31 Principes d’inférence causale
31.1 Causes directes et indirectes
Tous les problèmes abordés dans les chapitres précédents étaient structurés de la même façon, soit : une variable d’intérêt, et une (ou plusieurs) variables pouvant l’influencer. Par contre, dans la réalité, la situation est rarement aussi simple.
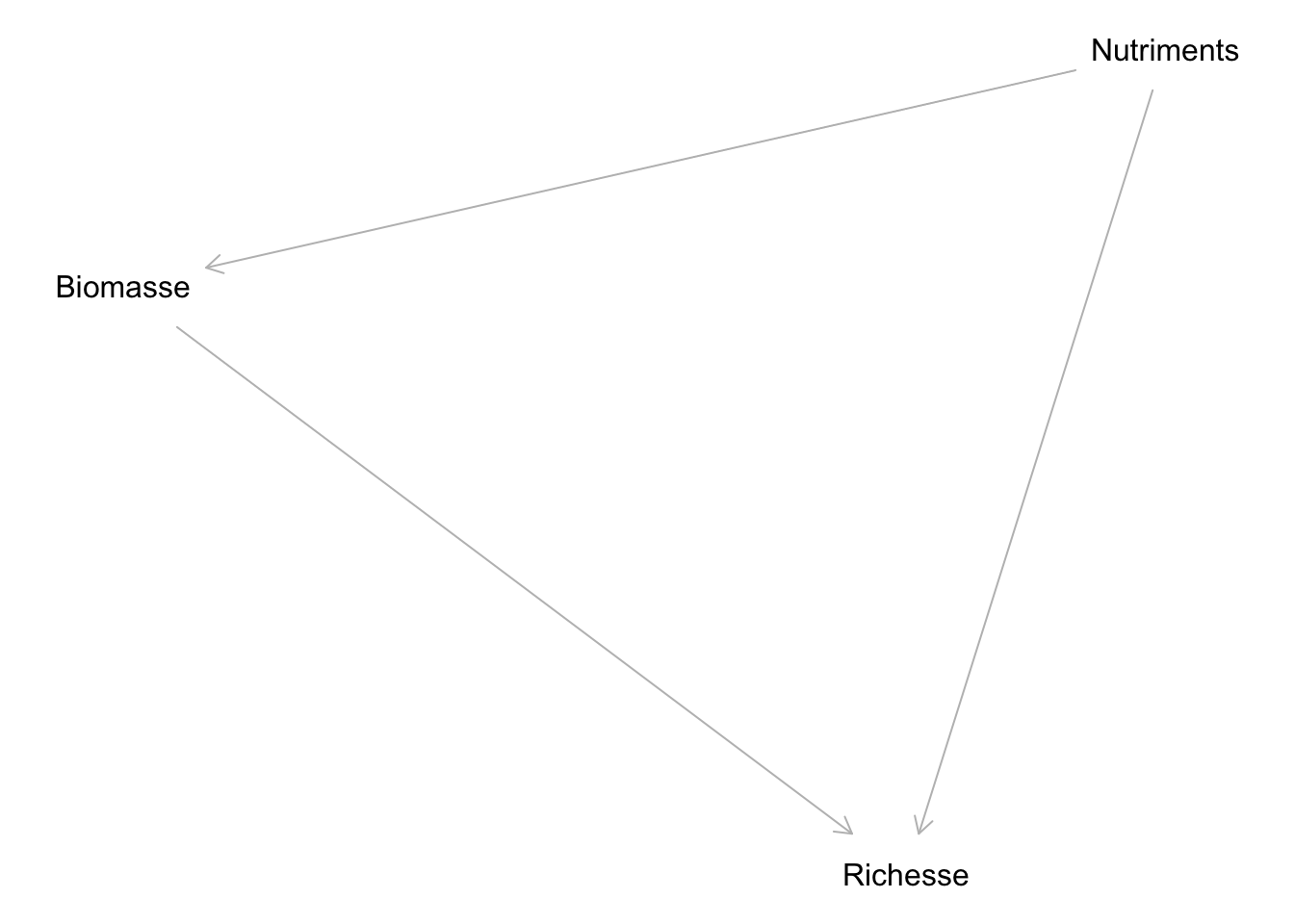
Un des exemples classiques de cette situation concerne les facteurs affectant la richesse en espèces de plantes. Basé sur l’hypothèse de productivité-diversité, on pourrait s’attendre à ce qu’un apport en nutriments augmente la productivité à un site, et donc la biomasse produite. Ensuite, on pourrait s’attendre à ce que cette biomasse, par un effet d’échantillonnage, permette l’existence de plus d’espèces à un même site. D’un autre côté, on pourrait s’attendre à ce que l’ajout de nutriments ait un effet négatif sur la diversité de plantes, par exemple en causant une acidification des sols.
Conceptuellement, nous pourrions illustrer notre système à l’aide du diagramme suivant :
Il existerait donc deux façons pour les nutriments d’affecter la richesse en espèces. Soit directement (par l’acidification), ou soit indirectement à travers une augmentation de la biomasse.
Si l’on voulait tester cette théorie, il faudrait garder en tête qu’il est possible que la situation réelle soit plutôt la suivante :
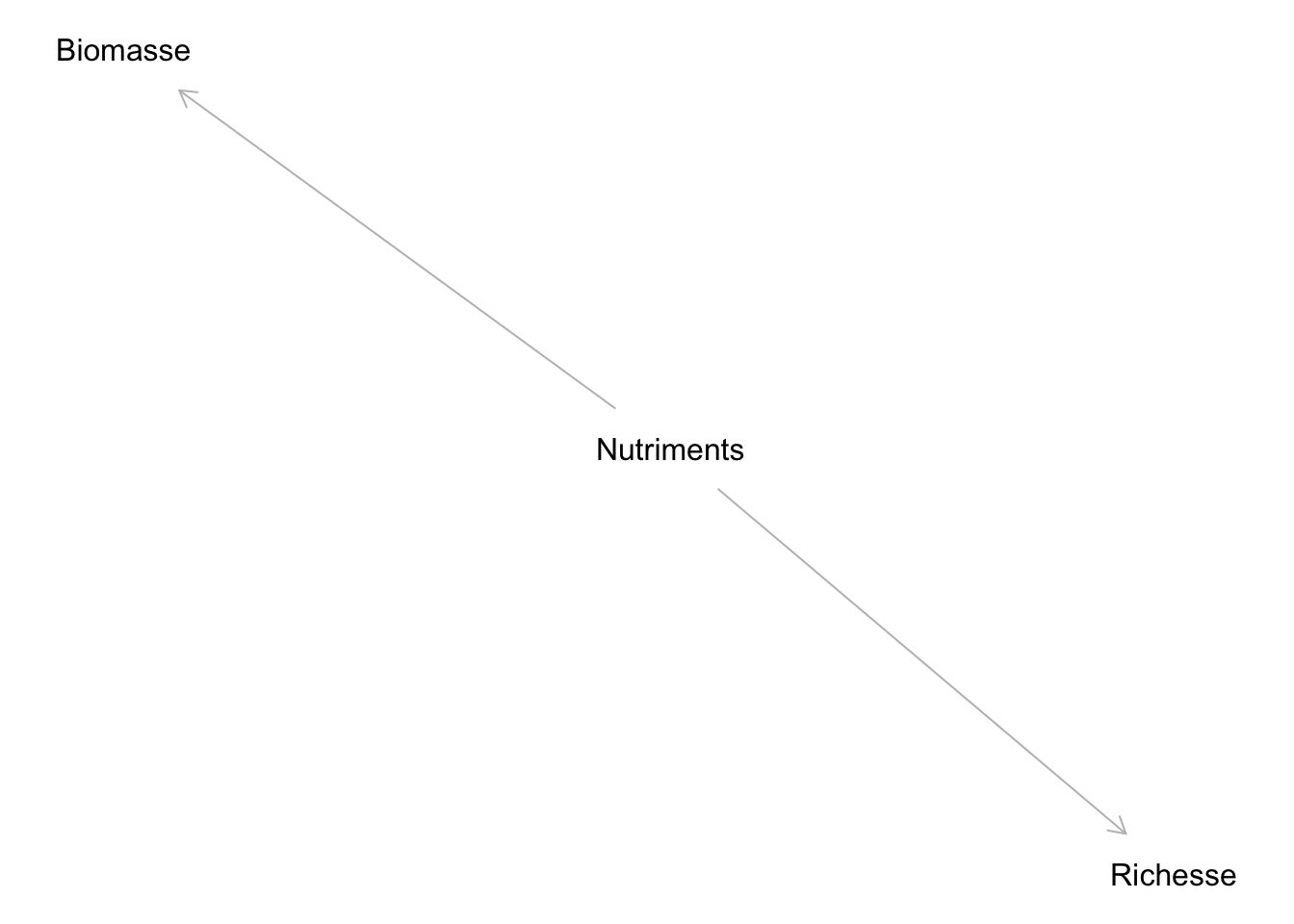
Où seuls les Nutriments affectent directement la Richesse.
Toute la difficulté réside alors dans le fait que, même si la Biomasse n’affecte pas la Richesse, ces dernières pourraient tout de même être corrélées entre elles, parce qu’elles sont toutes deux affectées par les Nutriments.
Mais… si l’effet arrive seulement par les Nutriments, la relation Biomasse-Richesse devrait disparaître si on corrige d’abord pour l’apport en nutriments. Il existe un terme technique pour ce phénomène, nommé indépendance conditionnelle. La Richesse et la Biomasse sont indépendantes, à condition que l’on tienne compte des Nutriments.
Autrement dit : “Y a-t-il une quelconque valeur à connaître une variable, une fois que l’autre est prise en compte”. Ici, est-ce utile de connaître la Biomasse pour comprendre la Richesse si l’on connaît déjà les Nutriments.
Et comme nous avons vu au Chapitre 28, cette définition est presque mot pour mot la définition d’une pente partielle dans la régression multiple.
Donc, notre plan d’analyse pour bien comprendre le phénomène sera le suivant :
- Tester si les Nutriments expliquent la Richesse. C’est l’effet direct.
- Tester si les Nutriments expliquent la Biomasse. C’est la relation vers la variable médiatrice.
- En troisième lieu, tester l’indépendance conditionnelle entre la Richesse et la Biomasse si on conditionne sur les Nutriments. Autrement dit, dans un modèle où l’on tente d’expliquer la Richesse par la Biomasse ET les Nutriments, la Biomasse ne devrait pas être un prédicteur de la Richesse.
Note
Ces analyses des chemins directs ou indirects que peuvent prendre les liens de causes à effets sont souvent nommées analyses de médiation. La variable intermédiaire, ici Biomasse est alors nommée la variable médiatrice.
31.2 Labo : les causes directes et indirectes
Pour tous les exemples de ce chapitre, je vous ai généré des jeux de données afin de tester les principes.
Vous pouvez les télécharger ici, là, et là.
Donc allons donc commencer par charger le premier jeu de données et les librairies nécessaires à notre travail
library(tidyverse)
donnees <- read_csv("donnees/Moderation.csv")Rows: 50 Columns: 3
── Column specification ───────────────────────────────
Delimiter: ","
dbl (3): Nutriments, Biomasse, Richesse
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Si on explore visuellement ces données, on voit clairement la corrélation entre les Nutriments et la Richesse, mais aussi celle entre la Biomasse et la Richesse et celle entre les Nutriments et la Biomasse :
GGally::ggpairs(donnees)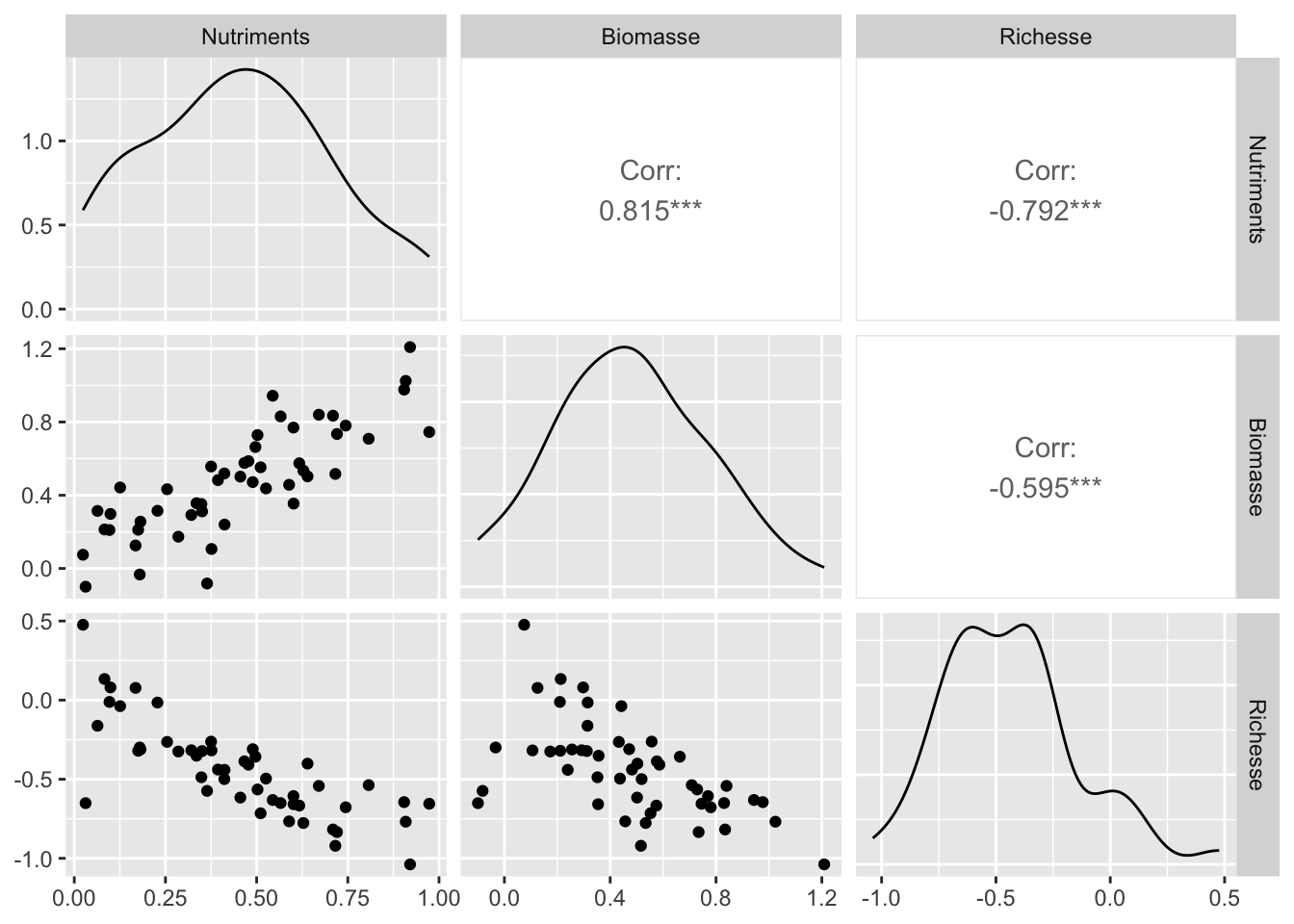
Et voici maintenant les 3 modèles à tester :
summary(lm(Richesse ~ Nutriments, data = donnees))
Call:
lm(formula = Richesse ~ Nutriments, data = donnees)
Residuals:
Min 1Q Median 3Q Max
-0.60121 -0.11845 -0.01965 0.10605 0.51940
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.02075 0.05351 -0.388 0.7
Nutriments -0.93690 0.10428 -8.985 7.47e-12 ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1827 on 48 degrees of freedom
Multiple R-squared: 0.6271, Adjusted R-squared: 0.6194
F-statistic: 80.73 on 1 and 48 DF, p-value: 7.465e-12summary(lm(Biomasse ~ Nutriments, data = donnees))
Call:
lm(formula = Biomasse ~ Nutriments, data = donnees)
Residuals:
Min 1Q Median 3Q Max
-0.48005 -0.11205 0.01675 0.11124 0.37549
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.05323 0.04990 1.067 0.291
Nutriments 0.94608 0.09725 9.728 6.19e-13 ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1704 on 48 degrees of freedom
Multiple R-squared: 0.6635, Adjusted R-squared: 0.6565
F-statistic: 94.64 on 1 and 48 DF, p-value: 6.192e-13Donc, comme prévu, les Nutriments affectent à la fois la Richesse ET la Biomasse.
Maintenant, il faut tester l’indépendance conditionnelle : est-ce que l’effet de la Biomasse sur la Richesse disparaît lorsque l’on ajoute les Nutriments dans le modèle :
summary(lm(Richesse ~ Nutriments + Biomasse, data = donnees))
Call:
lm(formula = Richesse ~ Nutriments + Biomasse, data = donnees)
Residuals:
Min 1Q Median 3Q Max
-0.57373 -0.13530 -0.01433 0.08930 0.51955
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.02877 0.05417 -0.531 0.598
Nutriments -1.07936 0.17986 -6.001 2.68e-07 ***
Biomasse 0.15058 0.15485 0.972 0.336
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1828 on 47 degrees of freedom
Multiple R-squared: 0.6345, Adjusted R-squared: 0.6189
F-statistic: 40.79 on 2 and 47 DF, p-value: 5.353e-11Donc : la Biomasse n’a PAS d’effet sur la Richesse. Leur corrélation existe uniquement parce qu’elles sont toutes deux causées par l’apport en Nutriments.
Si jamais dans ce 3e modèle, les deux variables étaient sorties comme importantes, nous aurions alors montré que les Nutriments affectent directement la Richesse en espèces, mais que cette dernière est aussi affectée indirectement par les Nutriments à travers la quantité de Biomasse produite.
31.3 Facteurs confondants
Un phénomène commun en écologie est assurément celui des facteurs confondants. Ces derniers surviennent fréquemment lorsque plusieurs variables sont contrôlées par une même cause, mais que cette dernière n’a pas été mesurée dans notre expérience.
Imaginons par exemple que vous étudiez les facteurs affectant la Croissance des plantes. Une de vos suppositions est que la présence de Pollinisateurs pourrait leur être bénéfique, et comme vous avez accès aux données d’occupation des ruches dans le secteur, vous tester tout de suite votre idée.

31.4 Labo : Les facteurs confondants
donnees <- read_csv("donnees/Confondant.csv")Rows: 50 Columns: 3
── Column specification ───────────────────────────────
Delimiter: ","
dbl (3): Temperature, Pollinisateurs, Croissance
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.donnees |>
ggplot(aes(Pollinisateurs, Croissance)) +
geom_point()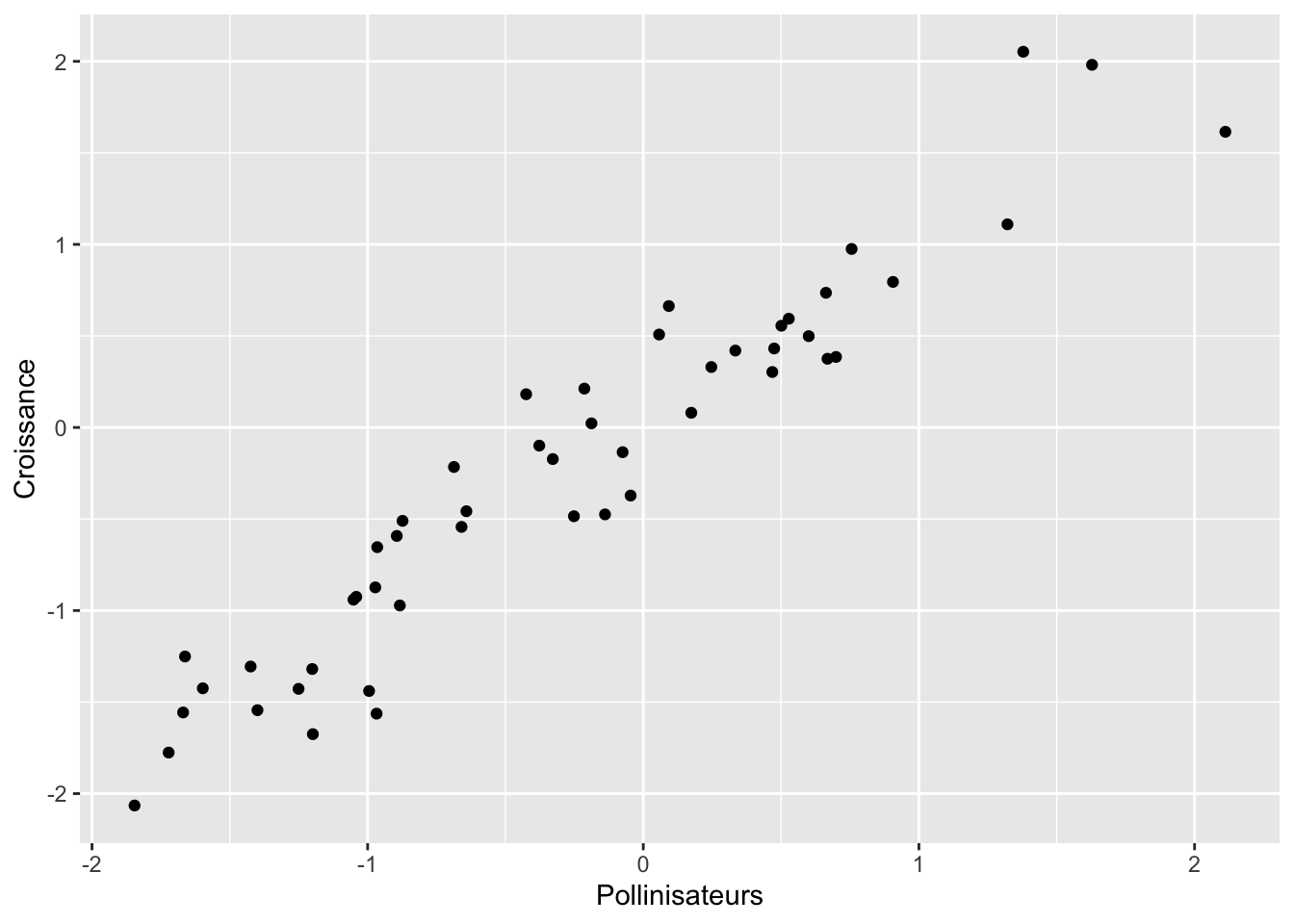
summary(lm(Croissance ~ Pollinisateurs, data = donnees))
Call:
lm(formula = Croissance ~ Pollinisateurs, data = donnees)
Residuals:
Min 1Q Median 3Q Max
-0.64163 -0.20010 0.04076 0.18005 0.64206
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.04017 0.04446 0.903 0.371
Pollinisateurs 0.99390 0.04527 21.955 <2e-16
(Intercept)
Pollinisateurs ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3013 on 48 degrees of freedom
Multiple R-squared: 0.9094, Adjusted R-squared: 0.9076
F-statistic: 482 on 1 and 48 DF, p-value: < 2.2e-16Vous pourriez facilement conclure que les Pollinisateurs causent la Croissance.
Mais à ce point, vous n’avez encore rien prouvé au-delà d’une corréation. Votre conclusion pourrait tout de même être erronée, si par exemple les deux phénomènes ont une cause commune, comme ici la Température, i.e.
Si on observe les relations une à une, tout semble relié :
donnees |>
ggplot(aes(Temperature,Pollinisateurs)) +
geom_point()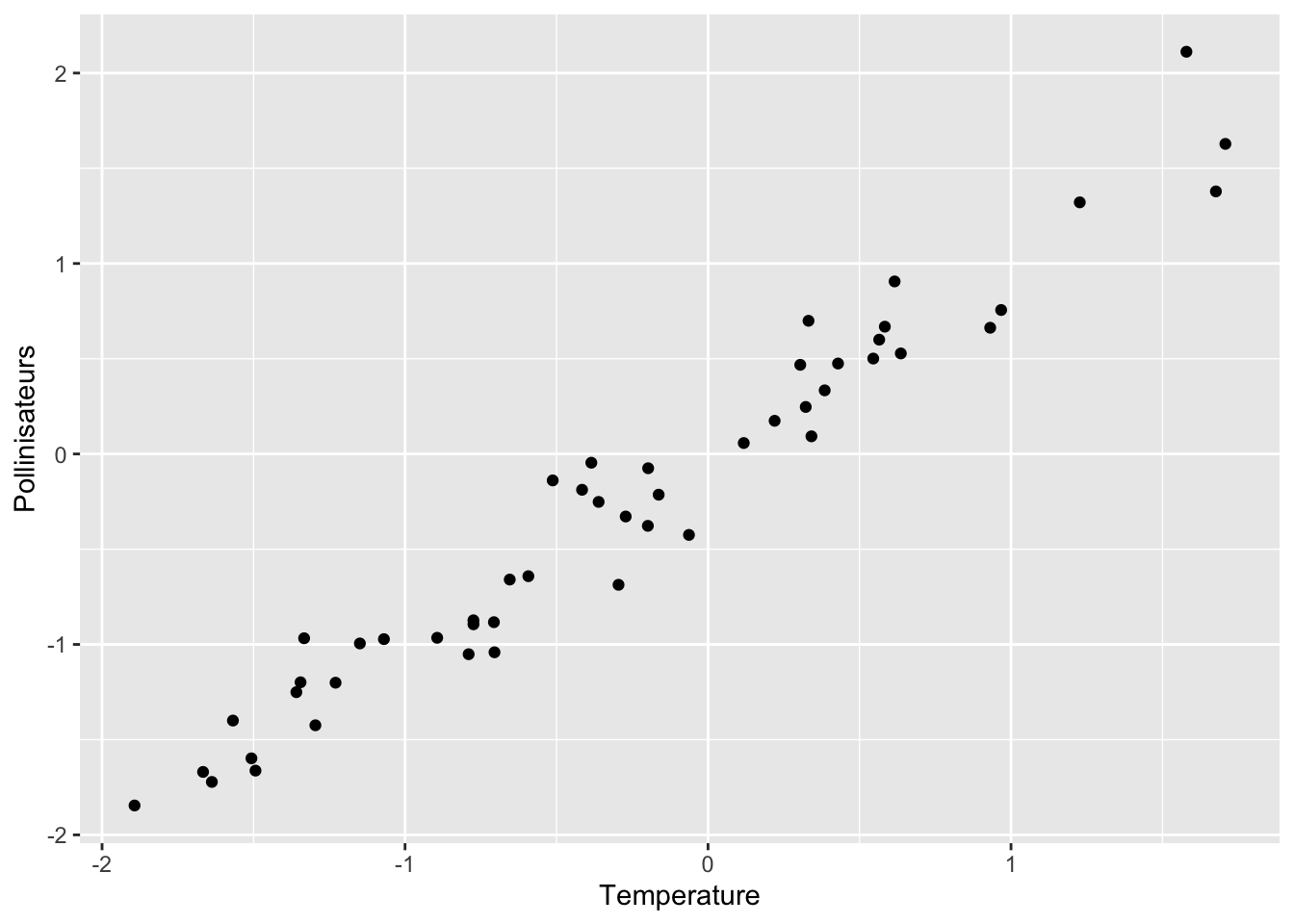
donnees |>
ggplot(aes(Temperature,Croissance)) +
geom_point()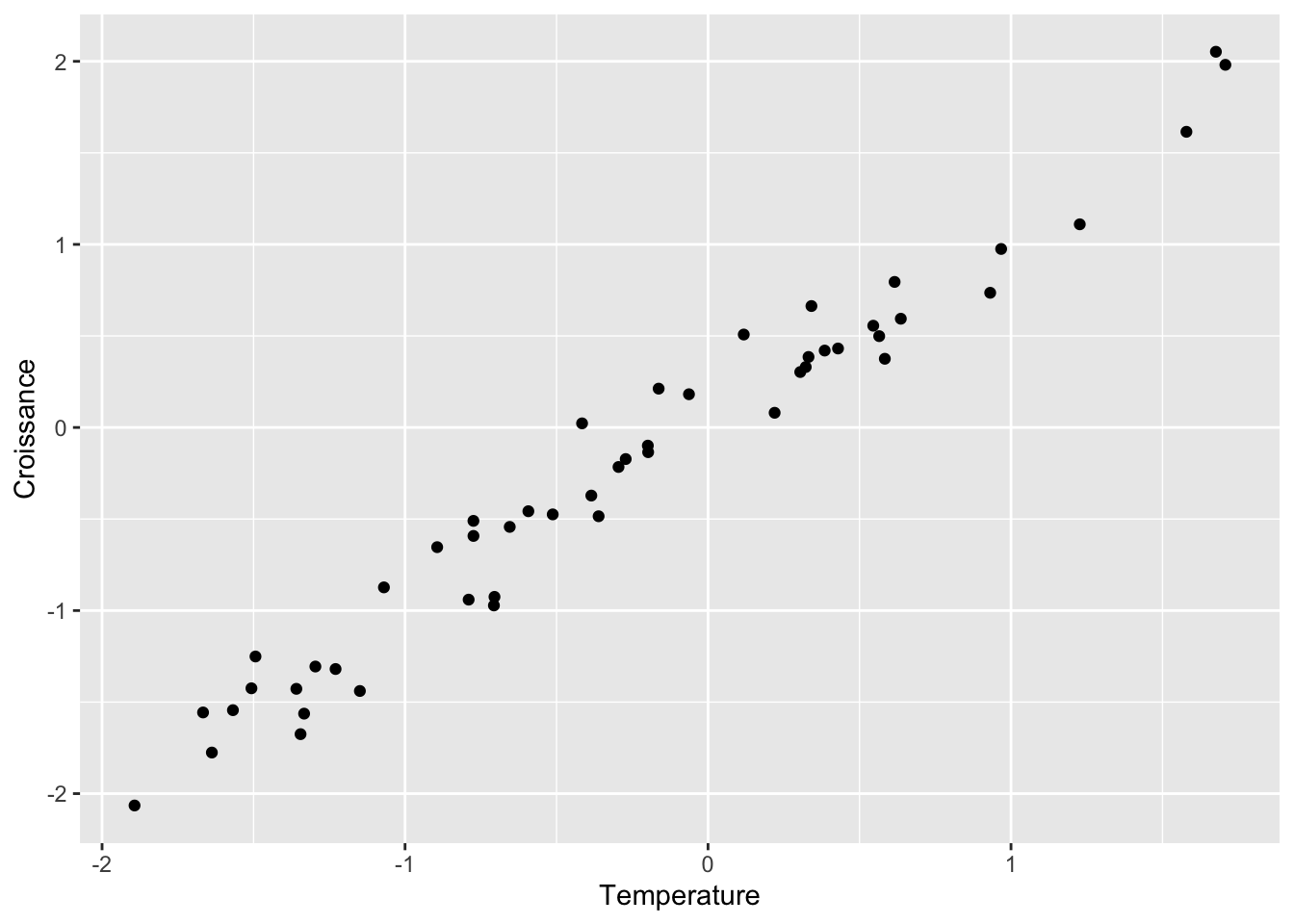
Mais, si on avait inclus la Température dans notre modèle expliquant la Croissance, on aurait rapidement constaté que les Pollinisateurs n’apportent aucune information utile supplémentaire en plus de la Température :
summary(lm(Croissance ~ Temperature + Pollinisateurs, data = donnees))
Call:
lm(formula = Croissance ~ Temperature + Pollinisateurs, data = donnees)
Residuals:
Min 1Q Median 3Q Max
-0.31799 -0.13273 -0.00775 0.14037 0.43719
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.04832 0.02763 1.749 0.0869
Temperature 1.17352 0.13336 8.800 1.68e-11
Pollinisateurs -0.13203 0.13100 -1.008 0.3187
(Intercept) .
Temperature ***
Pollinisateurs
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1871 on 47 degrees of freedom
Multiple R-squared: 0.9658, Adjusted R-squared: 0.9643
F-statistic: 663.5 on 2 and 47 DF, p-value: < 2.2e-16
Note
Remarquez qu’ici, la seule façon de ne pas commettre cette erreur serait de bien connaître la Croissance et d’avoir pris le temps de mesurer aussi la Température dans notre expérience. Rien dans nos statistiques n’indiquait un problème.
31.5 Le biais par collisionneur
Les deux principes d’inférence causale précédents étaient relativement intuitifs à comprendre. Le troisième que nous verrons dans ce chapitre est à la fois beaucoup plus difficile à comprendre, mais encore plus dangereux que les deux premiers, puisqu’il peut survenir même si nous avons mesurées TOUTES les variables impliquées.
Supposons que le phénomène qui nous intéresse soit de comprendre si la Température influence la Richesse en espèces de plantes.

31.6 Labo : le biais par collisionneur
Si cette relation est erronnée, on le détecte facilement, autant visuellement :
donnees <- read_csv("donnees/Collisionneur.csv")Rows: 50 Columns: 3
── Column specification ───────────────────────────────
Delimiter: ","
dbl (3): Richesse, Temperature, Productivite
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.donnees |>
ggplot(aes(Temperature,Richesse)) +
geom_point()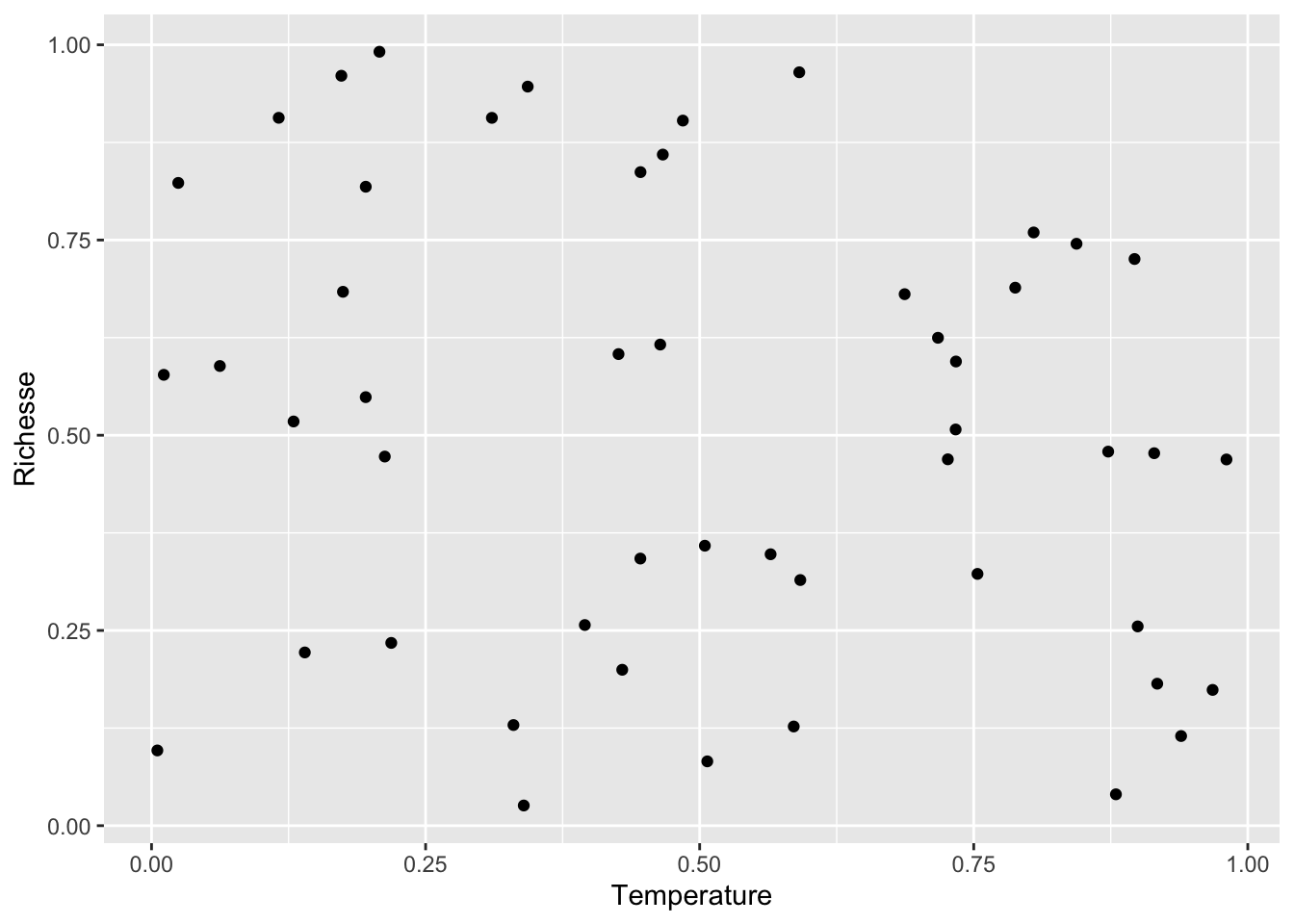
Que par la modélisation :
summary(lm(Richesse ~ Temperature, data = donnees))
Call:
lm(formula = Richesse ~ Temperature, data = donnees)
Residuals:
Min 1Q Median 3Q Max
-0.52073 -0.22448 0.02507 0.24067 0.47207
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.61821 0.07941 7.785 4.66e-10 ***
Temperature -0.21234 0.13630 -1.558 0.126
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2834 on 48 degrees of freedom
Multiple R-squared: 0.04812, Adjusted R-squared: 0.02829
F-statistic: 2.427 on 1 and 48 DF, p-value: 0.1258Aucune relation!
Cependant, si la Richesse et la Temperature sont deux variables qui influencent la Productivité
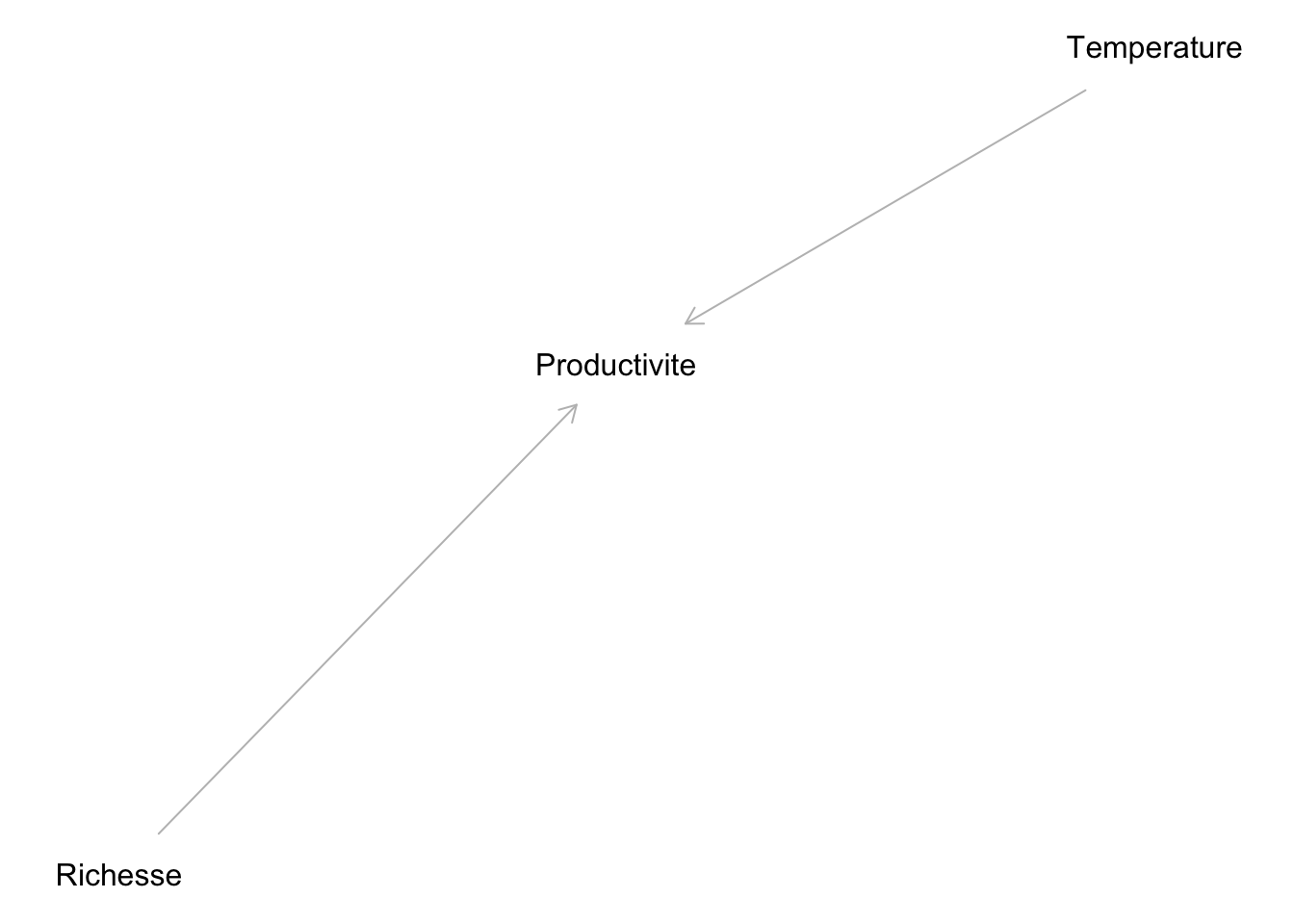
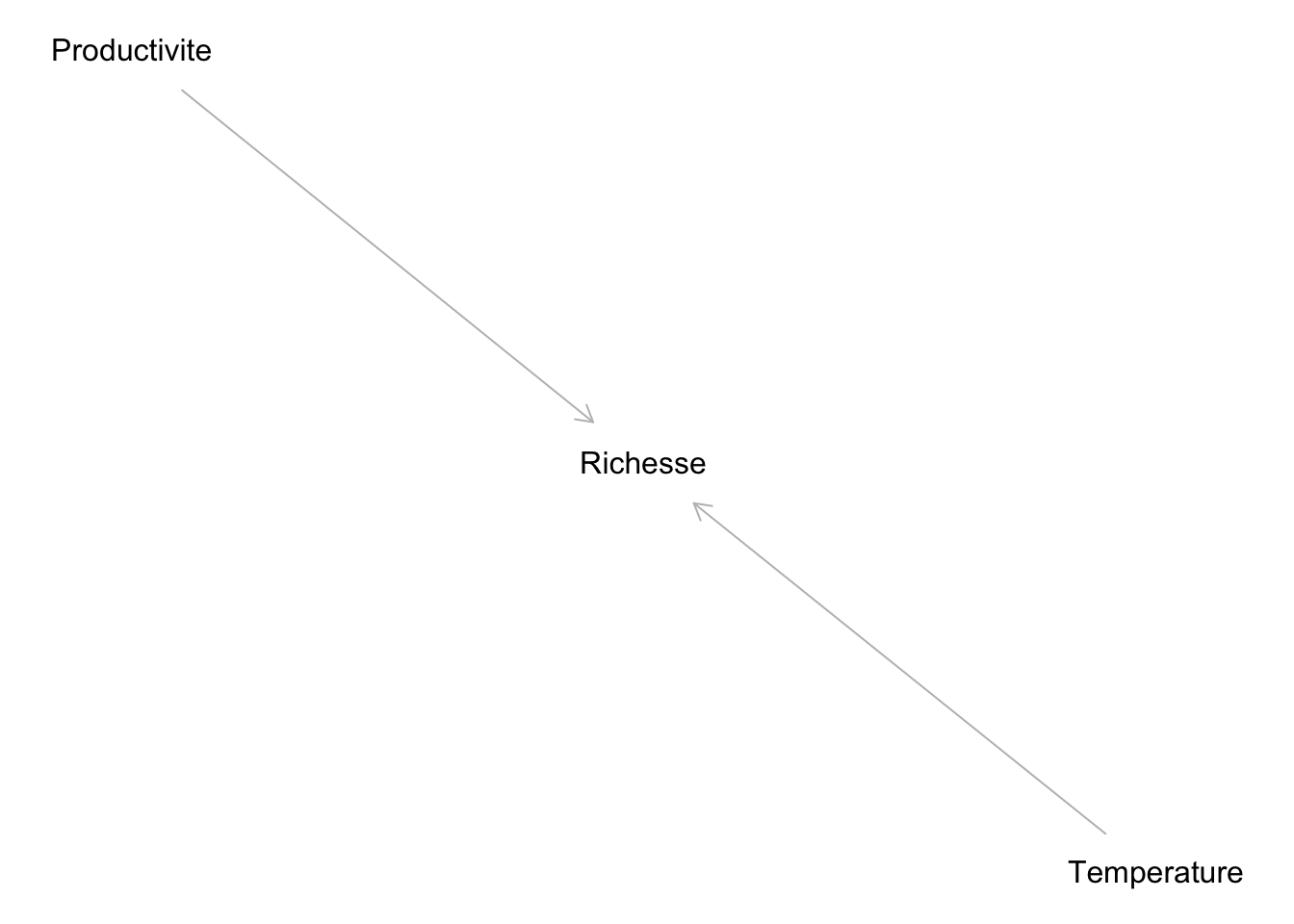
Et que par une mauvaise compréhension du phénomène, nous analysons nos données comme si la Productivité influençait la Richesse :
summary(lm(Richesse ~ Temperature + Productivite, data = donnees))
Call:
lm(formula = Richesse ~ Temperature + Productivite, data = donnees)
Residuals:
Min 1Q Median 3Q Max
-0.44831 -0.07663 0.01267 0.10174 0.31573
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.26308 0.06211 4.236 0.000105 ***
Temperature -0.78933 0.10439 -7.561 1.16e-09 ***
Productivite 0.64337 0.07073 9.096 6.21e-12 ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1724 on 47 degrees of freedom
Multiple R-squared: 0.6552, Adjusted R-squared: 0.6405
F-statistic: 44.65 on 2 and 47 DF, p-value: 1.36e-11On trouve alors une fausse relation entre la Température et la Richesse. Même si ces variables n’étaient pas reliées, on les évalue comme reliées si on les met dans le même modèle qu’une variable qu’elles influencent toutes les deux.
La Productivité agit dans ce cas comme un collisionneur.
La façon la plus simple de comprendre ce phénomène est de le prendre à l’envers :
- La température et la richesse contrôlent ensemble la productivité.
- Donc, si la productivité est forte et la température faible, la richesse DOIT ÊTRE ÉLEVÉE
- À l’inverse, si la température est élevée et la productivité faible la richesse DOIT ÊTRE FAIBLE.
Autrement dit, les relations
Température -> Productivité et
Richesse -> Productivité
forcent inévitablement une relation entre Température et Richesse, SI ON CONNAIT LA VALEUR DE LA PRODUCTIVITÉ.
Ceci est clairement un des principes statistiques les moins simples à comprendre, mais aussi un de ceux qui pourrait avoir les plus graves conséquences dans notre compréhension d’un phénomène.
Il n’existe pas non plus de solution statistique simple au problème des collisionneurs au moment de l’ajustement du modèle. Le problème provient d’une conceptualisation erronée des phénomènes.
Avertissement
La conclusion principale concernant le biais par collisionneur est surtout la suivante : il ne faut pas bêtement insérer toutes les variables potentielles dans un modèle de régression multiple et voir ce qu’il en ressort. Il est important de s’interroger à savoir si certaines d’entre elles pourraient être le point d’arrivée d’une cause commune, et si oui, il faut absolument omettre le collisionneur si l’on veut comprendre l’effet causal.
31.7 Exemple champ gauche
Un exemple classique de biais de collisionneur, mais aucunement relié à la biologie est le suivant :
Nous savons que la recette pour devenir un artiste célèbre est d’être à la fois beau et talentueux :
Célébrité = Beauté + Talent.
Dans la population en général, Beauté et Talent ne sont aucunement reliés.
Cependant, si on s’emmêle les pinceaux et que l’on ajoute la conséquence commune de la Beauté et du Talent dans un modèle tentant d’expliquer la beauté : i.e. Beauté ~ Célébrité + Talent, on trouvera accidentellement une relation négative entre Beauté et Talent. Car si un artiste est Célèbre et qu’il n’est pas Talentueux, il est nécessairement Beau.
La Beauté et le Talent ne sont pas reliés, mais si on ajoute la Célébrité comme collisionneur, alors la Beauté et le Talent auront L’AIR reliés négativement.
31.8 Résumé
Lorsque l’on travaille avec plus d’une variable pouvant être la cause d’un phénomène d’intérêt, il importe donc de bien réfléchir à la structure du problème de cause à effet que l’on tente de décrire ou mesurer.
Outre le patron simpliste où toutes les variables mesurées affectent directement le phénomène, on peut aussi faire face à :
- Un médiateur (e.g. X -> M -> Y & X -> Y) : lorsque l’on contrôle pour X, l’effet de M peut disparaître
- Un facteur confondant (i.e. X <- C -> Y) : lorsque l’on contrôle pour C, l’effet de X disparaît
- Un collisionneur (i.e. X -> C <- Y) : lorsque l’on insère C dans le modèle, on induit une fausse corrélation entre X et Y.
Donc, en résumé, il est très souvent productif d’inclure des variables supplémentaires dans notre modèle, car ces dernières permettent de clarifier les liens de cause à effet. Cependant, il ne faut jamais inclure de variables qui sont la conséquence commune de deux variables dans le modèle. Sinon, nos inférences pourraient être complètement faussées.