelque chose quand il n’y avait rien).
29.7 3 méthodes d’évaluation des modèles
Voyons maintenant trois façons différentes de comparer des modèles lorsque l’on applique les stratégies de sélection vues ci-haut.
29.7.1 Tests d’hypothèses
Comme nous avons vu lors des cours précédents, on peut déterminer si une variable est statistiquement significative dans un modèle en comparant l’augmentation de variance expliquée fournie par une variable à la variance des résidus du modèle complet par un test de F partiel.
Cette méthode ne s’applique qu’aux 3 stratégies controversées (par ajout, par élimination et hybride). Aussi, elle ne s’applique qu’à des modèles imbriqués. C’est-à-dire qu’elle peut par exemple comparer
Y ~ A + B vs. Y ~ A
mais elle ne peut pas comparer
Y ~ A + B vs. Y ~ C + D
29.7.2 Labo : Les approches par tests d’hypothèses
Les tests d’hypothèses sont en général combinés soit à l’approche par ajout ou par élimination. Nous verrons donc ces deux façons de faire ici.
Pour toutes les approches, nous réutiliserons le modèle de régression multiple développé au Chapitre 28, sur lequel nous essaierons chacune des techniques.
Donc, commençons par charger nos librairies, et à préparer notre tableau de données.
library(tidyverse)library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
Pour débuter l’approche par ajout, il faut d’abord se créer un modèle de régression vide, dans lequel il n’y a aucune variable explicative. On met uniquement l’ordonnée à l’origine dans le modèle (oui, c’est bizarre la première fois qu’on entend ça!).
Habituellement, quand on spécifie la formule d’un modèle de régression dans R, on a pas besoin de parler de l’ordonnée à l’origine, R en met une pour nous automatiquement. Par contre, quand il n’y a aucune variable, il faut la spécifier nous-même, en mettant ~ 1 à droite de la formule :
modele1 <-lm(body_mass_g ~1, data = pour_regression_multiple)
Ensuite, la façon la plus simple d’organiser notre méthode par ajouts est de se préparer une formule, contenant toutes les variables que l’on voudrait essayer de mettre dans notre modèle :
Remarquez que l’on ne met rien à gauche de cette formule. C’est comme une formule partielle.
Ensuite, il existe dans R une fonction nommée add1, dans laquelle R essaie pour nous chacun des termes d’une formule qui ne sont pas déjà dans le modèle :
La sortie de add1 contient plusieurs lignes, une pour chaque variable que R a essayé d’ajouter. On a ensuite, pour chacun des modèles testés, les degrés de liberté (Df), la somme des carrés (Sum of Sq), la somme des carrés des résidus (RSS), l’AIC (nous en discuterons plus bas), la valeur de F et la valeur de p.
Quand on voit ce tableau, puisque l’on est en mode ajout de variable, ce qui nous intéresse est de savoir quelle variable était la plus significative. Pour se faire, on cherche la valeur de p la plus petite. Comme ici toutes les valeurs de p sont significatives et arrondies à 2,2x10-16, on se fiera à la valeur de F la plus grande.
Dans notre cas, la valeur de F la plus élevée est celle de la longueur des ailes, à 1070,745. On décide d’ajouter cette variable officiellement dans notre meilleur modèle.
Note
Remarquez qu’individuellement, l’ajout de toutes nos variables produit un résultat statistiquement significatif. Cependant, il faut tout de même suivre la procédure puisqu’une fois la première variable insérée dans le modèle, il est possible qu’en ajouter une seconde ne produise pas de résultat significatif. Cela arrivera fréquemment dans les situations de colinéarité, où des variables peuvent être essentiellement redondantes.
On se crée donc un deuxième modèle, qui contient cette nouvelle variable en plus de celles qui y étaient déjà (ici, aucune).
modele2 <-lm(body_mass_g ~ flipper_length_mm, data = pour_regression_multiple)
Une fois que c’est fait, on peut refaire la commande add1, pour que R teste tous les termes restants :
add1(modele2, scope = termes, test ="F")
Single term additions
Model:
body_mass_g ~ flipper_length_mm
Df Sum of Sq RSS AIC F value
<none> 52854796 4090.3
bill_length_mm 1 211671 52643125 4090.9 1.3631
bill_depth_mm 1 449044 52405752 4089.4 2.9048
Pr(>F)
<none>
bill_length_mm 0.24383
bill_depth_mm 0.08924 .
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
La fonction add1 a donc tenté d’ajouter, séparément, les variables de longueur et d’épaisseur du bec au modèle contenant déjà la longueur des ailes. On répète donc encore la même procédure : quelle est la variable avec la valeur de p la plus faible? Est-elle significative?
Dans ce cas-ci, la valeur de p la plus faible est celle de l’épaisseur du bec, mais sa valeur de p (0,089) est > 0,05. On ne l’ajoute donc pas au meilleur modèle et la procédure s’arrête ici.
La sélection du meilleur modèle par ajout de variables s’arrête toujours ainsi, au moment où aucun des termes testés n’apporte un ajout significatif au modèle. Le meilleur modèle, tel que sélectionné par cette approche, est donc celui qui ne contenait que la variable de longueur des ailes.
modele_final <- modele2
Avec les tests d’hypothèses, on aurait aussi pu appliquer la méthode par élimination. Pour se faire, on doit plutôt commencer par un modèle complet :
Par contre, ici, il ne faut pas oublier que l’on est en mode élimination. On veut enlever les termes inutiles, ceux qui ne font PAS de différence significative. On cherche donc la valeur de p la plus grande.
Ici, c’est celle associée à la longueur du bec (p=0,4354). Comme enlever cette variable ne fait pas de différence significative sur le modèle (p > 0,05), on peut l’éliminer :
Puis, on rappelle drop1 sur ce nouveau modèle pour que R essaie d’enlever chacun des termes restants :
drop1(modele2, test ="F")
Single term deletions
Model:
body_mass_g ~ flipper_length_mm + bill_depth_mm
Df Sum of Sq RSS AIC
<none> 52405752 4089.4
flipper_length_mm 1 118061166 170466918 4490.8
bill_depth_mm 1 449044 52854796 4090.3
F value Pr(>F)
<none>
flipper_length_mm 763.7088 < 2e-16 ***
bill_depth_mm 2.9048 0.08924 .
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
On cherche à nouveau la valeur de p la plus grande. Ici, c’est l’épaisseur du bec (p = 0,089). Comme enlever cette variable n’aurait pas d’impact significatif (p > 0,05), on peut aussi l’enlever du modèle :
Puis on essaie d’enlever les variables restantes. Ici il ne nous reste que la longueur des ailes, mais il important de tout de même tester.
drop1(modele3, test ="F")
Single term deletions
Model:
body_mass_g ~ flipper_length_mm
Df Sum of Sq RSS AIC
<none> 52854796 4090.3
flipper_length_mm 1 166452902 219307697 4574.9
F value Pr(>F)
<none>
flipper_length_mm 1070.7 < 2.2e-16 ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
On répète à nouveau la procédure : chercher la valeur de p la plus grande, et vérifier si elle est significative.
Ici, la valeur de p la plus grande (la seule) est celle de la longueur des ailes (p=2,2x10-16). Comme sa valeur de p est < 0,05, on ne peut PAS l’enlever du modèle. L’éliminer aurait un impact significatif.
Notre meilleur modèle est donc le modèle 3, qui ne contenait que la longueur des ailes.
modele_final <- modele3
Note
Autant dans la méthode par ajout que dans la méthode par élimination, il pourrait arriver que votre meilleur modèle soit le modèle vide, avec uniquement l’ordonnée à l’origine. Si ça vous arrive, vos hypothèses étaient probablement erronées ou votre puissance statistique trop faible. Et ça arrive plus souvent qu’on voudrait se l’avouer…
29.7.3 Explication de la variance
Intuitivement, le R2 peut sembler une bonne mesure de comparaison de modèles, puisqu’il est, entre autres, utilisable dans tous les types de stratégies. Mais comme discuté précédemment, le R2 ne permet pas de comparer des modèles incluant un nombre différent de variables, puisque le R2 ne peut qu’augmenter lorsque l’on ajoute des variables.
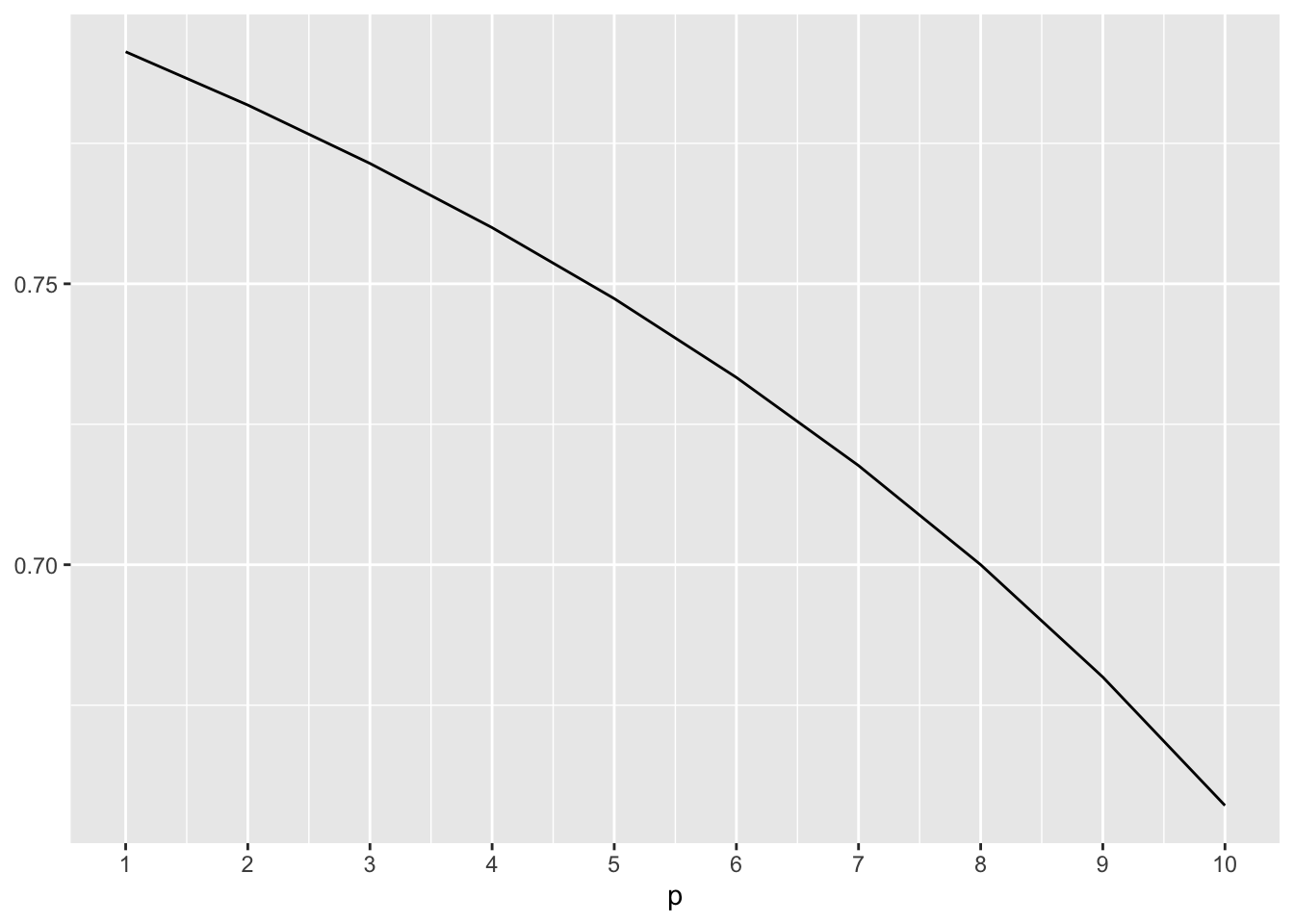
Il existe une version modifiée du R2, le R2-ajusté qui elle est adaptée à ce genre de situation. Ce dernier est pénalisé pour la complexité du modèle. Il augmente donc en fonction de l’ajustement, mais il diminue en fonction du nombre de paramètres (nombre de variables):
\[ {\bar {R}}^{2}=1-(1-R^{2}){n-1 \over n-p-1} \]
Si par exemple, nous avons un R2 de 0,80, un n de 25 et une seule variable, puis qu’on tente d’en ajouter des inutiles au modèle, le R2-ajusté diminuera ainsi :
Même dans sa version ajustée, plusieurs auteurs ont par contre montré que, bien que ce chiffre soit une excellente statistique descriptive, il favorise dans certaines situations des modèles sur-ajustés.
De plus, puisque les transformations affectent la variance, le R2, même ajusté, ne peut pas être utilisé pour comparer des modèles avec différentes transformations de la variable en Y.
L’autre problème posé par le R2-ajusté est que, lorsque nous sommes confrontés à plusieurs modèles équivalents (c’est souvent le cas en écologie), il ne permet pas de quantifier la probabilité que chacun de ces modèles soit individuellement le meilleur. Remarquez que la méthode basée sur les tests d’hypothèses ne permettait pas non plus de faire de telles affirmations probabilistes.
Néanmoins, comme pour les tests d’hypothèses, le R2-ajusté demeure grandement utilisé dans la littérature.
29.7.4 Labo : L’approche basée sur le R2-ajusté
La façon la plus commune d’utiliser le R2-ajusté dans la sélection de modèle est en le combinant avec une approche exhaustive, où toutes les combinaisons de variables sont testées. On pourrait évidemment créer chacun de ces modèles nous-mêmes, mais il existe dans R plusieurs façons d’automatiser ce travail. Je vous propose ici d’utiliser la fonction dredge de la librairie MuMin, puisque c’est aussi cette dernière que nous utiliserons dans la section suivante.
Créons d’abord un modèle complet contenant toutes les variables d’intérêt :
Remarquez qu’il faut ajouter l’option na.action = "na.fail" lorsque l’on utilise des fonctions associées à MuMin. Nous en reparlerons plus bas…
Comme la fonction dredge n’est pas habituellement utilisée pour le R2-ajusté, nous devrons passer un argument supplémentaire pour l’ajouter aux sorties, et classer les sorties sur cette variable :
Il y a beaucoup de matériel dans cette sortie. Ce tableau contient une ligne par modèle testé. Les premières colonnes [(Int),bll_dpt_mm, etc.] contiennent les estimés de pentes pour chacune des variables dans le modèle, incluant l’ordonnée à l’origine (Int). Remarquez que la fonction a fait son possible pour raccourcir le nom de nos variables pour réussir à les entrer dans le tableau.
La seule autre colonne qui nous intéresse pour le moment est adjR^2, le R2-ajusté de chacune de ces combinaisons.
Ici, on voit donc que le meilleur modèle était celui contenant toutes les variables : la longueur des ailes, la longueur du bec et l’épaisseur du bec. Le modèle modèle ne contenant pas la longueur du bec et celui ne contenant pas l’épaisseur du bec sont TRÈS près derrière.
Remarquez que ce résultat est différent des deux précédents. Avec le R2-ajusté, on aurait classé TOUTES les variables comme importantes.
29.7.5 Le Critère d’information d’Akaike (AIC)
Avant de présenter la troisième méthode d’évaluation, il faut d’abord mettre en place un nouveau concept. Le critère d’information d’Akaike (AIC) est basé sur un tout autre paradigme que ce que l’on a vu jusqu’à maintenant dans le cours. Plutôt que de se baser sur les principes des moindres carrés, il provient de la théorie de l’information1.
L’AIC mesure l’information perdue, par rapport à la réalité, lorsque l’on utilise un modèle statistique pour la représenter. Tout comme le R2-ajusté, il pénalise aussi pour la complexité (le nombre de paramètres) du modèle.
La formulation exacte de l’AIC ressemble à ceci : \[
AIC=2k-2\ln(L)
\] Où k est le nombre de paramètres dans le modèle et L est le maximum de la fonction de vraisemblance du modèle. Sans aller dans les détails, la fonction de vraisemblance mesure à quel point les données observées sont probables pour une combinaison de paramètres en particulier.
Mise en garde
Attention, puisque l’AIC mesure l’information perdue, les meilleurs modèles auront un AIC plus faible.
L’utilisation de l’AIC est en forte augmentation depuis 15 ans environ. Il permet de comparer des modèles non-imbriqués (contrairement aux tests d’hypothèses). Il permet aussi de comparer la probabilité que différents modèles soient les meilleurs. Contrairement au R2, il est aussi défini pour des modèles plus complexes comme les GLM (Generalized Linear Models) et les modèles mixtes. Enfin, il a moins tendance à sélectionner des modèles sur-ajustés comparé aux approches précédentes.
Par contre, l’AIC ne renseigne pas directement sur l’ajustement du modèle. Il exprime uniquement la performance relative d’un modèle par rapport à un autre. La valeur d’AIC ne s’interprète que de façon relative, entre plusieurs modèles expliquant la même variable expliquée. Sa valeur n’est pas interprétable dans l’absolu. Il faut donc souvent combiner l’AIC avec une valeur de R2 pour discuter de la qualité générale de notre meilleur modèle. L’approche par l’AIC ne fournit pas non plus de valeur de p, ce qui peut être embêtant si votre directeur ou votre éditeur vous en exige.
De plus, il est important de garder en tête que la pénalité pour le nombre de paramètres (k) est arbitraire dans le calcul de l’AIC. Plusieurs alternatives existent, pénalisant de différentes façons. Entre autres le BIC remplace la pénalité de \(2\times k\) de l’AIC par \(k\times ln(N)\) où N est le nombre d’observations. Le BIC est donc une version plus conservatrice.
Comme l’AIC en absolu ne s’interprète pas, on interprète plutôt les différences d’AIC entre deux modèles, que l’on nomme delta AIC en anglais. En général, on interprète le delta AIC comme ceci :
0-2 Niveau de support substantiel pour ce modèle
4-7 Considérablement moins de support
>10 Essentiellement aucun support pour ce modèle
Note
Remarquez que l’AIC n’est pas un test statistique comme tel. Le tableau précédent ne sert qu’à guider vos interprétations. Pas à mettre des barèmes tranchés.
29.7.6 L’inférence multi-modèle
En se basant sur les delta AIC, il est possible de calculer la probabilité que tel ou tel modèle soit le meilleur (parmi ceux testés). Cette statistique s’appelle le poids d’Akaike (Akaike weight). Voici un exemple de tableau contenant tous ces chiffres :
Modèle
AIC
Delta AIC
Akaike weight
A
21
0
0.989
B
30
9
0.011
C
80
59
0.000
D
118
97
0.000
Dans ce cas, le modèle A est clairement meilleur que les autres, puisque son poids d’Akaike est de 0,989. Autrement dit, parmi les modèles testés, il y a 98,9 % des chances que le A soit le meilleur.
Par contre, il peut arriver que le poids d’Akaike ne permette pas de trancher clairement entre deux modèles, par exemple dans ce jeu de données :
Modèle
AIC
Delta AIC
Akaike weight
X
1001
1
0.37
Y
1000
0
0.62
Z
1008
8
0.01
Le modèle X a plus du tier des chances d’être le meilleur modèle pour expliquer nos données. Il ne peut pas être mis facilement de côté. Dans un cas comme celui-là, il faut être clair lorsque l’on décrit nos résultats: le meilleur modèle est Y, mais le X ne peut pas être exclu non plus. Il peut être utile de faire le ratio des deux poids d’Akaike, pour affirmer par exemple que le modèle Y est 1,68 fois plus probable que le X (0,62/0,37).
Puisque dans chacun de ces modèles raisonnables nous avions calculé un estimé de pente, lequel des estimés de pente est le plus représentatif de la réalité? En fait, aucun. L’approche par l’AIC nous permet de calculer une pente (et un intervalle de confiance) qui tient compte de cette incertitude entre les modèles.
Le calcul se fait à l’aide d’une moyenne pondérée, basée sur le support (poids d’Akaike) associé à chacun des estimés.
Si par exemple nous avions deux modèles, A et B, ayant un poids d’Akaike respectif de 0,6 et 0,4. Dans chaque modèle, nous avons estimé une pente pour la variable X, qui était de 2 dans un cas et 2,5., dans l’autre. La valeur pondérée, considérant notre incertitude quant au meilleur modèle serait donc de 0,6 * 2 + 0,4 * 2,5 = 2,2
De la même façon, puisque certaines variables seront absentes ou présentes dans certains modèles, on peut se demander quelle est notre certitude qu’une variable fasse partie du meilleur modèle. Prenons par exemple les données suivantes :
Modèle
AIC
delta AIC
Akaike weight
a
21
0
0.86
b
30
9
0.01
c
80
59
0.00
a + b
118
97
0.00
b + c
25
4
0.12
a + c
31
10
0.01
a + b + c
50
29
0.00
L’importance relative d’une variable (sa probabilité de faire partie du meilleur modèle) se calcule comme la somme des poids d’Akaike de tous les modèles où elle est présente :
Importance relative de a : 0,86 + 0,00 + 0,01 + 0,00 = 0,87
Importance relative de b : 0,01 + 0,00 + 0,12 + 0,00 = 0,13
Importance relative de c : 0,00 + 0,12 + 0,01 + 0,00 = 0,13
Nous sommes donc vraiment sûr que a fait partie du meilleur modèle, mais très peu d’évidences que b ou c en font partie.
29.7.7 L’AICc
L’AIC, dans sa définition originale, était défini pour de grands jeux de données. Lorsque notre échantillon est petit, il faut plutôt utiliser l’AICc, qui contient une correction pour les petits échantillons. L’AICc nous évite de sélectionner accidentellement des modèles sur-ajustés (trop complexes).
On recommande en général d’utiliser l’AICc lorsque n/k est < 40, où n est notre nombre d’observations et k est le nombre de paramètres dans le modèle.
Par contre, vous ne vous tromperez jamais en utilisant systématiquement l’AICc, puisque sa valeur converge vers l’AIC quand n est grand ou k est petit.
29.7.8 Labo : L’inférence multimodèle basée sur l’AICc.
Plusieurs librairies de R nous permettent de calculer des valeurs d’AIC, entre autres le libraire car (comme voiture en anglais) que nous utilisons pour calculer le VIF. Cependant, certaines fournissent aussi une série de fonctions nous permettant de mettre en application toute l’approche d’inférence multi-modèle. Nous en verrons une ici, soit la librairie MuMIn (MUlti Model INference), que nous avons d’ailleurs déjà utilisé plus haut pour l’approche par explication de la variance.
Ensuite, il faut, comme pour l’approche par élimination, ajuster un modèle complet contenant toutes les variables qui pourraient nous intéresser. Il faut cependant ajouter une petite option supplémentaire à notre modèle, pour lui demander de planter si il trouve des NA, plutôt que de simplement enlever ces lignes sans nous en parler.
La raison est que la valeur d’AIC dépend du nombre d’observations dans notre tableau de données. Si on ne met pas cette option, il pourrait arriver que certaines lignes soient absentes de certains modèles à cause de valeurs manquantes, mais apparaissent dans d’autres où ces variables ne font pas partie du modèle, ce qui fausserait l’interprétation des valeurs d’AIC.
Ensuite, une fois ce modèle complet ajusté, on peut demander à MuMIn de calculer l’AICc pour toutes les combinaisons de variables possibles, avec la fonction dredge (littéralement draguer, comme dans ramasser tout ce qu’on trouve au fond de la piscine à modèles).
Les dernières colonnes (à partir de df) contiennent les statistiques d’ajustement. Celles qui nous intéressent sont les 3 dernières, soit l’AICc, le delta AICc et le poids d’Akaike.
Selon le poids d’Akaike (la colonne weight), le modèle le plus probable pour nos données serait celui contenant l’épaisseur du bec et la longueur des ailes. Ce modèle a seulement 38,5% des chances d’être le meilleur. Tout près derrière se trouve le modèle contenant uniquement la longueur des ailes (delta = 0,87), qui a lui 24,9% des chances d’être le meilleur. Le meilleur modèle est donc à peine une fois et demie plus probable que le second modèle (0.39/0.25=1.55). Deux autres modèles sont aussi raisonnablement bons derrière, avec des poids d’Akaike de 0,187 et 0,178.
Comme c’est souvent le cas en écologie, on a donc plusieurs modèles presque équivalents, et il est difficile de trancher. C’est donc ici où l’approche d’inférence multimodèle prend tout son sens pour bien gérer ces nuances.
Note
Remarquez que contrairement à l’approche basée sur les tests d’hypothèses, il n’y a pas de seuil pré-établi au delà duquel on peut considérer qu’un modèle se distingue clairement des autres. Est-ce qu’un poids d’Akaike de 0,80 est suffisant? 0,90? Vous devrez utiliser votre jugement…
Comme vous le remarquez dans le tableau fourni par dredge, les estimés de chacun des paramètres varient d’un modèle à l’autre. Entre autres, l’estimé pour la pente partielle de la longueur des ailes est de 51,54 dans le premier modèle, 49,69 dans le second et ainsi de suite. Quelle est alors la valeur la plus probable pour nos estimés de paramètres?
On peut demander à MuMIn de nous calculer une valeur pondérée, qui tient compte du fait qu’il y a 38% des chances que la vraie valeur soit 51,54, 25 % des chances que ce soit 48,69, etc. La fonction pour le faire se nomme model.avg (pour Model Averaging) :
Il y a BEAUCOUP de matériel dans ce tableau, mais les premières sections sont essentiellement redondantes avec les chiffres que nous avons vu précédemment dans la sortie de dredge. La section qui nous intéresse est celle nommée Model-averaged coefficients. Vous remarquerez que cette section ressemble beaucoup à celle fournie par une régression linéaire multiple, mais qu’elle comporte deux parties (full average et conditional average).
La présence de deux séries de chiffres s’explique par une question : qu’est-ce qu’on fait avec notre moyenne pour les modèles où la variable n’était pas présente? Dans la section full average, MuMIn assume que pour ces fois, la valeur de la pente était de zéro. Au contraire, dans la section conditional average, le calcul ne fait la moyenne que des fois où le terme était présent dans le modèle. L’estimé dans full average est plus conservateur (proche de zéro), alors que celui de conditional average nous informe que, si la variable est importante, voici ce que serait sa valeur.
On peut aussi tenir compte de cette nuance lorsque l’on calcule les intervalles de confiance de nos paramètres :
Remarquez que pour les variables qui font clairement partie du meilleur modèle (i.e. la longueur des ailes) les valeurs sont très semblables, alors que pour les autres, on observe une grande différence.
Enfin, si on veut calculer l’importance relative de chaque variable (sa probabilité de faire partie du meilleur modèle), on peut lancer la fonction nommée sw (sum of weights) sur la liste de modèles fournie par dredge :
sw(liste_modeles)
flipper_length_mm bill_depth_mm
Sum of weights: 1.00 0.57
N containing models: 4 4
bill_length_mm
Sum of weights: 0.37
N containing models: 4
On voit dans ces résultats que la longueur des ailes fait clairement partie du meilleur modèle (100% des chances), l’épaisseur du bec à plus de la moitié des chances (57%) et la longueur du bec n’en fait probablement pas partie (seulement 37% des chances).
Ces informations sont nettement plus nuancées que celles provenant des tests d’hypothèses ou de l’approche par le R2-ajusté, qui tranchaient de façon beaucoup plus drastique.
Comme mentionné dans la présentation de l’AIC, ce dernier ne nous informe pas si un modèle est bon ou non. Il ne fait que nous informer sur la performance relative de modèles les uns comparés aux autres. Il faut donc calculer un r2 pour avoir une idée de la performance globale de notre modèle.
La question ici est de savoir quelles variables inclure dans ce modèle. Il serait légitime d’utiliser les variables présentes dans le modèle présentant le meilleur AIC, mais comme les 3 variables ont une chance raisonnable de faire partie du meilleur modèle, il serait tout aussi correct de le faire avec un modèle contenant les 3 variables.
Comme ces modèles sont très près les uns des autres, le R2 sera très semblable entre ces modèles de toute façon.
modele_final <-lm(body_mass_g ~ flipper_length_mm + bill_depth_mm, data = pour_regression_multiple)summary (modele_final)
Call:
lm(formula = body_mass_g ~ flipper_length_mm + bill_depth_mm,
data = pour_regression_multiple)
Residuals:
Min 1Q Median 3Q Max
-1029.78 -271.45 -23.58 245.15 1275.97
Coefficients:
Estimate Std. Error t value
(Intercept) -6541.907 540.751 -12.098
flipper_length_mm 51.541 1.865 27.635
bill_depth_mm 22.634 13.280 1.704
Pr(>|t|)
(Intercept) <2e-16 ***
flipper_length_mm <2e-16 ***
bill_depth_mm 0.0892 .
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 393.2 on 339 degrees of freedom
Multiple R-squared: 0.761, Adjusted R-squared: 0.7596
F-statistic: 539.8 on 2 and 339 DF, p-value: < 2.2e-16
Notre modèle explique donc 76 % de la variance dans le poids des manchots
29.8 Dans la vraie vie?
Ok, mais là Charles, ça fait un sacré paquet de méthodes pour faire essentiellement la même tâche (et encore, nous en avons laissé plusieurs combinaisons de côté et nous n’avons même pas parlé de l’approche bayésienne!). Laquelle on prend dans la vraie vie?
Impossible de savoir ce que vous aurez à affronter en recherche ou dans votre milieu de travail. Nous sommes dans une période de transition où les tests d’hypothèses sont encore grandement utilisés, le R2-ajusté est utilisé dans beaucoup d’articles et l’AIC et l’inférence multi-modèle prennent de plus en plus de place.
Selon moi, l’inférence multi-modèle avec l’AIC est l’approche la plus utile en écologie, puisqu’elle intègre directement l’incertitude entourant l’approche observationnelle (la plus commune en écologie).
Les tests d’hypothèses ont toujours leur place dans des expériences contrôlées où les facteurs confondants sont correctement pris en compte (par exemple en laboratoire).
Enfin, l’explication de la variance demeurera un but important en écologie, i.e. est-ce qu’on comprend bien ou non un phénomène? Donc les R2-ajustés sont assurément là pour rester aussi.
Une chose est claire par contre, pour chacun de vos projets, choisissez à l’avance la technique que vous allez utiliser, et tenez-vous y. Il est relativement mal vu dans un même projet d’essayer plusieurs méthodes différentes pour sélectionner le meilleur modèle, puisque vous augmentez de beaucoup votre risque de choisir la méthode dont les résultats correspondent à vos attentes plutôt que celle décrivant le mieux la réalité…
29.9 Après avoir choisi le meilleur modèle?
Après avoir choisi le meilleur modèle avec l’aide d’une des méthodes ci-haut, il peut arriver que ce modèle soit différent du modèle complet que vous aviez validé initialement. Dans ce cas, il faut aussi valider ce modèle final (inspection des résidus, colinéarité, valeurs aberrantes, etc.). Les choses peuvent avoir drôlement changé en enlevant des variables.
29.10 Exercice sur la sélection de modèles
À partir du modèle construit dans le chapitre sur la régression multiple pour expliquer le l’abondance des oiseaux dans une parcelle (Section 28.11), appliquez les deux stratégies de sélection du meilleur modèle suivantes :
Méthode par élimination, basée sur les tests d’hypothèses nulles,
Inférence multi-modèle, basée sur l’AIC.
Comparez le résultat de vos deux modèles. Vos conclusions sont-elles différentes ou essentiellement identiques?
Laquelle des deux stratégies correspond le mieux à votre façon de voir la méthode scientifique?
29.2 Comment juger de l’explication?
Comment savoir si un modèle statistique explique bien un phénomène naturel? Une façon classique de le déterminer est de se demander si toutes les variables importantes sont effectivement contenues dans le modèle. Et à l’inverse, si une variable n’est pas importante, est-elle effectivement laissée de côté?