Il vous arrivera souvent dans votre travail d’avoir besoin d’aller plus loin que le fait de savoir que deux variables quantitatives sont corrélées ensemble. Si nous avons en tête un modèle clair de cause à effet, il nous arrivera souvent de vouloir savoir par combien changera une variable expliquée si on modifie la variable explicative. De combien, par exemple, devons-nous réduire nos émissions de carbone pour réduire la température globale de 1°C ? Nous avons besoin de plus qu’un coefficient de corrélation pour répondre à cette question.
Dans ce chapitre, nous irons un peu plus en détail avec la régression linéaire qu’avec d’autres techniques statistiques, puisque beaucoup de techniques que nous verrons en sont des extensions, qui construiront sur les connaissances de ce chapitre. Vous remarquerez que je ne commencerai mon exemple avec des vraies données qu’à la partie Labo du chapitre, pour essayer d’alléger la présentation. J’espère que le message passera quand même bien.
Une question type de la régression linéaire pourrait par exemple être : combien d’espèces d’oiseaux pouvons-nous espérer ajouter à un parc urbain si on ajoute 100 hectares à sa surface protégée? La corrélation ne nous renseigne pas sur ce genre de chiffres. Ce qui nous intéresse ici est de savoir quelle est la pente qui relie nos deux variables.
Si nous calculions une pente de 0,02, cela nous dirait que pour chaque hectare supplémentaire protégé, nous gagnons en moyenne 0,02 espèces. Si on ajoute 100 hectares au parc, on peut donc espérer gagner (0,02*100) 2 espèces. Connaître la pente qui relie deux variables nous permet de passer de quelque chose d’intéressant (une corrélation) à quelque chose de pratique, d’appliqué.
Évidemment, on ne peut pas garantir que notre parc gagnera effectivement ces deux espèces. Il y aura aussi du bruit autour de notre relation, c’est-à-dire d’autres variables qui peuvent aussi avoir une influence et dont nous n’avons pas tenu compte dans notre calcul. Il en gagnera peut-être un peu plus, ou peut-être un peu moins.
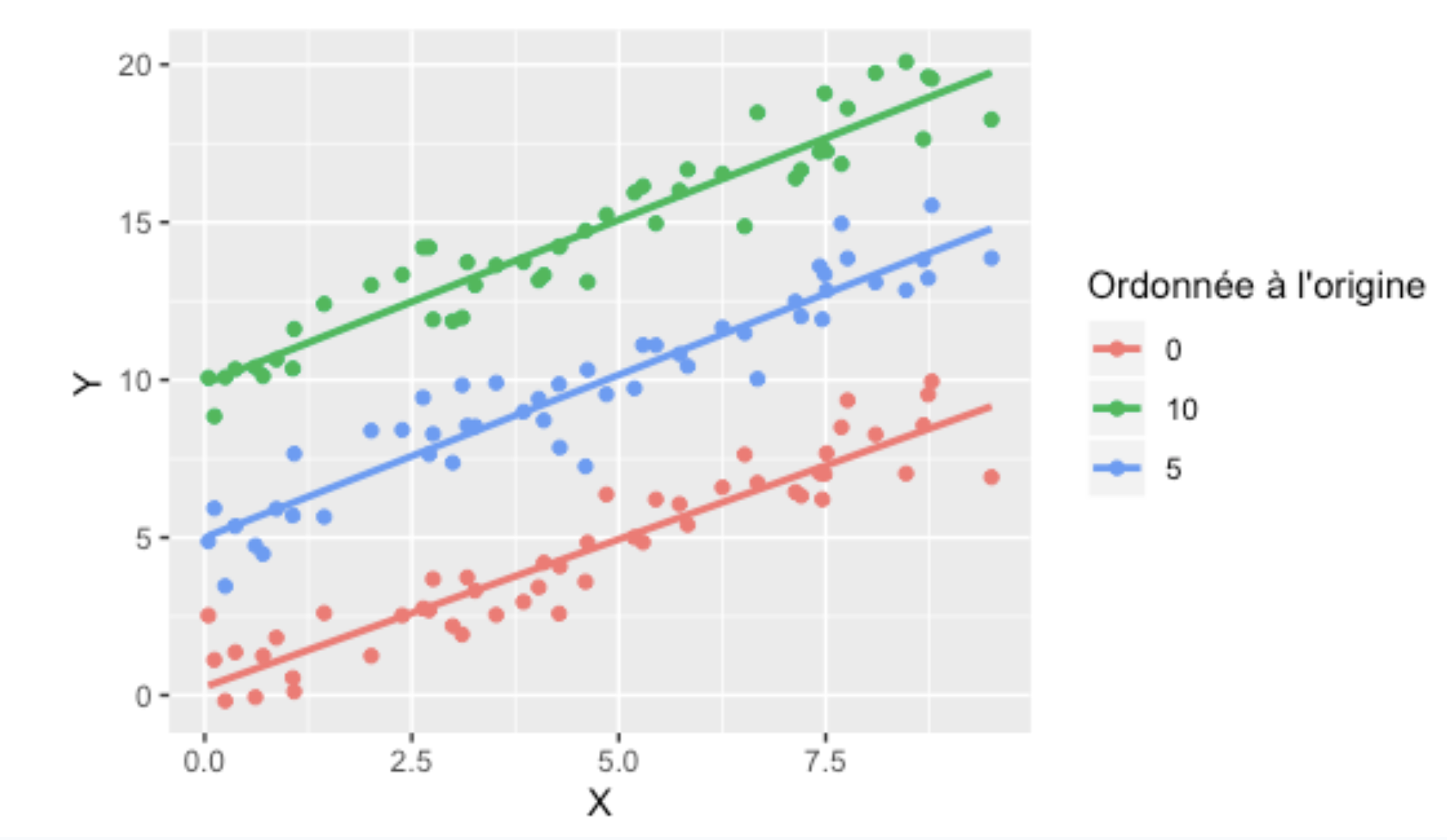
La régression linéaire comprend toujours un second paramètre (outre la pente), soit l’ordonnée à l’origine. L’ordonnée à l’origine nous informe sur la hauteur verticale à laquelle la pente croisera l’axe des Y lorsque X=0. Vous entendrez souvent aussi le terme anglais intercept pour désigner ce second paramètre. Voici un exemple d’une même pente, passant par trois ordonnées à l’origine différentes :
Notez qu’ici nos données s’étendent jusqu’à la valeur X=0, mais dans la plupart des cas, nos données n’iront pas jusque là. L’ordonnée à l’origine est alors le point où la pente croiserait l’axe des Y, si jamais elle s’y rendait.
Vous remarquerez que l’on peut rarement tirer des conclusions biologiques intéressantes de l’ordonnée à l’origine seule, c’est pourquoi nous nous y intéresserons un peu moins dans ce chapitre. Cependant, nous verrons au Chapitre 20 comment comparer l’ordonnée à l’origine entre deux pentes, ce qui peut devenir très intéressant.
18.2 Les assomptions de la régression linéaire
L’estimation de la pente entre deux variables quantitatives peut être effectuée avec une technique nommée la régression linéaire. Avant de la calculer, il importe cependant de s’assurer que nos données correspondent aux assomptions de la technique, qui se comptent au nombre de quatre, soit :
La normalité des erreurs
L’homogénéité de la variance
L’indépendance des observations
X est fixé par l’expérimentateur
Assomption 1 : Normalité des erreurs.
Comme pour le modèle d’ANOVA du Chapitre 15, l’assomption de normalité de la régression linéaire s’applique aux résidus du modèle. Il faut donc vérifier cette assomption après avoir effectué nos calculs plutôt que avant.
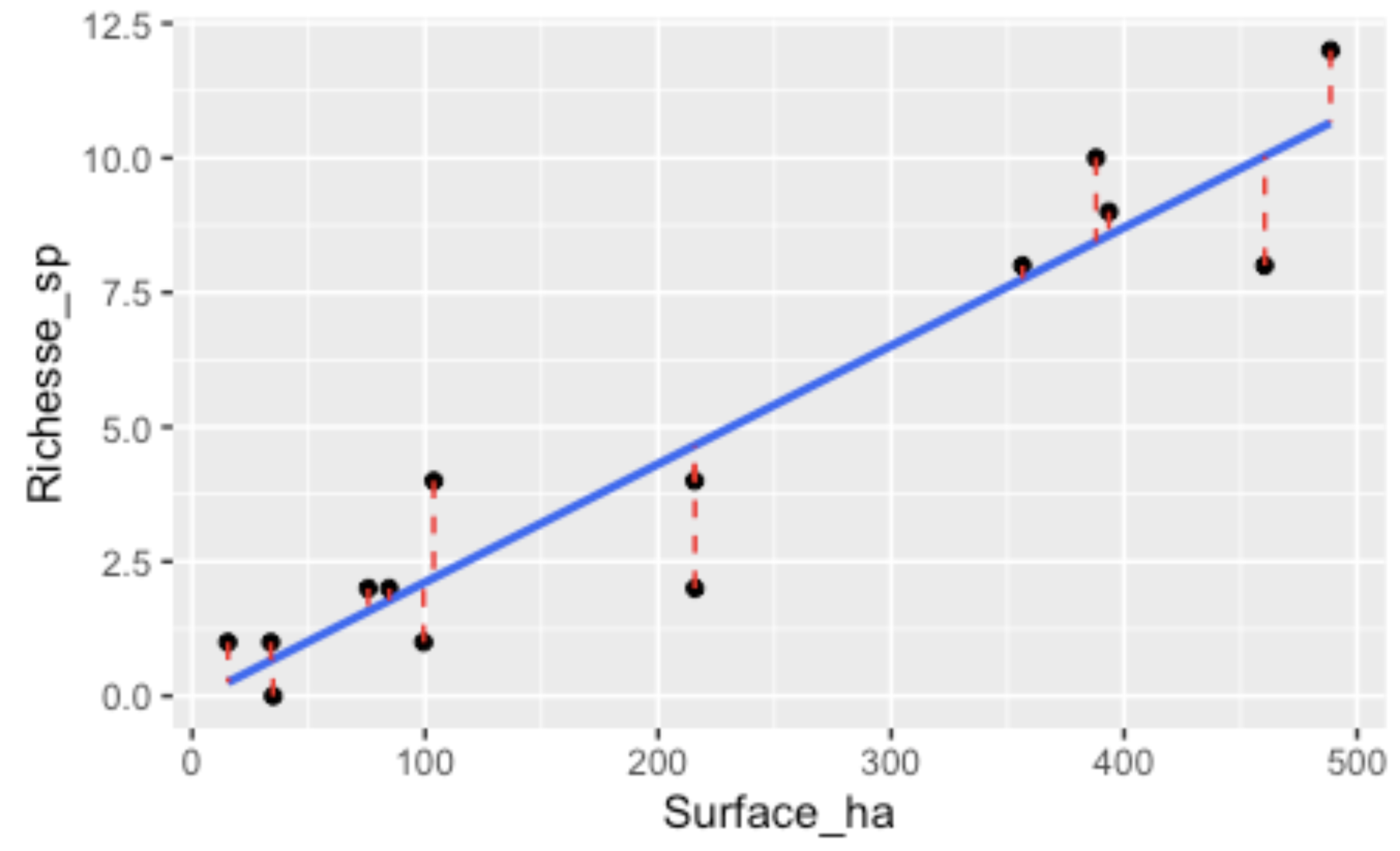
Les résidus d’une régression linéaire sont définis comme la distance verticale entre chaque point observé et la pente de la régression. Autrement dit, pour chaque observation, de combien notre modèle (i.e. la pente) se trompe par rapport à la réalité observée.
\[résidu = observation - prédiction\]
Illustration du concept de résidus d’une régression linéaire. Plus la ligne pointillée rouge est longue, plus le résidu de cette observation est grand.
Plus ces distances sont courtes, plus notre modèle est “bon” (i.e. près de la réalité). Plus ces distances sont grandes, moins notre modèle est bon, plus il est loin de la réalité.
Bien qu’il faille vérifier cette assomption à la fin de la modélisation, il est cependant intéressant de savoir que généralement, les résidus seront distribués normalement si les variables X et Y le sont aussi.
C’est donc toujours une bonne idée de commencer par explorer les histogrammes de fréquences de nos variables avant de débuter l’analyse. Aussi, comme pour beaucoup de tests dans les chapitres précédents, la régression linéaire est relativement robuste aux écarts de normalité en présence de grands échantillons grâce au théorème central limite. Inutile d’utiliser un test strict de normalité comme celui de Shapiro-Wilk. En présence d’observations clairement aberrantes, n’hésitez pas à utiliser des transformations comme expliquées au Chapitre 9.
Assomption 2 : Homogénéité de la variance
Nous avons énoncé le concept d’homogénéité de la variance au Chapitre 14 sur les tests de comparaison de variance. Dans la régression linéaire, les choses sont cependant un peu plus complexes. On parle ici de variance à travers un gradient plutôt que de variance entre des groupes.
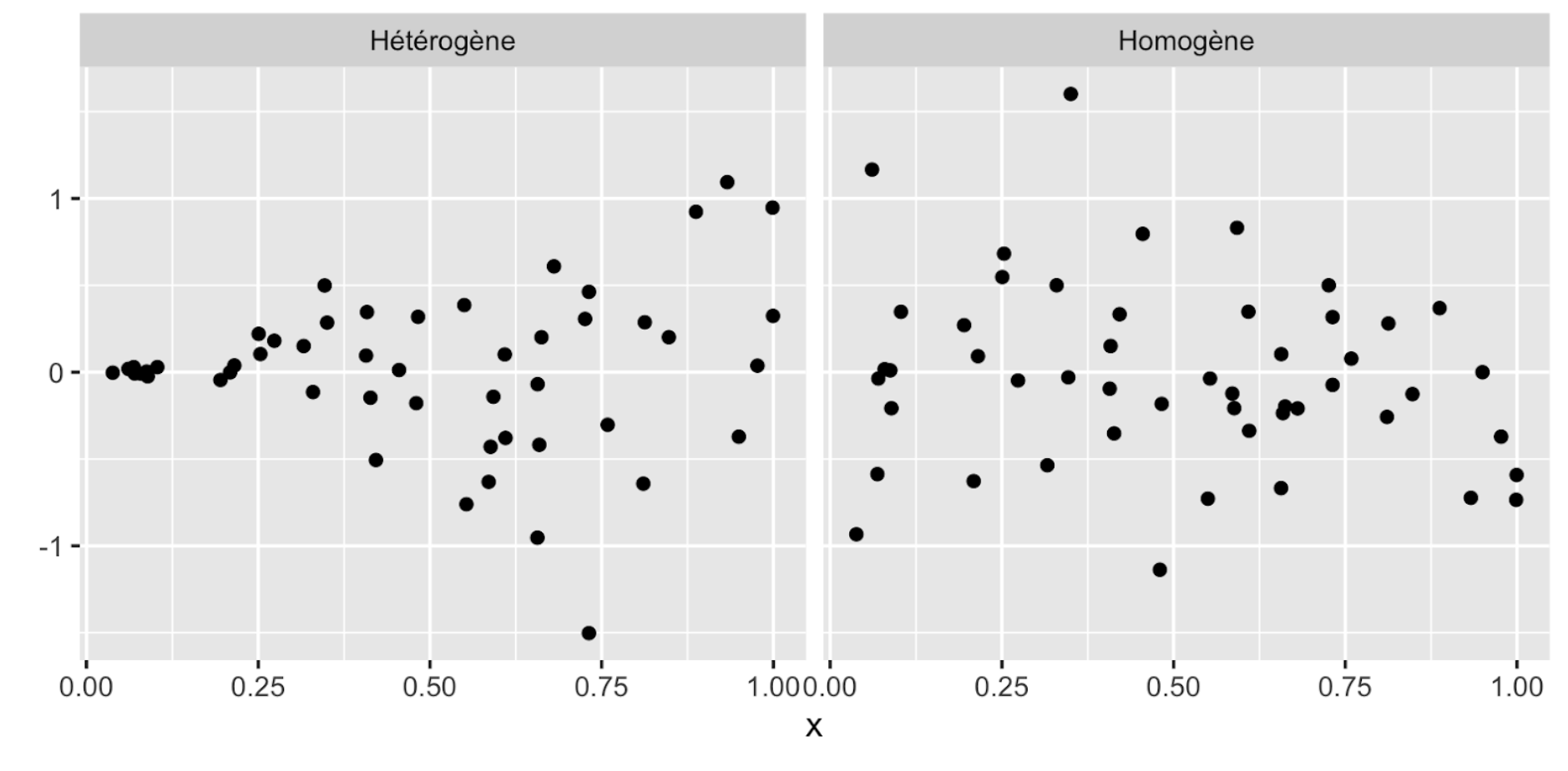
Ce qu’il faut surveiller c’est si le nuage de points a à peu près la même épaisseur sur toute sa largeur ou si il est clairement plus étroit à un bout qu’à un autre.
Nuages de point montrant à gauche la variance hétérogène, et à droite la variance homogène.
Ce qu’il est important de savoir est qu’il n’existe pas de test statistique pour déterminer si la variance est suffisamment homogène dans un gradient. Il faudra tranquillement, au fil de vos analyses, apprendre à déterminer à l’œil si la variance est suffisamment homogène pour être utilisée dans une régression. Les transformations normalisant et linéarisant les relations ont habituellement aussi pour effet d’homogénéiser la variance. Réglez donc d’abord ces deux problèmes avant de vous attaquer à l’homogénéité de la variance. Si jamais rien n’y fait, sachez qu’il existe aussi une façon de tenir compte de ce changement de variance dans un type de modèle nommé GLS (Generalized Least Squares).
Assomption 3 : Indépendance des observations.
Comme pour toutes les autres techniques vues jusqu’à présent, la régression linéaire assume aussi que les observations sont indépendantes les unes des autres. Ce qui veut dire que la régression linéaire n’est PAS appropriée si on évalue la croissance d’un seul individu au fil du temps, de la richesse en espèces d’arbres dans un parc au fil des années, etc. Il existe des modèles appropriés pour ce genre de question (par exemple les modèles autorégressifs), qui dépassent le cadre de ce livre.
Assomption 4. X est fixé par l’expérimentateur.
Cette quatrième assomption est celle dont on discute habituellement le moins. Lorsque la régression linéaire a été inventée, elle a été pensée pour des cas où la personne préparant l’expérience avait le contrôle sur les valeurs de la variable explicative (i.e. en X), p. ex. en contrôlant le pH dans une éprouvette, la quantité de nutriments dans un aquarium, etc. La régression linéaire assume que X est mesurée parfaitement, et que toute l’erreur dans nos mesures provient de la variable en Y.
Dans la réalité, en biologie-écologie, c’est rarement le cas. La variable en X est souvent un estimé, p. ex. si on met en X la densité d’arbres, le nombre de prédateurs, etc. On aura rarement recensé ces informations, on se basera sur un estimé.
Cette assomption est rarement discutée parce qu’elle n’affecte pas directement l’ampleur des résidus du modèle, ni la précision des prédictions qui résultent de notre modèle. Elle peut cependant affecter la valeur comme tel de la pente et de l’ordonnée à l’origine. Faisant changer une au dépens de l’autre.
Cette contrainte devient importante dans les cas où l’interprétation de la valeur de la pente a une importance écologique en soi. Par exemple, si nous étudions la relation entre la longueur et le poids de poissons (en transformant en général nos variables à l’échelle logarithmique), une pente plus petite que 3 nous informera que les poissons ont tendance à s’étirer en grandissant, alors qu’une pente plus grande que 3 nous informe que les poissons deviennent plus costauds en grandissant. Ce genre de relations, que l’on nomme relations allométriques, doit être traité avec un autre type de modèle, soit les régressions de type II, que nous ne verrons pas dans ce livre. Si vous n’êtes pas dans ce genre de cas pointus, vous n’avez pas à vous soucier de cette quatrième assomption.
18.3 Les calculs de la régression
La question qu’il convient de se poser à ce point est : comment déterminer où passera notre ligne de régression? Une façon bête d’y arriver serait d’essayer un paquet de valeurs de pentes et d’ordonnées à l’origine :
Pour chacune, on pourrait ensuite calculer les résidus et choisir la combinaison pente + ordonnée à l’origine qui présente les plus petits résidus. Si on lançait quelques milliers de pentes de ce genre, on arriverait toujours à une valeur très proche de la pente idéale… mais ce serait fichtrement long.
Heureusement, il existe une technique nommée la méthode des moindres carrés, qui d’un seul petit calcul nous fournit à tout coup la pente et l’ordonnée à l’origine idéale. Elle se nomme ainsi parce que son but est de minimiser la somme des carrés des résidus.
Les résidus sont mis au carré dans le calcul pour deux raisons : d’abord, cela permet d’arriver à une somme intéressante. Si on ne met pas les résidus au carré, comme on a toujours environ la moitié des observations au-dessus de la pente et l’autre moitié en dessous, notre somme des résidus sera toujours très proche de zéro, ce qui n’apporterait aucune information.
L’autre raison importante est que la somme des carrés des résidus (contrairement p. ex. à leur valeur absolue) possède aussi plusieurs propriétés mathématiques intéressantes, qui permettent entre autres de faire les calculs des paramètres à l’aide de petites opérations d’algèbre matriciel, que l’on peut même faire manuellement si désiré.
Des mathématiciens ont montré que la pente qui fournira la plus petite somme des résidus (au carré) sera toujours donnée par :
\[
b_1 = r\left(\frac{s_y}{s_x}\right)
\]
Autrement dit, la meilleure pente (\(b_1\) pour l’échantillon et \(β_1\) pour la population, i.e. la lettre grecque bêta) est toujours trouvée en multipliant la corrélation entre deux variables par le ratio de leurs écart-types.
Ensuite, on peut déterminer l’ordonnée à l’origine de notre régression, comme ceci :
\[
b_0 = \bar{y} - b_1\bar{x}
\]
Où y-barre et x-barre sont les moyennes de chacune de ces variables. Les paramètres de la régression sont nommés b0 et b1 parce vous verrez dans les chapitres sur la modélisation linéaire que l’on peut ajouter des variables supplémentaires à notre modèle, pour tenir compte d’autres facteurs, Ces derniers se nommeraient à ce moment b2, b3, etc. Notez que dans ces modèles, les équations pour déterminer les pentes et l’ordonnée à l’origine deviennent cependant beaucoup plus complexes que celles présentées ci-haut.
Si vous connaissez la notation classique d’une pente comme étant : \[
y = ax+b
\]
il est facile de faire le parallèle avec cette équation, car pour la régression, la pente est définie comme ceci : \[
y = b_0 + b_1x
\]
Remarquez que nous n’avons malheureusement qu’un seul mot “pente” pour désigner à la fois l’équation de la pente en entier (y=ax+b) et le paramètre de pente comme tel (a). Désolé pour la possible confusion…
18.4 Le coefficient de détermination (r2)
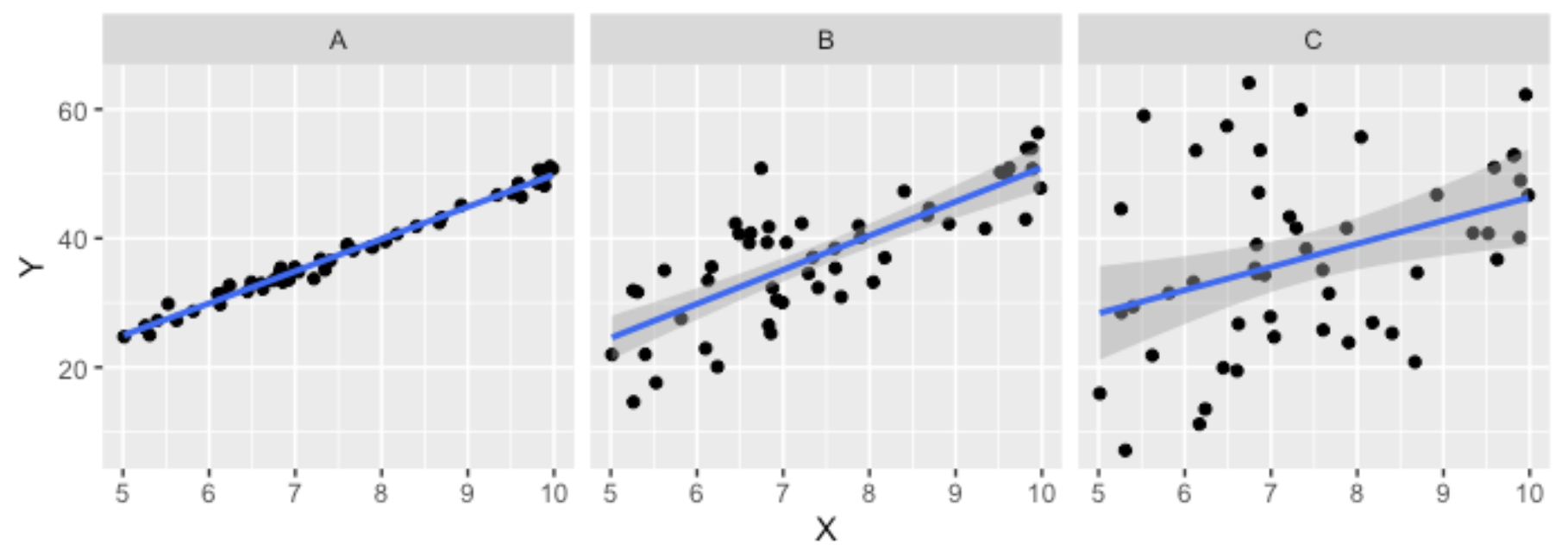
Une fois que nous avons déterminé quelle était la meilleure pente pour définir nos données, il peut être intéressant de savoir à quel point cette pente est une bonne représentation de la réalité. C’est ce rôle que joue le coefficient de détermination, qui est souvent abrégé comme r2 ou R2. Ce dernier varie entre 0 et 1, et nous indique à quel point la réalité varie autour de notre pente. Voici quelques exemples de r2 pour une pente de régression identique où b1=5 :
La régression A possède un r2 de 0,98, la B de 0,62 et la C de 0,14.
Il existe plusieurs façons de calculer le r2 d’une régression, qui donnent toutes exactement le même résultat. La première (et la plus intuitive dans un contexte de régression simple à deux variables) et de mettre la corrélation entre les deux variables au carré (d’où l’abréviation de r2… ).
Par contre, pour comprendre l’interprétation du r2, il peut être utile de connaître la deuxième façon de le calculer, soit en faisant 1 moins le rapport entre la variabilité résiduelle (i.e. le bruit dans notre modèle) et la variabilité totale de Y, soit :
\[
r^2 = 1 - \frac{SS_{résidus}}{SS_{totale}}
\]
Comme discuté au Chapitre 15, l’abréviation SS désigne ici la somme des carrés (Sum of Squares). La partie totale de cette somme des carrés est le numérateur de la variance, soit : \[
SS_{totale} = \sum_{i=1}^n(y_i-\bar{y})^2
\]
Alors que celle des résidus peut s’écrire comme ceci :
Où \(\hat{y}_1\) est la prédiction pour chacune de nos observation. Cette prédiction se calcule à l’aide de l’équation de la régression, dans laquelle on place une à une les valeurs de X (nous reviendrons dans la dernière section de ce chapitre sur le calcul des prédictions).
Une fois cette formule maîtrisée, il est intuitif de comprendre que le r2 représente la fraction de la variance de Y expliquée par notre modèle. Notre calcul passe par contre par un mini-détour, où on regarde 1 moins la fraction non expliquée (les résidus).
Notez bien la nuance entre les valeurs de r, qui peuvent aller entre -1 et 1 et informent du sens de la relation, alors que le r2 est limité entre 0 et 1. Il n’informe pas du sens de la relation, mais peut s’interpréter directement comme la fraction de la variance de Y explicable par X, ce que ne permet pas r.
18.5 Inspecter un modèle de régression
Même si les assomptions de la régression sont respectées, il pourrait arriver que votre modèle soit tout de même biaisé ou non représentatif. C’est pourquoi il importe d’inspecter votre modèle avant de l’interpréter.
Pour bien effectuer cette inspection, nous avons besoin de connaître trois concepts. Le premier concept est celui de levier. Une observation aurait un fort levier dans votre modèle de régression si sa valeur en X est très éloignée de la moyenne de X.
Le deuxième concept à comprendre est l’ampleur du résidu. Comme nous avons discuté plus haut, nos observations ne sont jamais directement sur la pente : plus l’observation en est éloignée, plus l’ampleur de son résidu est grande.
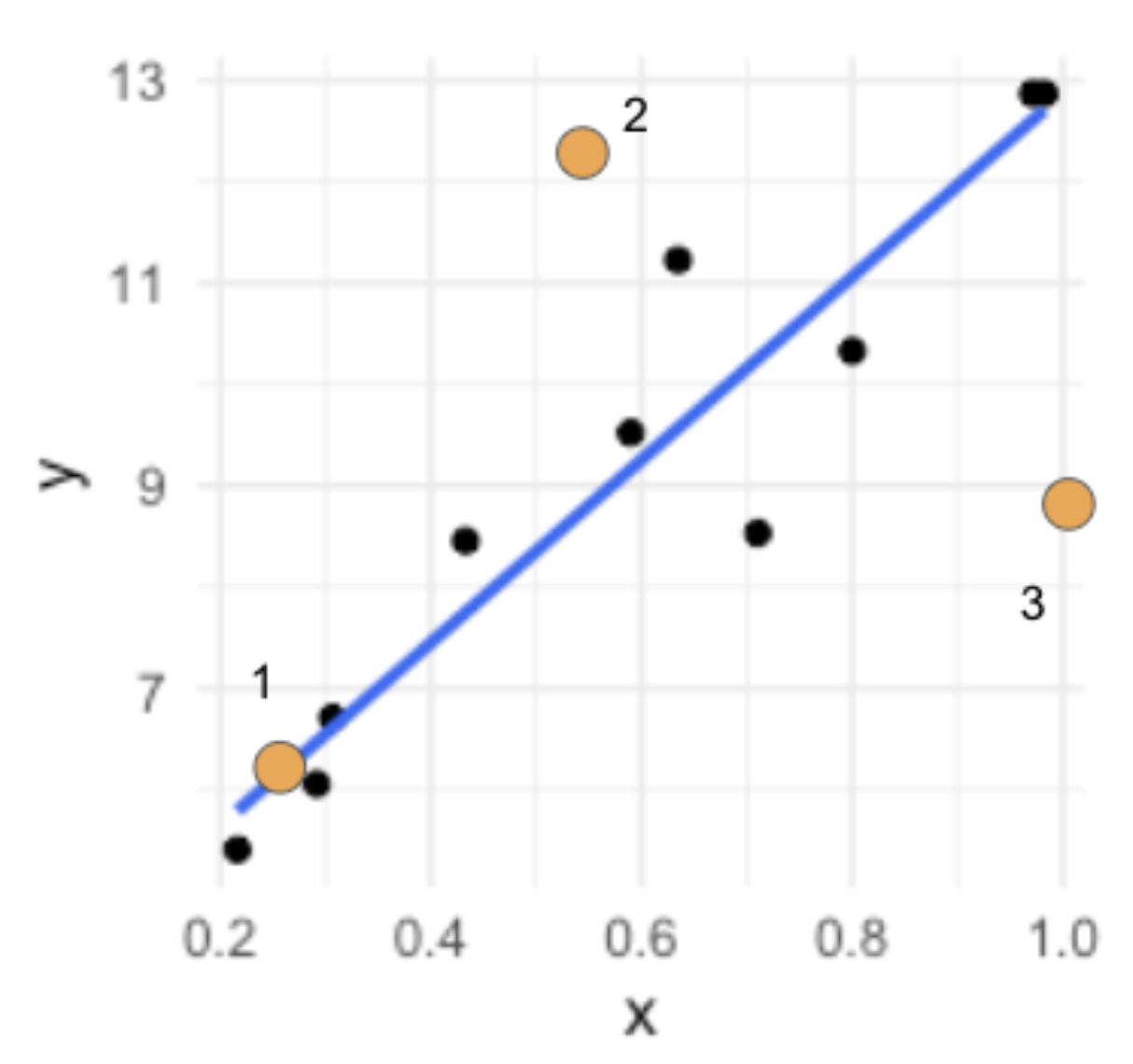
Qu’une observation possède un grand levier, comme tel n’est pas un problème. Qu’une observation possède un grand résidu non plus n’est pas nécessairement un problème. Par contre, si une observation possède à la fois un grand levier ET un grand résidu, alors ça peut devenir un problème, on parle d’une observation avec de l’influence. C’est-à-dire qu’à elle seule, elle pourrait faire changer grandement la pente de notre modèle et changer nos conclusions biologiques.
Dans l’illustration précédente, les points 1 et 3 possèdent un fort levier. Les points 2 et 3 possèdent un fort résidu, mais seul le point 3 possède une grande influence, parce qu’il a à la fois un fort levier et un fort résidu.
Pour nous aider à évaluer l’influence d’une observation dans un modèle de régression, il existe une mesure nommée la distance de Cook. Cette distance est un chiffre qui intègre à la fois le levier et le résidu. Elle se calcule pour chacune de nos observations. Le calcul est plutôt complexe et implique de calculer la différence de pente lorsque l’on enlève cette observation du modèle par rapport au modèle complet. Plus la valeur est élevée, plus cette observation est influente. On dit qu’en général si cette valeur est >1 pour une ou plusieurs de nos observations, il faut commencer à s’interroger sur notre modèle.
Et, on fait quoi si ça nous arrive? Comme pour la plupart des problèmes en statistiques, la première chose à faire est d’aller vérifier nos données avec notre carnet de notes. Il aurait pu arriver qu’une donnée soit mal saisie, etc. Ensuite, si la donnée était bonne, l’étape suivante est de reconnaître le problème et de le décrire comme tel dans nos résultats : que telle ou telle observation avait une distance de Cook > 1.
Ensuite, ce que je vous recommande est d’ajuster deux modèles de régression différents, un avec et l’autre sans cette observation problématique. Ainsi, vous pourrez informer votre lecteur de la force de l’influence de cette observation.
Si la pente est sensiblement la même, informez-en votre lecteur. Si ça change drastiquement les résultats, informez-en aussi votre lecteur et discutez des particularités de cette observation.
Est-ce possible que ce soit un individu égaré provenant d’une autre population, d’un échappé de captivité? Voyez cette observation d’un œil curieux, c’est souvent de cette façon que l’on découvre de nouvelles choses en biologie, en se posant des questions sur les exceptions.
18.6 La régression comme test statistique
Jusqu’à présent dans ce chapitre, je vous ai enseigné la régression linéaire surtout comme une technique de modélisation, i.e. une façon d’estimer des paramètres pour représenter la réalité. Elle peut cependant être vue aussi comme un test statistique, c’est ce que nous verrons dans cette section.
Comme pour toutes les techniques statistiques que nous avons vues jusqu’à présent, il pourrait arriver que l’on trouve par hasard dans nos échantillons une pente, alors que dans la population, il n’y en a pas. C’est pourquoi il existe un test pour savoir si la pente (et aussi l’ordonnée à l’origine) sont significativement différents de zéro (i.e. de l’absence de pente).
Il existe deux tests différents pour déterminer si une pente est significative, soit un basé sur une distribution de T et un basé sur distribution de F. Comme ce chapitre commence à s’étirer, nous ne verrons que celle basée sur la distribution de T, mais sachez que l’autre existe aussi.
Notre hypothèse nulle pour la pente sera qu’elle est égale à zéro, et notre hypothèse alternative qu’elle est différente de zéro.
La chose à savoir est qu’à l’aide d’un calcul un peu complexe, qui dépasse ce qu’il est raisonnable de faire manuellement dans ce cours, on peut obtenir à l’aide de la méthode des moindres carrés l’erreur-type associée à un paramètre. La statistique de test sera ensuite calculée comme ceci pour la pente :
\[
t = \frac{b_1-\theta}{S_{b_1}}
\]
Autrement dit, comme pour le test de T à un échantillon (voir Chapitre 12), la statistique de t se calcule comme le ratio entre notre mesure d’intérêt (ici la pente) et son erreur-type. La valeur de θ (theta) sera zéro si vous voulez savoir si votre pente est différente de zéro, mais ce pourrait aussi être un autre chiffre si vous avez une bonne théorie à tester avec cela.
L’équation s’écrira de la même manière, mais avec b0 si on veut plutôt tester l’ordonnée à l’origine.
Comme pour un test de t à un échantillon, on va ensuite trouver la probabilité de trouver une telle valeur de t avec n-2 degrés de liberté. Remarquez que l’on fait ici n-2 plutôt que n-1 puisque la régression linéaire estime deux paramètres, soit la pente et l’ordonnée à l’origine.
18.7 Labo : la régression linéaire
Mettons maintenant ensemble tous ces morceaux pour appliquer une régression linéaire à un jeu de données réel.
Sachant qu’il est important de bien pouvoir manoeuvrer dans l’eau pour s’alimenter, notre question sera la suivante : est-ce que le poids des manchots de Palmer augmente avec la taille de leurs ailes.
Remarquez bien qu’on a un sens pour la relation de cause à effet : la taille des ailes causera le poids.
Étape 1 : Définir les hypothèses
Nous nous intéresserons dans notre exemple uniquement à la question de la pente. Nos hypothèses statistiques seront donc les suivantes :
Autrement dit, notre hypothèse nulle est qu’il n’y a pas de pente qui relie les deux variables, et l’hypothèse alternative est qu’il en existe une.
Étape 2 : Explorer visuellement les données
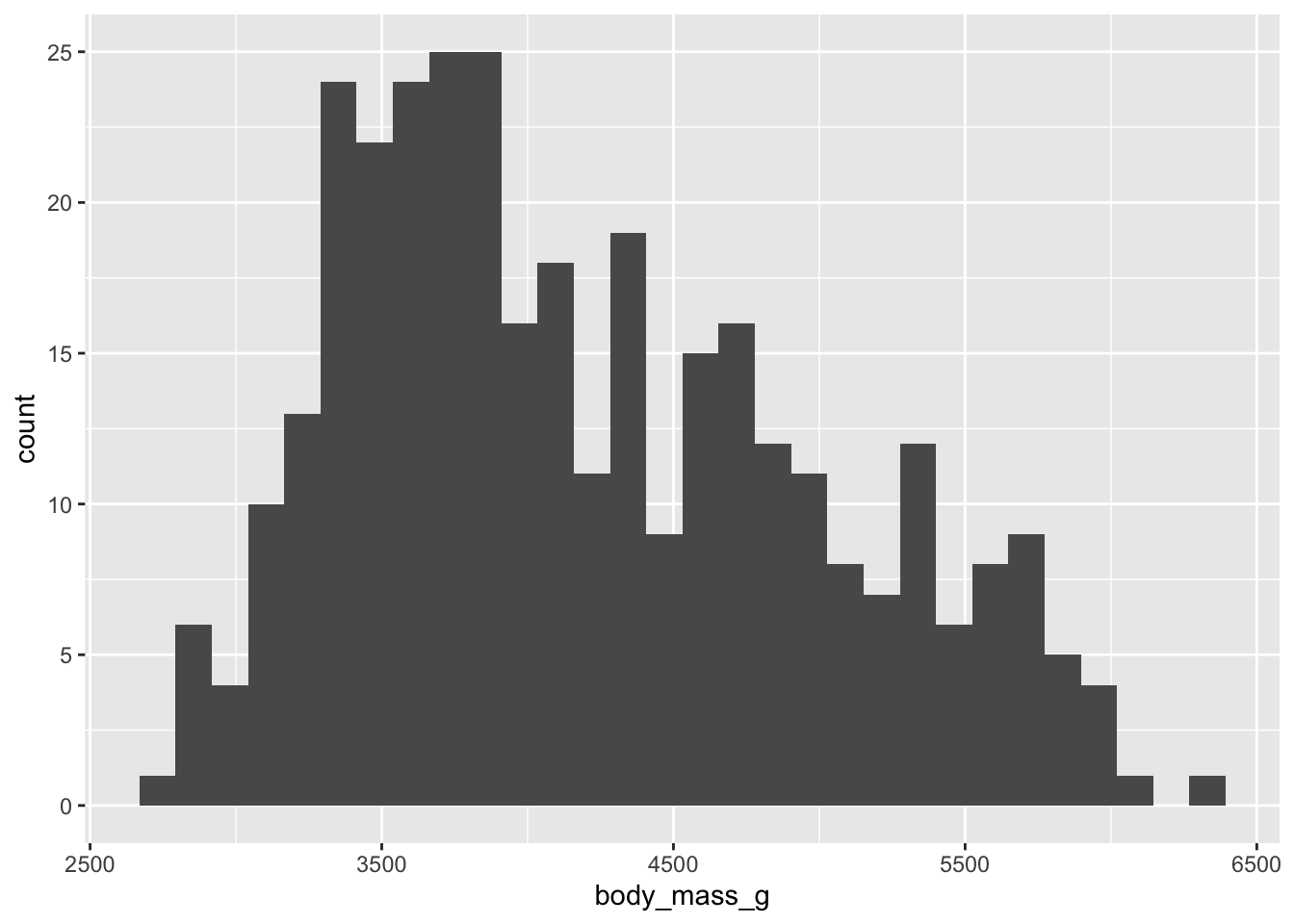
Connaissant les quatre assomptions de la régression linéaire, nous savons que nous ne pouvons pas les tester directement à cette étape. Cependant, il est toujours utile d’observer nos données dans un graphique pour se donner une idée de ce qui nous attend pour la suite. Nous préparerons aussi au préalable une version simplifiée de notre tableau de données de manchots, où nous avons enlevé les lignes contenant des valeurs manquantes pour les colonnes de cette analyse.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.2 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(palmerpenguins)
Attaching package: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
Remarquez d’abord que nous avons mis en X la variable explicative, celle qui causerait (selon notre hypothèse) le changement dans l’autre variable.
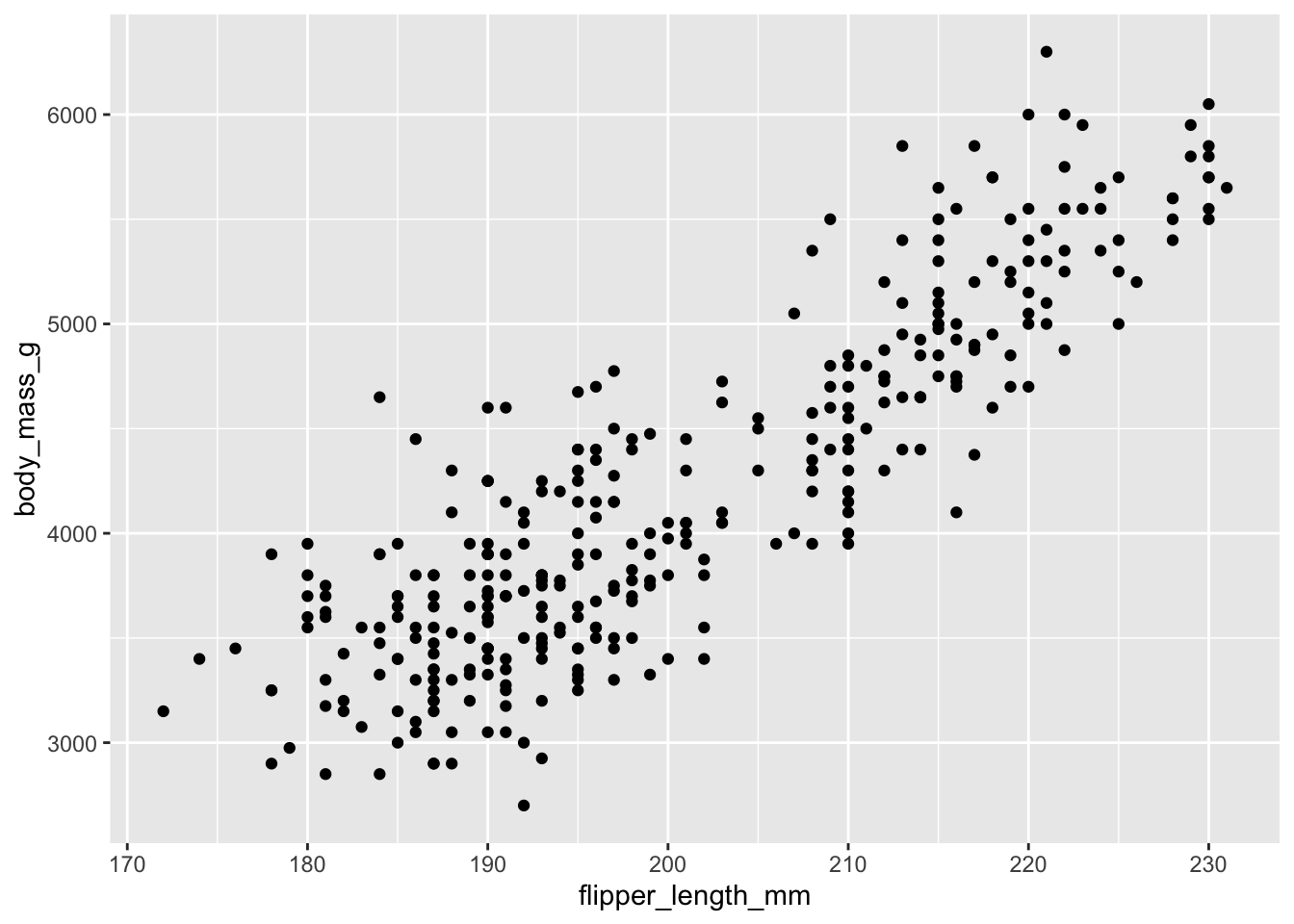
On constate (comme nous l’avions fait au Chapitre 17) que cette relation sera clairement linéaire et que la variance, à l’oeil, risque bien d’être homogène.
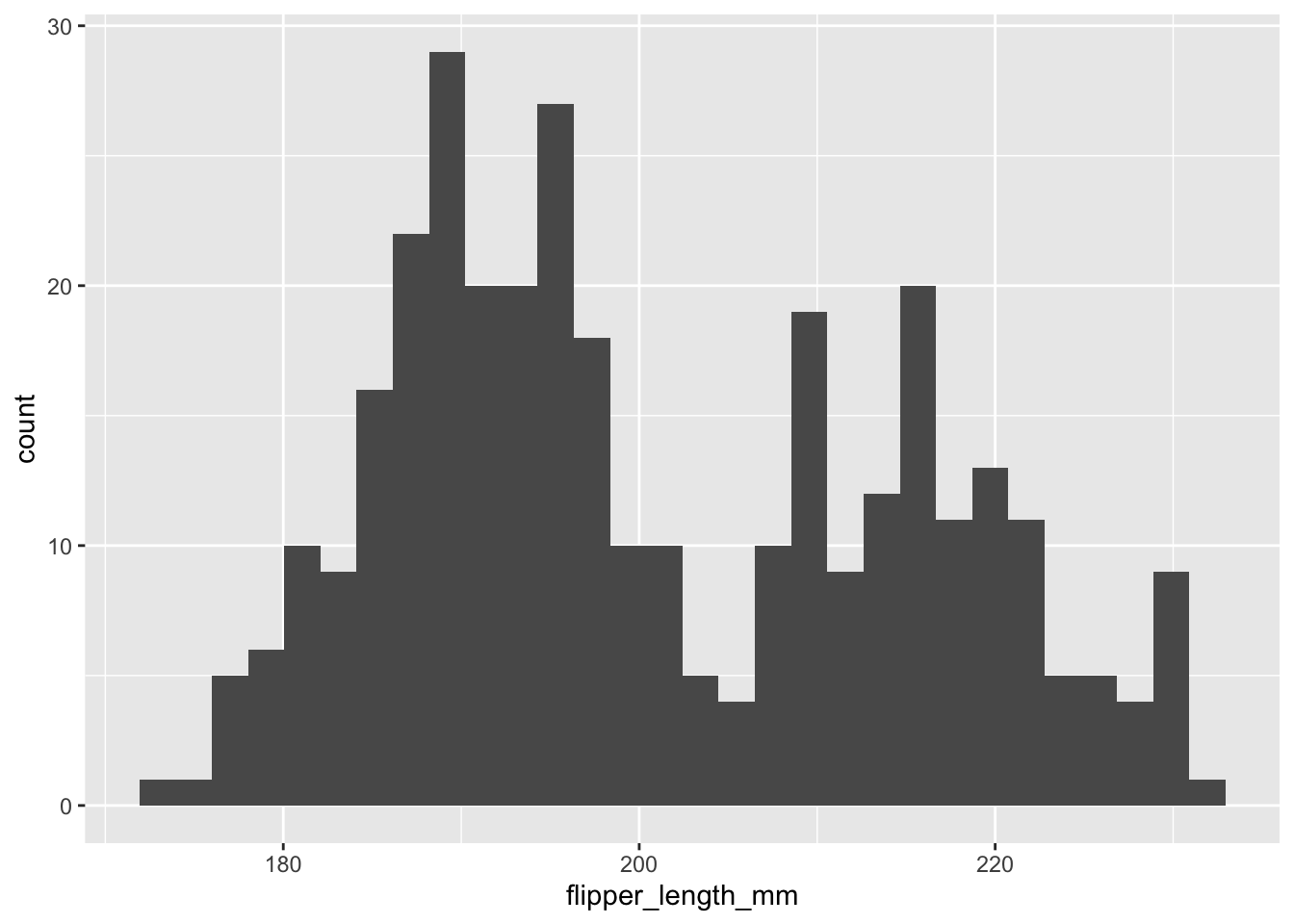
Ensuite, même si ce n’est pas un validation formelle de l’assomption de normalité des résidus, il est important de regarder la distribution de chacune des variables :
`stat_bin()` using `bins = 30`. Pick better value with
`binwidth`.
On constate que la distribution de la longueur des ailes est peut-être bimodale. Il faudrait garder un oeil attentif sur la distribution des résidus (qui sont la vérification formelle)
Étapes 3 et 4 : Calculer la statistique de test (ici, calculer tout le modèle de régression)
Dans R, la régression linéaire utilise la même notation de formule que celle que nous avons vu pour l’ANOVA, avec le symbole ~ (tilde) qui sépare la partie expliquée de la partie explicative. Donc, pour que ce soit bien clair, la partie à gauche de la formule est la variable expliquée (le Y de nos graphiques) et la partie à droite est la variable explicative (le X dans nos graphiques).
Notre modèle s’ajusterait donc comme ceci :
m <-lm(body_mass_g ~ flipper_length_mm, data = labo_regression)
Autrement dit, on calcule une régression linéaire (lm pour Linear Model) de la taille du corps en fonction de la longueur des ailes, et on conserve le résultat dans l’objet nommé m.
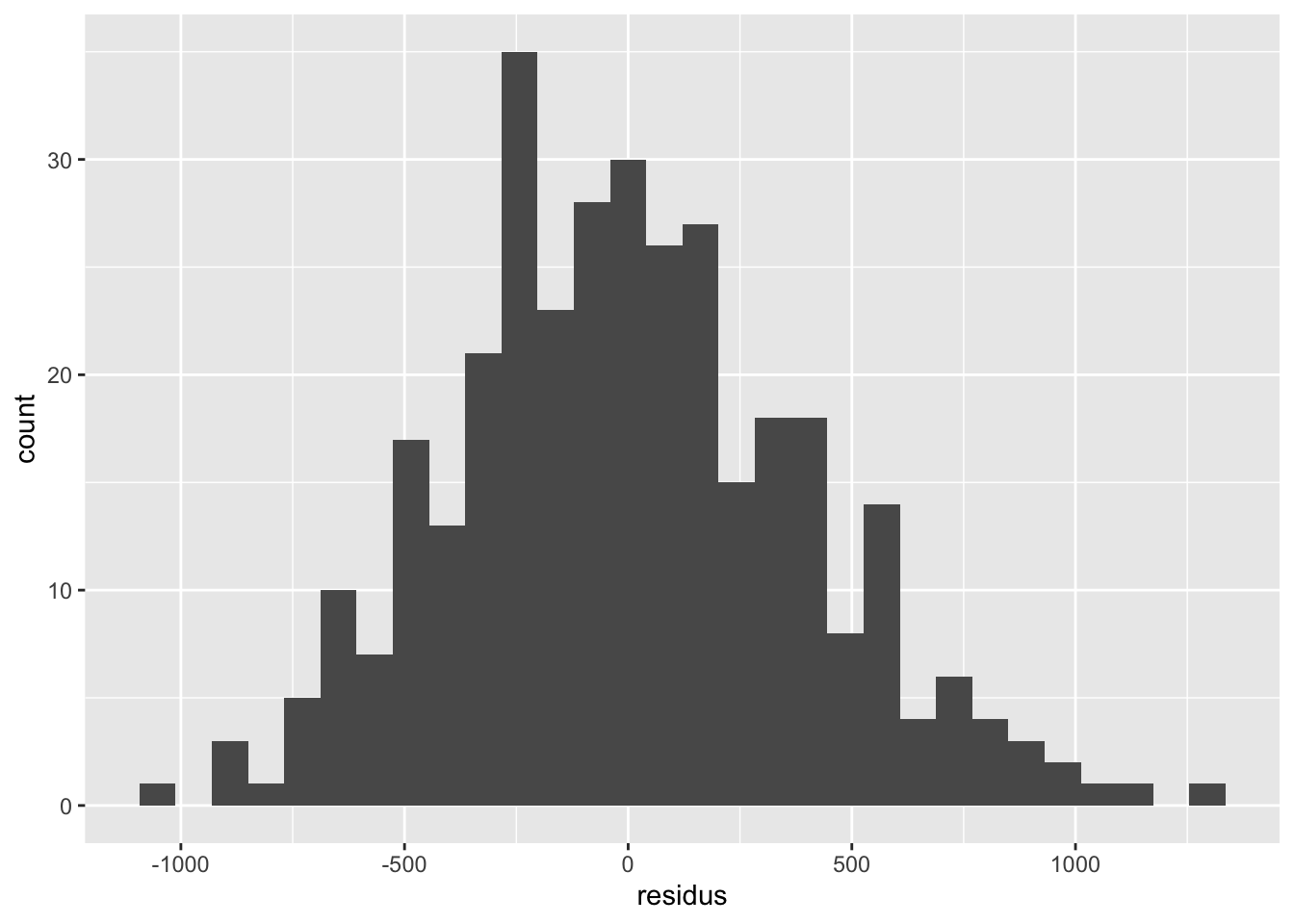
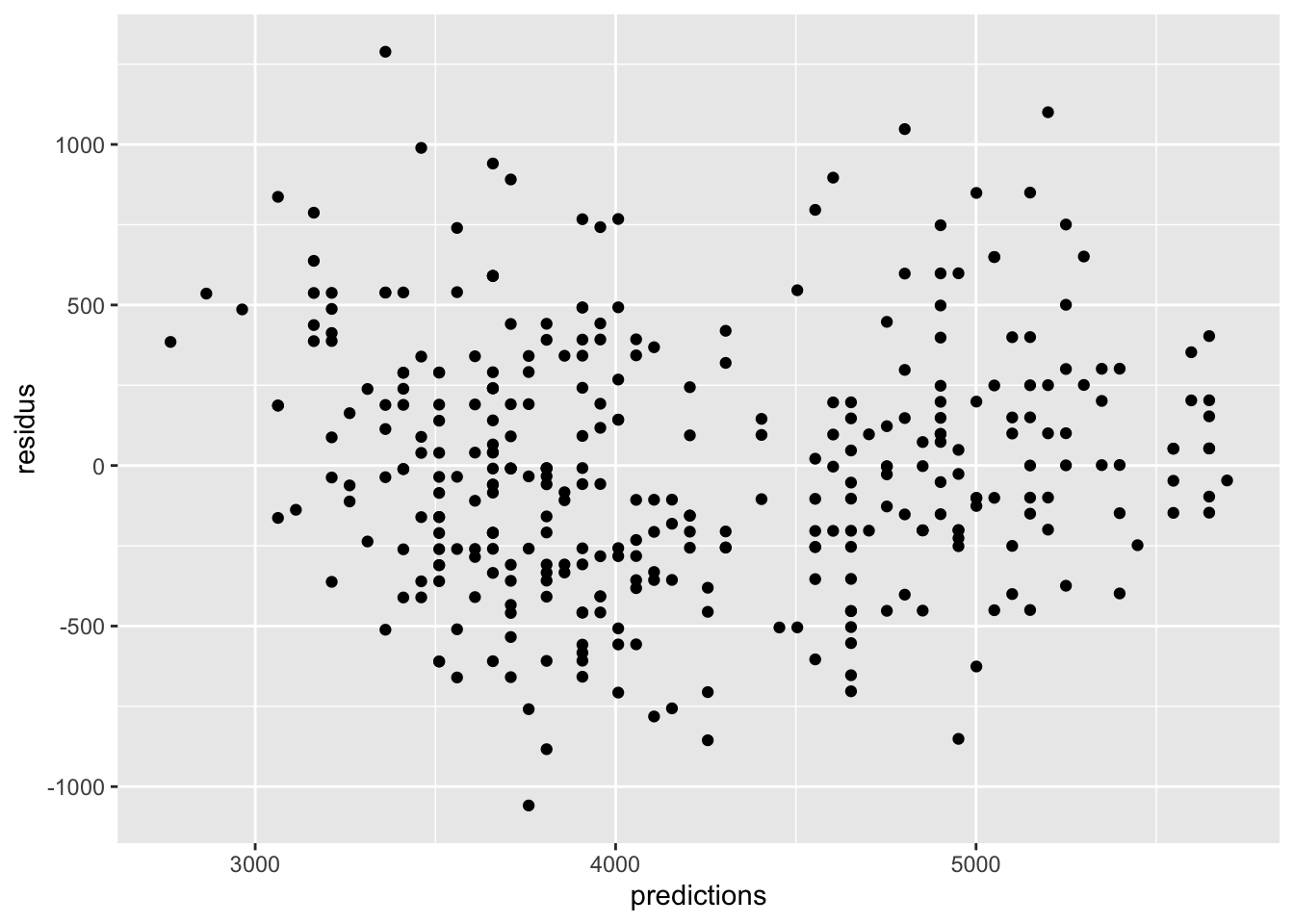
Avant de se lancer dans les résultats, il faut d’abord s’assurer que notre modèle est approprié et non-biaisé. Il faut donc vérifier nos assomptions (normalité des résidus et homogénéité de la variance) et la qualité du modèle (i.e. la présence d’observations influentes). Pour se faire, le plus simple est d’ajouter une colonne à notre tableau de données contenant le résidu et la prédiction de chacune des observations, comme ceci :
En général, les résidus sont relativement homogènes.
Enfin, il faut aussi vérifier si nous avons des observations influentes qui pourraient changer fortement notre modèle. Pour se faire, il existe dans R la fonction cooks.distance qui effectue pour nous le calcul de la distance de Cook pour chacune des observations. On peut ajouter ces valeurs à notre tableau de données aussi, comme cela :
Et ensuite, appliquer un filtre pour voir si des observations ont une valeur de Cook plus grande que 1 :
labo_regression |>filter(D >1)
# A tibble: 0 × 11
# ℹ 11 variables: species <fct>, island <fct>,
# bill_length_mm <dbl>, bill_depth_mm <dbl>,
# flipper_length_mm <int>, body_mass_g <int>,
# sex <fct>, year <int>, residus <dbl>,
# predictions <dbl>, D <dbl>
Dans notre cas, tout va bien, aucune observation n’a d’influence importante. On peut donc se lancer dans l’interprétation des résultats.
Pour se faire, appelons la fonction summary sur notre objet m pour avoir un aperçu des calculs :
summary(m)
Call:
lm(formula = body_mass_g ~ flipper_length_mm, data = labo_regression)
Residuals:
Min 1Q Median 3Q Max
-1058.80 -259.27 -26.88 247.33 1288.69
Coefficients:
Estimate Std. Error t value
(Intercept) -5780.831 305.815 -18.90
flipper_length_mm 49.686 1.518 32.72
Pr(>|t|)
(Intercept) <2e-16 ***
flipper_length_mm <2e-16 ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 394.3 on 340 degrees of freedom
Multiple R-squared: 0.759, Adjusted R-squared: 0.7583
F-statistic: 1071 on 1 and 340 DF, p-value: < 2.2e-16
Il s’agit probablement de votre sortie de R la plus longue jusqu’à maintenant, mais en y allant morceau par morceau, vous verrez que c’est relativement simple au final. D’abord, la première ligne (call) nous rappelle comment la fonction a été appelée, avec quelles variables, quel tableau de données, etc.
Ensuite, la section Residuals nous informe de quelques statistiques concernant les résidus. Comme nous les avons déjà explorés visuellement, on peut ignorer cette partie.
Ensuite, la section Coefficients nous montre les paramètres estimés par la modèle. La ligne (Intercept) correspond à l’ordonnée à l’origine (b0) et la ligne flipper_length_mm correspond à la pente pour cette variable (b1). Pour chacun de ces paramètres, R nous fournit quatre nombres, qui sont dans l’ordre : l’estimé du paramètre (Estimate), son erreur-type (Std. Error), la valeur de t (t value) et la valeur de p (Pr).
La seule autre information que nous utiliserons de ces sorties est celle nommée Multiple R-squared, qui nous fournit la valeur de r2 de notre modèle, ici 0,76. À elle seule, la taille des ailes explique 76% de la variabilité dans le poids des manchots.
La colonne Estimate nous fournit donc les estimés des paramètres, soit l’ordonnée à l’origine de notre régression (-5780,8) et sa pente (49,7). L’équation de notre régression est donc :
Pour chaque mm d’aile de plus, un manchot pèse 49,7 g supplémentaires.
Remarquez la difficulté d’interpréter l’ordonnée à l’origine. Elle nous dit qu’un manchot avec des ailes de 0 mm pèserait -5780 g.
Étape 5 : Rejeter ou non l’hypothèse nulle.
Puisque la valeur de p associée à notre paramètre de pente est très faible (i.e. rare), soit < 2 x 10-16, on peut rejeter l’hypothèse nulle de l’absence de pente, puisque ce serait très rare d’avoir une pente aussi grande dans notre échantillon si les populations n’étaient pas reliées. Vous pouvez valider votre interprétation de la valeur de p grâce aux petites étoiles à côté de la valeur. Lorsqu’il y a une ou plusieurs étoiles, R considère cette valeur de p comme significative au seuil de 0,05.
Étape 6 : Citer la magnitude de l’effet et son intervalle de confiance
La magnitude de l’effet ici est l’ampleur de la pente, donc de 49,7. Vous pouvez évaluer “au pif” son intervalle de confiance à 95 % en faisant 49,7 +/- 2 * 1,51 (l’erreur-type de ce paramètre). L’intervalle de confiance se situerait donc quelque part entre 46,65 et 52,72. Vous pouvez aussi demander à R de calculer le vrai intervalle de confiance pour vous avec la fonction confint (CONFidence INterval), comme ceci :
Nous pourrions donc écrire notre résultat comme ceci : «La longueur des ailes des manchots de Palmer expliquait de façon significative leurs poids (b1 = 49,69, t340 = 32,72, p < 2 x 1016). L’intervalle de confiance à 95 % de cette pente allait de 46,70 à 52,67. La longueur des ailes expliquait ainsi une partie importante de la variance du poids (r2 = 0,76)»
Enfin, il peut être intéressant pour un calcul comme la régression linéaire d’illustrer la pente à travers nos données. Pour se faire, on peut tracer à nouveau un nuage de point, et ajouter une couche de pente (geom_abline) et lui fournissant les paramètres calculés par notre modèle de régression :
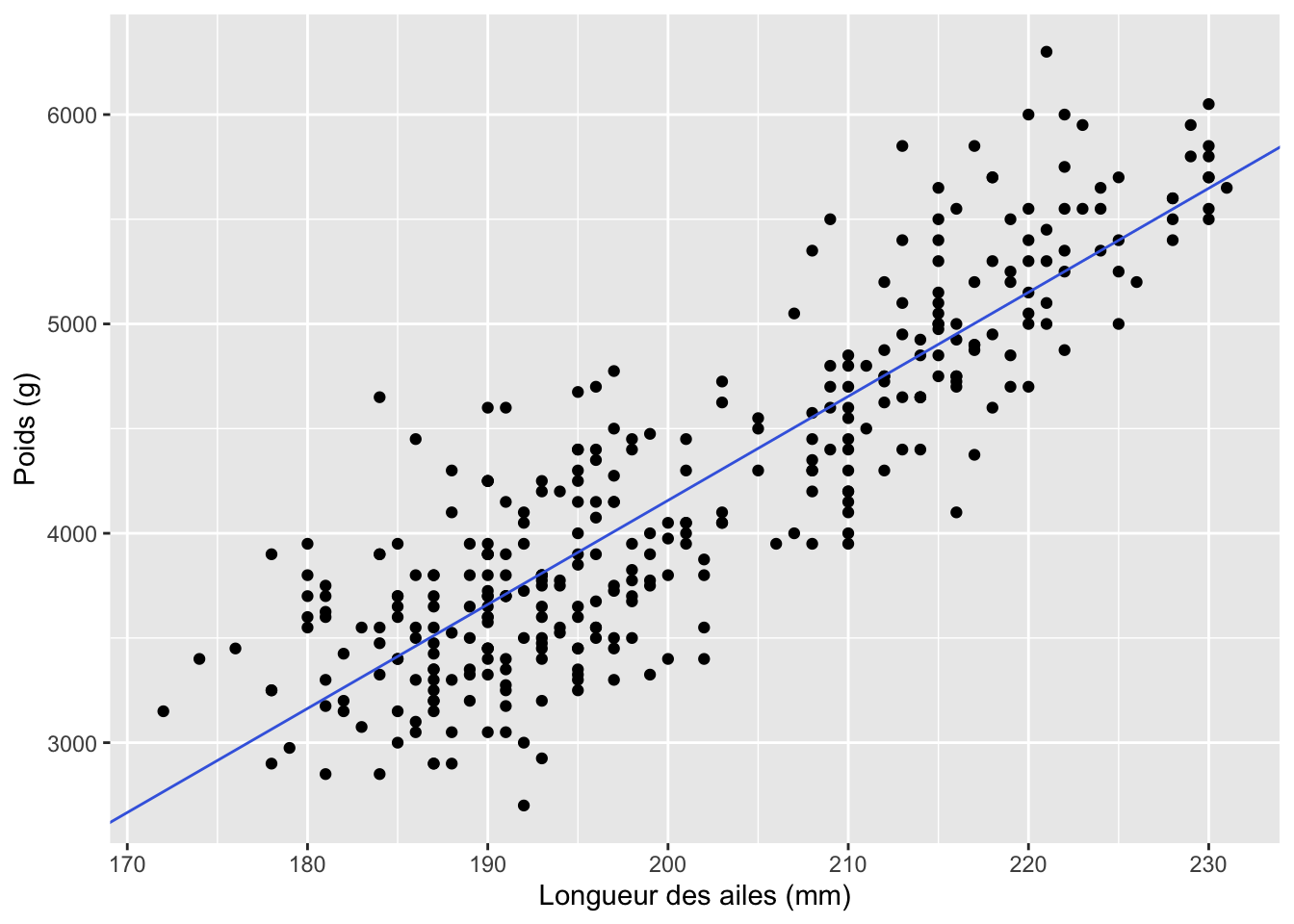
labo_regression |>ggplot(aes(flipper_length_mm, body_mass_g)) +geom_point() +geom_abline(slope =49.69, intercept =-5780.83, color ="royalblue") +labs(x ="Longueur des ailes (mm)",y ="Poids (g)" )
Remarquez que, comme je l’ai fait ici, si ce graphique est destiné à la publication, il importe de bien nommer les axes et de fournir leurs unités.
18.8 Les prédictions de la régression
À l’aide de l’équation de la régression, il est facile de déterminer la valeur que notre régression prédirait pour une valeur de X donnée. La notation formelle de ces prédictions est celle-ci :
\[
\hat{y_i} = b_0 + b_1x_i
\]
Verbalement, on pourrait décrire cette équation comme : pour prédire une valeur de Y, il faut multiplier la pente par la valeur de X, puis ajouter l’ordonnée à l’origine. Si on choisit une série de valeurs de X et que l’on prédit leur valeurs pour ensuite les relier, on retrouvera invariablement la pente.
Si on revient à notre exemple en R, si on veut savoir quel serait le poids d’un manchot ayant des ailes de 200 mm, on ferait donc le calcul suivant :
\[
Poids\ = -5780,83 + 49,69 \times 200 mm = 4157,17 g.
\]
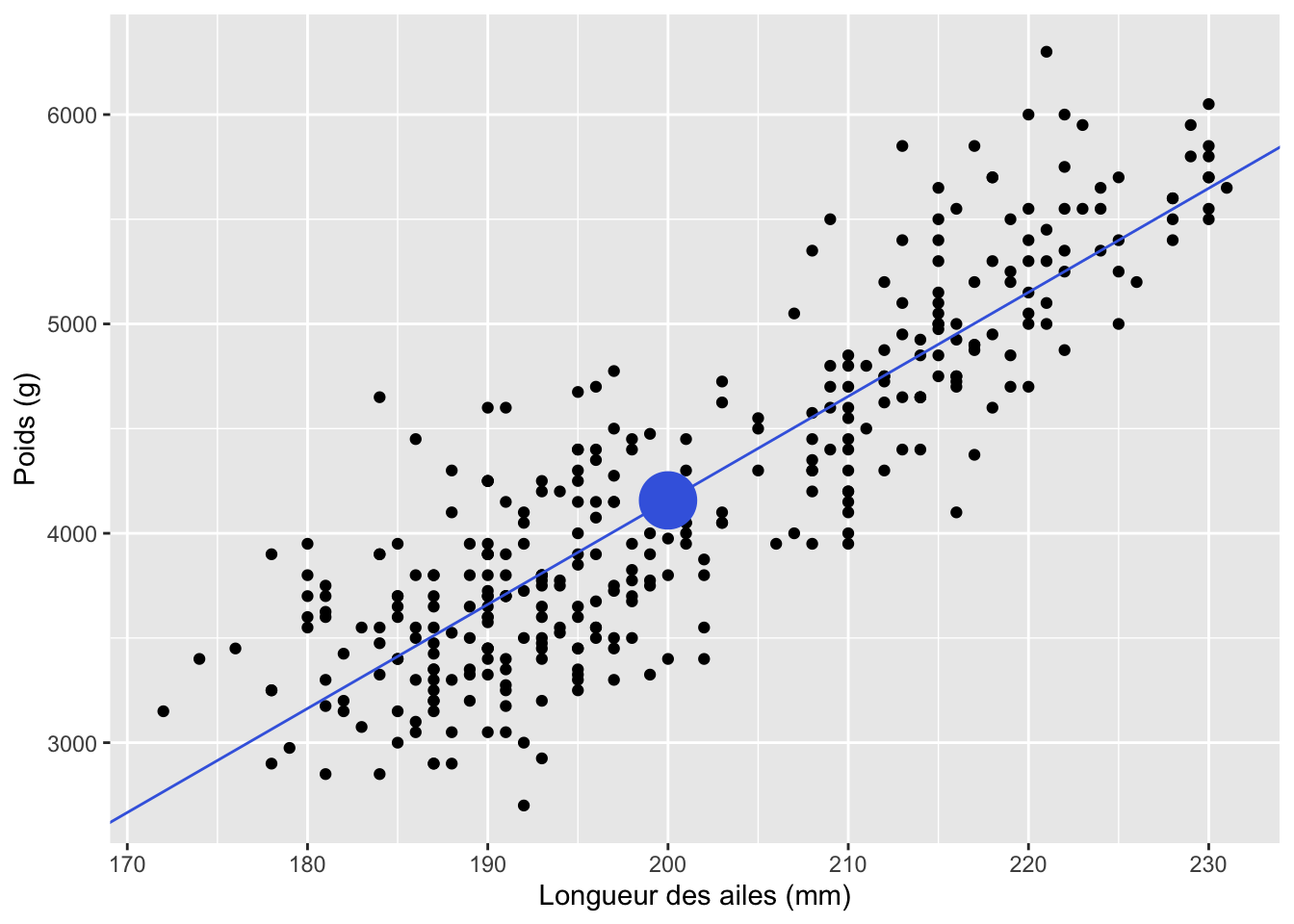
Après avoir fait un calcul de ce genre, c’est toujours une bonne idée d’aller se valider avec le graphique pour voir si notre calcul de prédiction est correct. Dans notre cas, le point que l’on prédit se retrouverait ici :
Dans tous les cas, notre prédiction devrait se retrouver directement sur la pente. Si ce n’est pas le cas, on a une erreur soit dans le traçage de la pente, soit dans le calcul de la prédiction.
Ça, c’était la partie facile! La partie plus compliquée maintenant est de savoir, quelle est notre confiance dans cette prédiction?
Remarquez bien d’abord dans le graphique précédent que près de notre point de prédiction pour 200 mm, il existe des manchots ayant des poids allant environ de 3400 g à 4700 g. On pourrait donc créer, à partir de cette information un premier intervalle, que l’on nomme l’intervalle de prédiction. Ce dernier nous informe de ce que l’on pourrait trouver vraiment sur le terrain. Si on parle de l’intervalle de prédiction à 95 %, il nous dit que 95 % des observations devraient se trouver entre ces deux bornes. Pour notre exemple, cet intervalle à 95 % irait de 3379 g à 4932 g (je vous épargne ici le calcul, attardez vous au principe et à l’interprétation).
Nous pourrions par contre avancer une autre information à partir de cette valeur de 4157 g. Nous pourrions nous demander à quel point la pente, à cet endroit précis, est proche de la vraie valeur de pente de la population. Vous vous rappelez que plus haut, nous avions vu que la méthode des moindres carrés nous fournissait une erreur-type sur la pente et une erreur-type sur l’ordonnée à l’origine. On serait donc en droit de se demander quelle est notre incertitude sur le 4157 g, compte tenu de ces deux erreurs combinées. On parlerait alors d’intervalle de confiance de la moyenne. Cet intervalle dans notre cas se trouve entre 4114,25 g et 4198,31 g.
Remarquez que ce deuxième intervalle est beaucoup plus étroit que le premier, car il ne représente pas la même réalité que le précédent. L’intervalle de prédiction nous informe de la fourchette de valeurs possible de trouver sur le terrain. L’intervalle de confiance de la moyenne lui nous informe sur la certitude de notre pente à cet endroit. L’intervalle de confiance de la moyenne peut être réduit si notre taille d’échantillon augmente, mais l’intervalle de prédiction, lui, devrait demeurer sensiblement le même.
Il est très important, lorsque nous faisons des prédictions à l’aide de notre modèle de régression, de se limiter à l’intervalle de valeurs de X que nous avons utilisé pour ajuster notre modèle de régression. Nous ne savons pas comment se comporte notre phénomène à l’extérieur de ces bornes. Vous constaterez au fil de votre cheminement en biologie-écologique que peu de phénomènes sont entièrement linéaires. Ils ne le sont souvent que sur une partie du spectre de valeurs, et montrent des accélérations et des ralentissements nonlinéaires dans les extrémités.
18.9 Labo : Prédictions de la régression linéaire
Pour prédire de nouvelles valeurs à partir d’un modèle de régression, il existe dans R la fonction predict. Cette dernière s’attend à recevoir au moins deux arguments, soit le modèle de régression déjà ajusté, et un tableau de données sur lequel effectuer les prédictions. Si on continue le laboratoire précédent, on pourrait par exemple faire notre prédiction pour des ailes de 200 mm comme ceci :
predict(m, data.frame(flipper_length_mm=200))
1
4156.282
La clé étant que pour que la prédiction fonctionne bien, notre variable en X doit être écrite exactement comme dans notre tableau de données original.
Remarquez que cette valeur est légèrement diffèrente de celle calculée ci-haut, puisque nous avions arrondi les paramètres, alors que le calcul de R conserve toutes les décimales possibles.
Si l’on veut connaître l’intervalle de prédiction de cette valeur, il faut ajouter un argument supplémentaire pour en informer R, comme ceci :
La valeur fit nous informe de la valeur de notre prédiction, alors que lwr (LoWeR) et upr (UPpeR) nous informent des bornes inférieures et supérieures de notre intervalle de prédiction. Par défaut R nous fournit un intervalle à 95 %, mais on peut changer cette valeur à l’aide d’un argument supplémentaire. L’intervalle de prédiction à 99 % s’obtiendrait comme ceci :
Enfin, si on veut obtenir l’intervalle de confiance de la moyenne plutôt que l’intervalle de prédiction, il faut changer l’argument interval pour ceci :
18.10 Labo optionnel : tracer l’intervalle de confiance d’un modèle de régression.
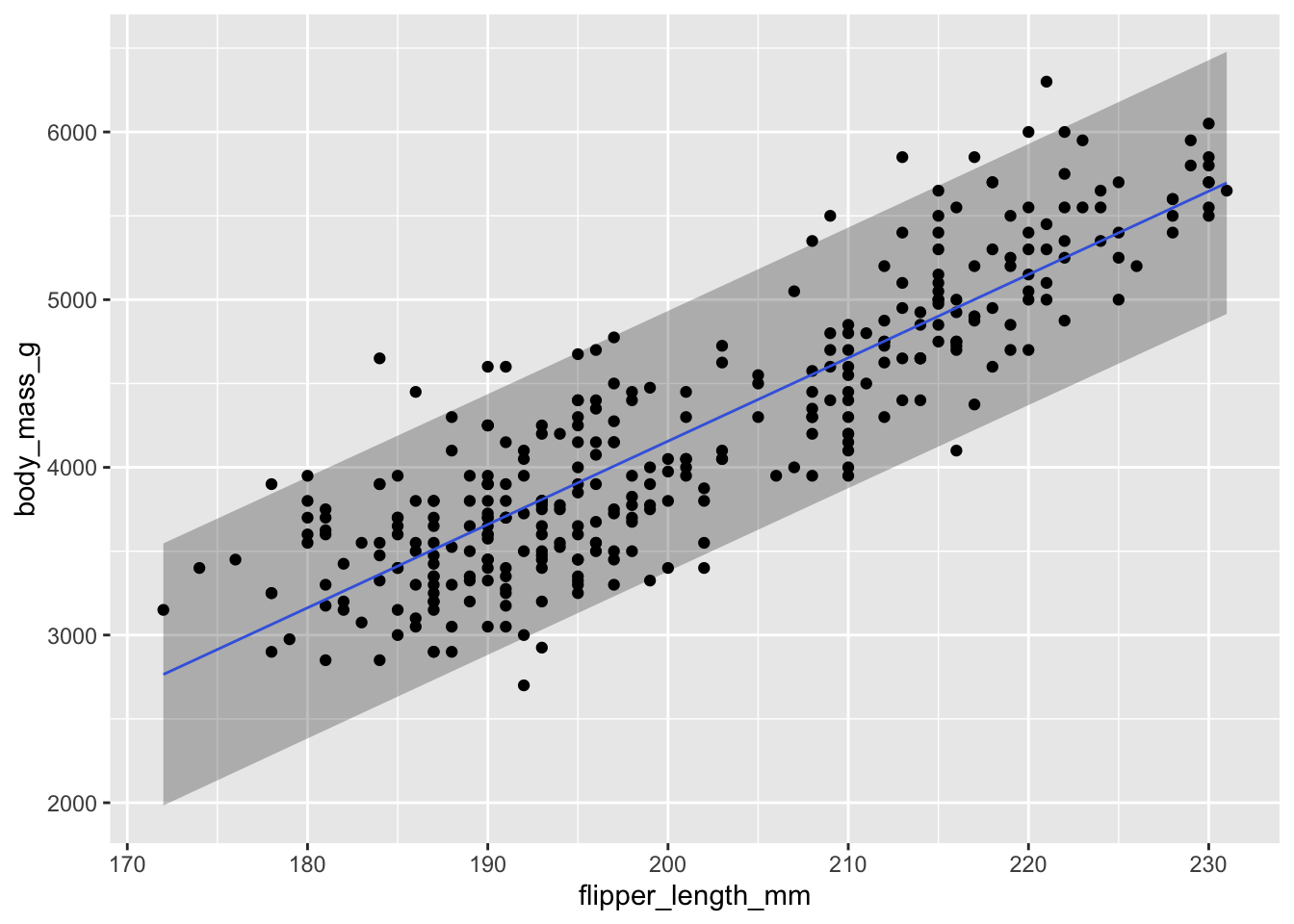
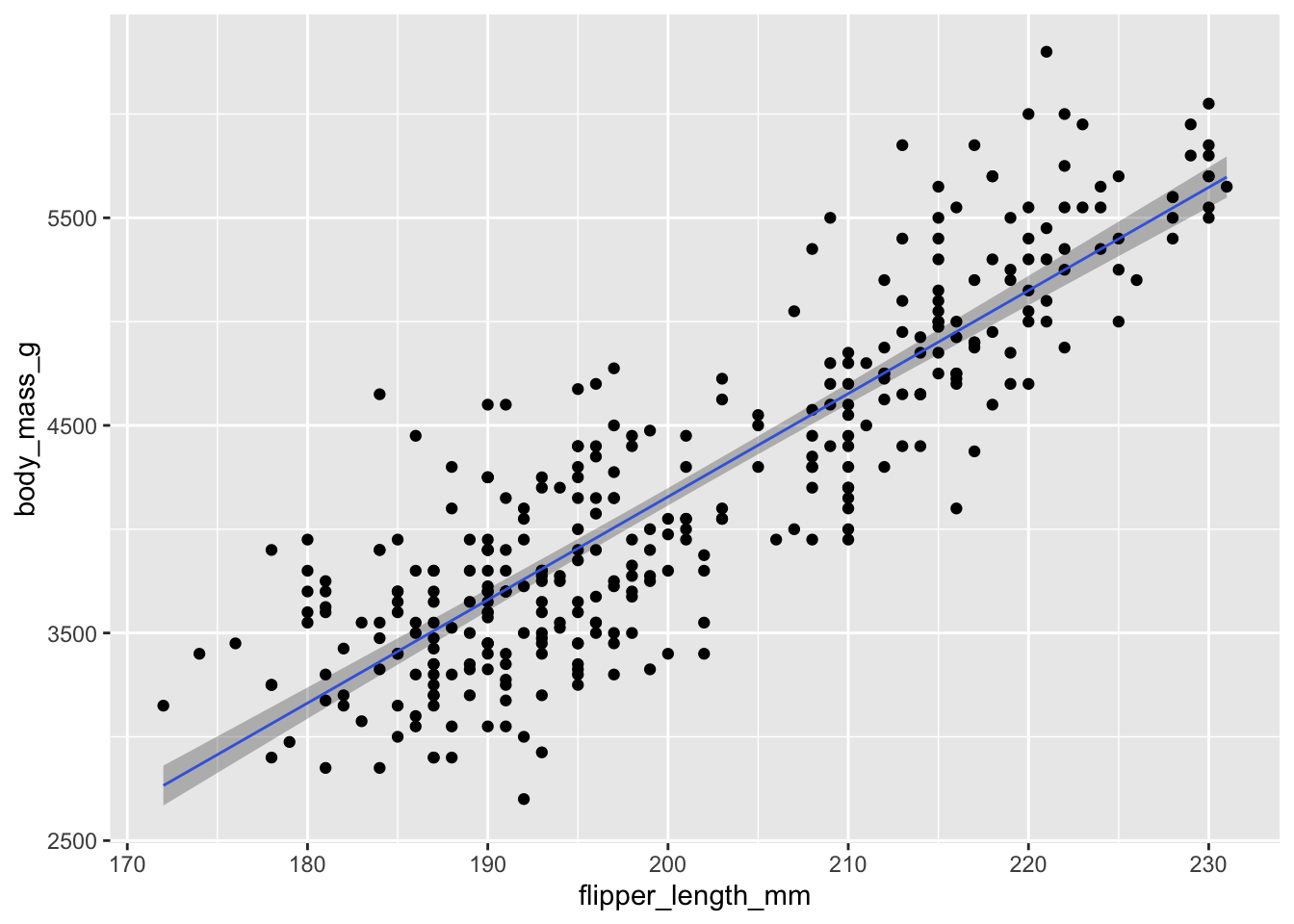
Il peut être intéressant de représenter sur notre graphique l’incertitude associée à notre pente. Comme nous l’avons vu dans les sections précédentes, nous pourrions tracer deux intervalles différents, soit l’intervalle de prédiction ou l’intervalle de confiance, mais la stratégie pour le faire est exactement la même.
La clé pour y parvenir est de savoir que si l’on ne fournit pas de nouveau tableau de données à la fonction predict, elle nous fournira une valeur pour chacune des données en X de notre tableau original. On pourra ensuite relier chacune de ces prédictions à l’aide d’une ligne pour tracer l’intervalle.
Pour connecter le tableau de données de prédictions avec l’original, nous utiliserons la fonction bind_cols, qui connecte les colonnes de plusieurs tableaux ensemble. Soyez par contre très prudents avec cette fonction, car si vos tableaux de sont pas parfaitement dans le même ordre et avec les mêmes lignes, nous n’allez pas connecter les bonnes valeurs ensemble. Une fois les données prêtes, nous utiliserons trois couches de données pour préparer notre graphique, soit un geom_point pour les données, un geom_line pour la pente et un geom_ribbon (i.e. littéralement un ruban) pour l’intervalle de confiance. Remarquez que le geom_ribbon reçoit 2 valeurs de Y, celle du haut et celle du bas de la bande. Aussi, remarquez l’ordre dans lequel j’ai ajouté les couches. Si jamais vous ajoutez la couche ribbon en dernier, cette dernière cachera toutes les autres…
Voici donc le code pour l’intervalle de prédiction :
Remarquez que l’intervalle de prédiction est beaucoup plus large, puisqu’il doit contenir 95 % des données. L’intervalle de confiance est plus étroit. Notez aussi que ce dernier est plus étroit au centre (on est vraiment certains que la pente passe là) et plus incertain dans les extrémités.
Petit fait intéressant : à tout coup, lorsque notre pente sera significativement différente de zéro, il ne sera pas possible de passer une ligne horizontale dans l’intervalle de confiance sans la toucher ou dépasser.
18.11 Récapitulatif
Si on fait un petit récapitulatif des tests vus jusqu’à présent, vous êtes maintenant en mesure de gérer les situations suivantes :
Pour comparer une moyenne à une valeur cible : Test de T à un échantillon
Pour comparer deux moyennes entre-elles : Test de T de Welch.
Pour comparer la moyenne de données pairées : Test de T pairé
Pour comparer la variance de deux échantillons : Test de F.
Pour comparer la moyenne de plus de 3 moyennes : ANOVA.
Pour regarder la relation entre une variable quantitative et une variable catégorique : ANOVA.
Pour vérifier si deux variables quantitatives sont associées : corrélation
Pour quantifier le lien de cause à effet entre deux variables quantitatives : régression linéaire.
18.12 Exercice : La régression linéaire
Pour vivre en pratique à quoi peut ressembler la régression linéaire je vous demande, à l’aide d’une analyse de régression linéaire, de quantifier le lien de cause à effet entre la température et la fréquence de stridulation chez la némobie striée. Vous pouvez réutiliser la base de données présentée à la Section 17.4. Par ailleurs, vous savez par vos connaissances de la littérature que la température affecte la fréquence de stridulation, et jamais l’inverse.
Une fois votre modèle prêt, utilisez-le pour prédire la température en degrés Celcius, si jamais une némobie produit 18 stridulations par seconde. Validez ensuite cette prédiction sur un graphique.
Quelle est l’intervalle de confiance à 99% de cette prédiction?