Les analyses de covariance sont les modèles statistiques les plus complexes que nous étudierons dans la section portant sur les tests statistiques. Contrairement à tout ce que nous avons vu auparavant, ils permettent d’analyser simultanément plusieurs variables explicatives dans un même modèle (mais toujours une seule variable expliquée). Dans sa définition la plus stricte (celle que nous verrons dans le cours), une analyse de covariance (ANCOVA) est un modèle d’ANOVA, mais auquel on ajoute aussi une variable explicative continue. Cette variable explicative, aussi nommée covariable, permet de corriger nos mesures pour, par exemple, enlever un effet confondant.
Ce genre de situation peut, par exemple, survenir si l’on veut déterminer si l’ajout de chaux augmente la production de graines chez une espèce d’arbre. Bien que ce qui nous intéresse serait l’effet de l’ajout de chaux, le facteur principal qui contrôle le nombre de graines produites par l’arbre sera sans aucun doute sa taille. Plus l’arbre est grand, plus il produira de graines. Il y aura donc beaucoup de “bruit” dans nos mesures de production de graines. Une grande partie de la variabilité du nombre de graines que nous observerons ne proviendra pas de la variable qui nous intéresse. De là l’utilité de mesurer une covariable (ici la hauteur de l’arbre), qui permettra de tenir compte de ce bruit et de le mettre de côté pour bien évaluer l’effet de la chaux.
20.2 Le modèle statistique
Le modèle classique de l’ANCOVA peut s’écrire de différentes façons, qui reviendront d’une façon ou d’une autre à peu près à ceci :
\[
y = b_0 + b_1x_1+b_2x_2
\]
Autrement dit, chaque observation (y) est prédite par l’ordonnée à l’origine (b0) à laquelle on additionne l’effet de la covariable (b1) et l’effet de la variable catégorique (b2). L’équation est donc identique à la régression linéaire, mais à laquelle on ajoute un terme b2 pour l’effet de variable catégorique. L’interprétation des chiffres associés à b1 et b2 est relativement directe, soit respectivement le changement de y pour un changement de x1 et le changement en y pour l’effet de b2. Par contre, la valeur associée à b0 est plutôt abstraite et de peu d’intérêt biologique. Il s’agit de la valeur prédite par notre modèle lorsque la covariable vaut zéro et que l’on a pas l’effet de la variable qualitative.
Dans cette notation, la variable x2 est formée de zéros et de uns, selon que notre variable catégorique présente, pour chaque ligne, la valeur du groupe de référence ou non. Cette transformation se nomme “dummy coding” et sera effectuée pour vous par R. Les valeurs transformées en zéro deviendront le niveau de référence, et les autres seront mesurées comme des différences par rapport à ce niveau. Nous y reviendrons plus en détails dans le deuxième cours de stats, les technicalités associées ne sont pas si importantes ici pour le moment.
Ce qu’il est important de comprendre pour le moment, c’est que notre modèle contiendra maintenant 3 paramètres, soit l’ordonnée à l’origine (b0), la pente associée à la covariable (b1) et l’effet de la variable catégorique par rapport à son niveau de référence (b2).
Comme pour la régression linéaire, l’estimation des paramètres de ce modèle s’effectuera avec la méthode des moindres carrés, mais avec un calcul plus complexe que ce que nous calculerons à la main dans ce premier cours. Nous laisserons R faire les calculs pour nous.
20.3 Les assomptions de l’ANCOVA
La première chose à savoir concernant le modèle d’ANCOVA, est que toutes les assomptions de la régression linéaire s’appliquent aussi à l’ANCOVA.
Avant la modélisation, nous devons donc réfléchir à l’indépendance de nos observations. Après la modélisation, il faudra valider la normalité des erreurs et l’homogénéité des résidus et vérifier si une ou des observations pourraient avoir une forte influence sur notre modèle. L’ANCOVA ajoute une assomption supplémentaire à tout cela, qui est que les pentes soient homogènes entre les deux groupes. Autrement dit, l’ANCOVA, au sens strict, est conçue pour tester des différences d’ordonnée à l’origine, mais pas des différences de pentes.
20.4 Labo : l’ANCOVA
Pour illustrer le calcul de l’ANCOVA, nous passerons directement à un exemple en R, puisque vous n’effectuerez probablement jamais manuellement les calculs associés à l’estimation des paramètres.
Nous analyserons donc un jeu de données où on évaluera comment l’application de chaux influence la production de graines d’une espèce d’arbres, mais en tenant compte dans notre analyse de l’effet de la taille de l’arbre sur sa production de graines. Nous avons mesuré pour notre expérience 28 arbres, 13 au pied desquels on a ajouté de la chaux, et 15 sans traitement de chaux. Nous avons mesuré pour chaque arbre la production de graines et le diamètre de l’arbre (en cm). Le fichier CSV associé à ces données est disponible avec les notes de cours1.
Étape 1 : Définir les hypothèses
Bien que notre modèle statistique soit plus complexe que les précédents, notre question d’intérêt et les hypothèses associées sont somme toutes assez simples : est-ce que l’application de chaux influence la production de graines de nos arbres. Autrement dit, est-ce que la moyenne de production de graines avec et sans chaux est la même, une fois que nous tenons en compte les différences de taille des arbres
Comme pour tous les autres outils statistiques, il vaut la peine ici de commencer par regarder à quoi ressemblent nos données avant de se lancer. Nous en profiterons aussi pour charger les librairies nécessaires à notre travail. Nous en profitons aussi pour convertir la variable Traitement en variable catégorique (factor).
library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
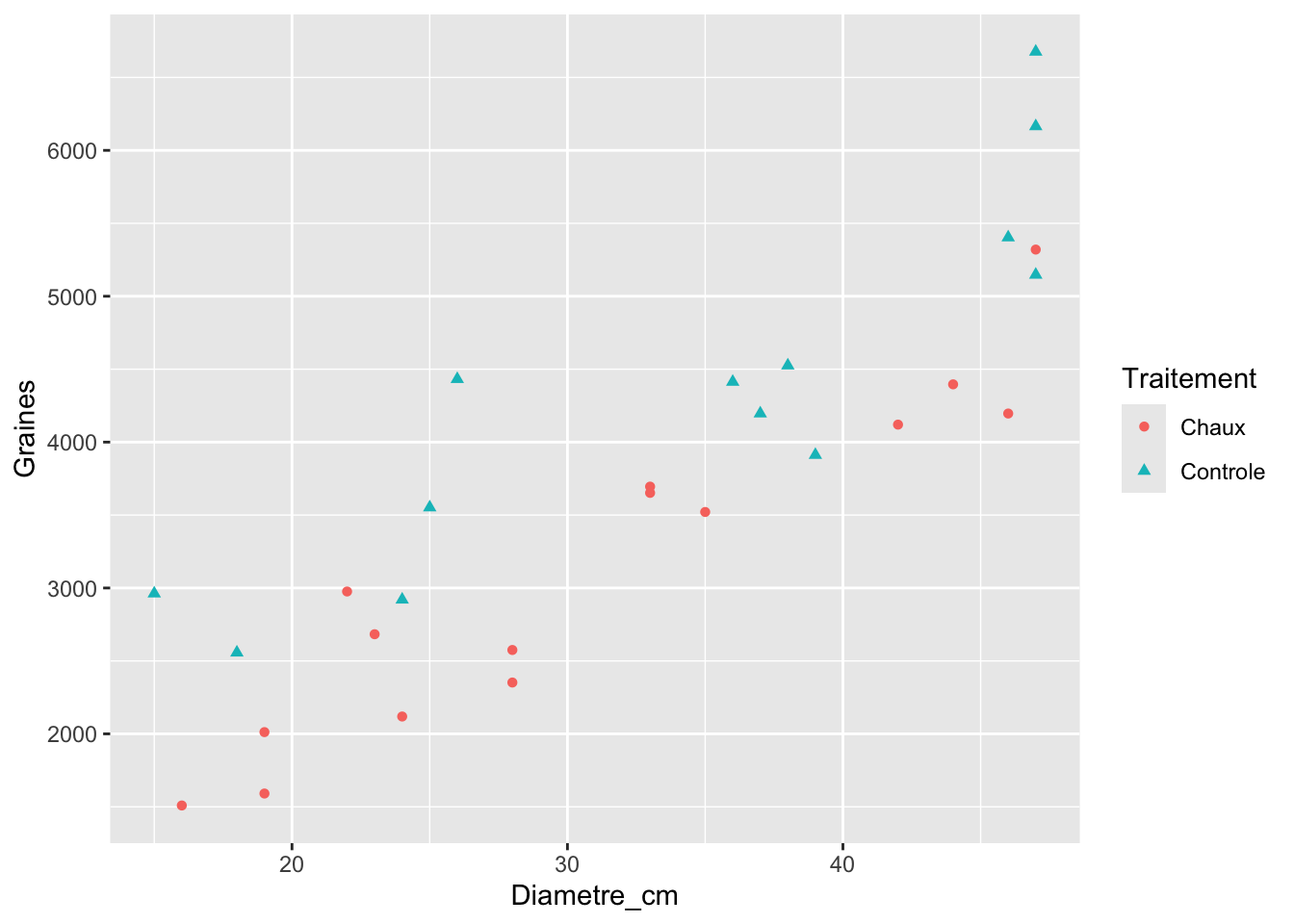
arbres <-read.csv("donnees/arbres.csv") |>mutate(Traitement =as.factor(Traitement)) arbres |>ggplot(aes(x = Diametre_cm, y = Graines, color = Traitement, shape = Traitement )) +geom_point()
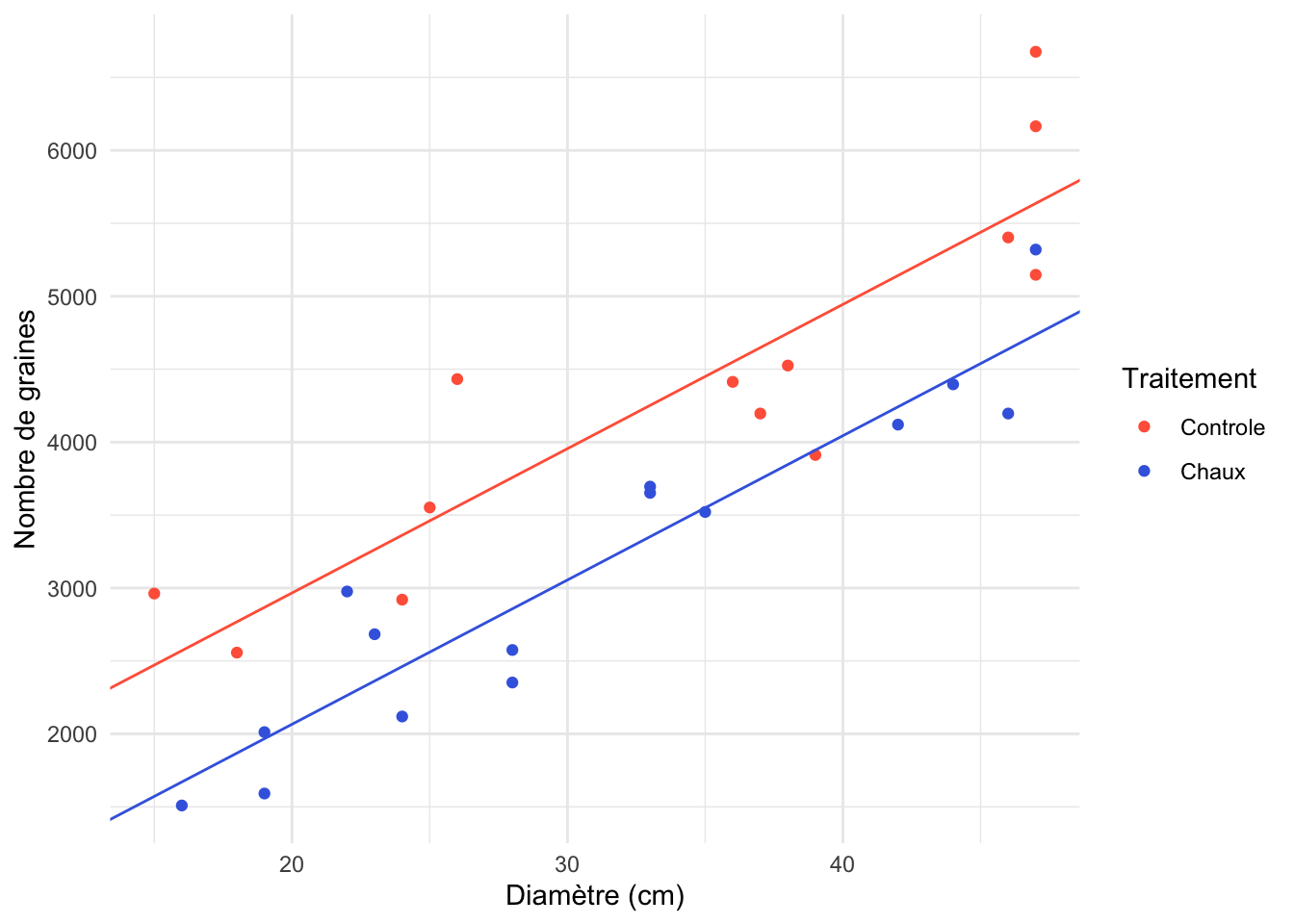
Dans ce graphique, on constate qu’en général, nos variables Diamètre et Graines sont reliées de façon linéaire. La variance semble homogène sur l’ensemble du gradient et les pentes, à l’œil, semblent relativement homogènes entre les deux groupes de traitement. On a donc tout ce qu’il nous faut pour lancer l’analyse.
En regardant le graphique, on devrait s’attendre à trouver une différence entre nos traitements, c’est-à-dire que l’ordonnée à l’origine de nos pentes semble clairement différente, le traitement de chaux semblant diminuer la production de graines comparé au contrôle.
Étapes 3 et 4 : Calculer la statistique de test et obtenir la valeur de p
Comme pour la régression linéaire, la façon la plus directe d’estimer les paramètres de l’équation d’ANCOVA (b0, b1 et b2) est par la méthode des moindres carrés. La fonction pour calculer l’ANCOVA dans R est la même que celle pour la régression, soit la fonction lm.
Par contre, nous devons faire une petite modification à notre base de données avant de commencer. Nous avons discuté du fait que le paramètre b0 représente le niveau de référence et b2 l’effet de la variable catégorique par rapport à ce niveau de référence. R ne peut pas deviner tout seul laquelle des valeurs de notre variable qualitative doit être le niveau de référence. Voyons d’abord ce que R avait choisi pour nous :
levels(arbres$Traitement)
[1] "Chaux" "Controle"
Comme “Chaux” est le premier item retourné dans la liste, R croit que nous voulons celui-là comme valeur de référence.
Comme ici il sera plus logique que “Controle” soit notre niveau de référence, nous allons modifier notre variable catégorique pour refléter cela :
La fonction relevel permet de changer le niveau de référence d’une variable catégorique. Remarquez que pour que cela modifie vraiment variable, nous devons écraser l’ancien tableau de données avec le nouveau, avec l’opérateur d’assignation. On peut maintenant vérifier que le niveau de référence est le bon :
levels(arbres$Traitement)
[1] "Controle" "Chaux"
Nous pouvons maintenant ajuster notre modèle d’ANCOVA comme ceci :
m <-lm(Graines~Diametre_cm+Traitement, data = arbres)
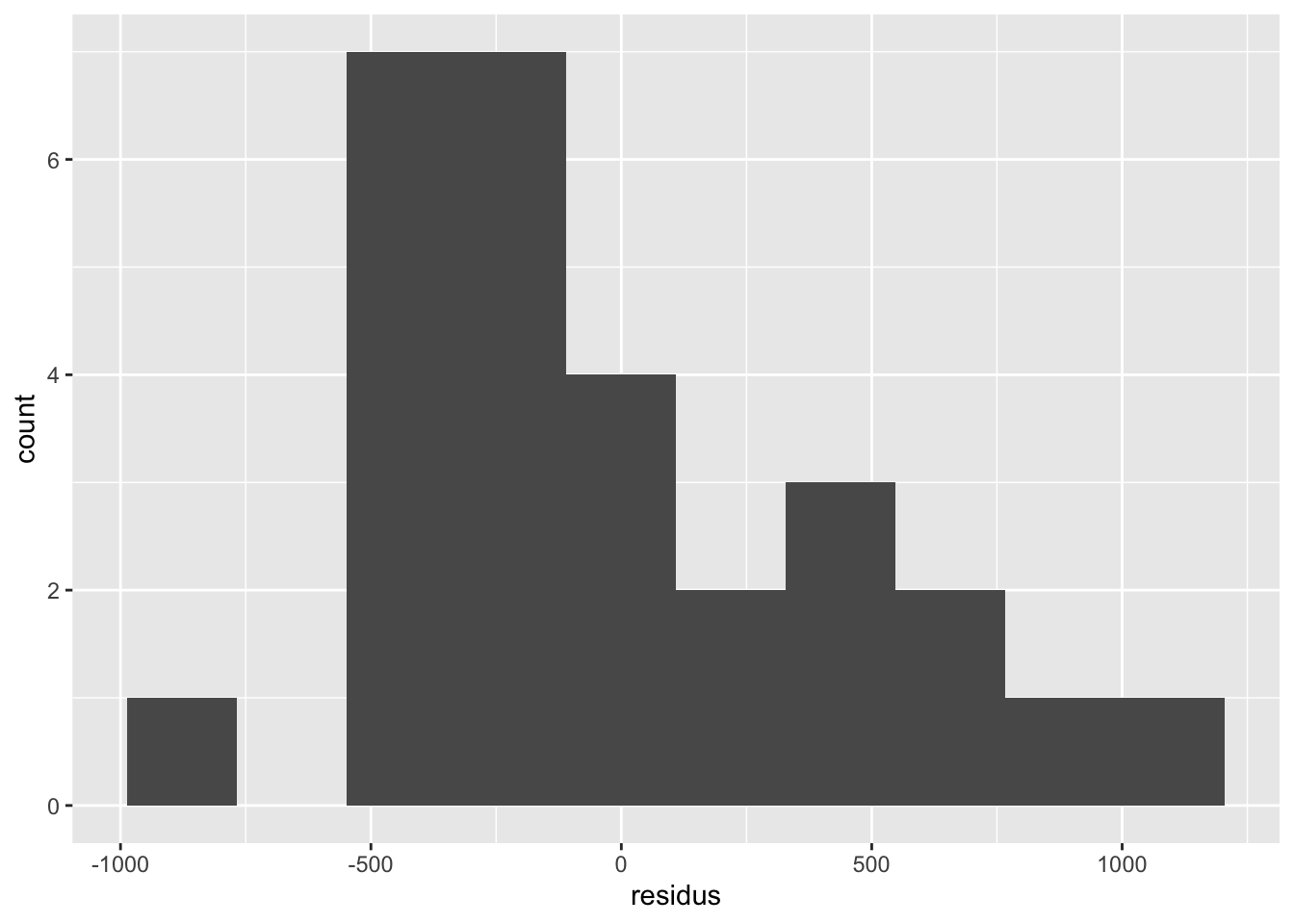
Avant de se lancer dans l’interprétation des sorties de ce modèle, nous devons par contre le valider. Comme pour la régression, nous regarderons d’abord la normalité et l’homogénéité des résidus.
Les résidus sont répartis de façon relativement normale.
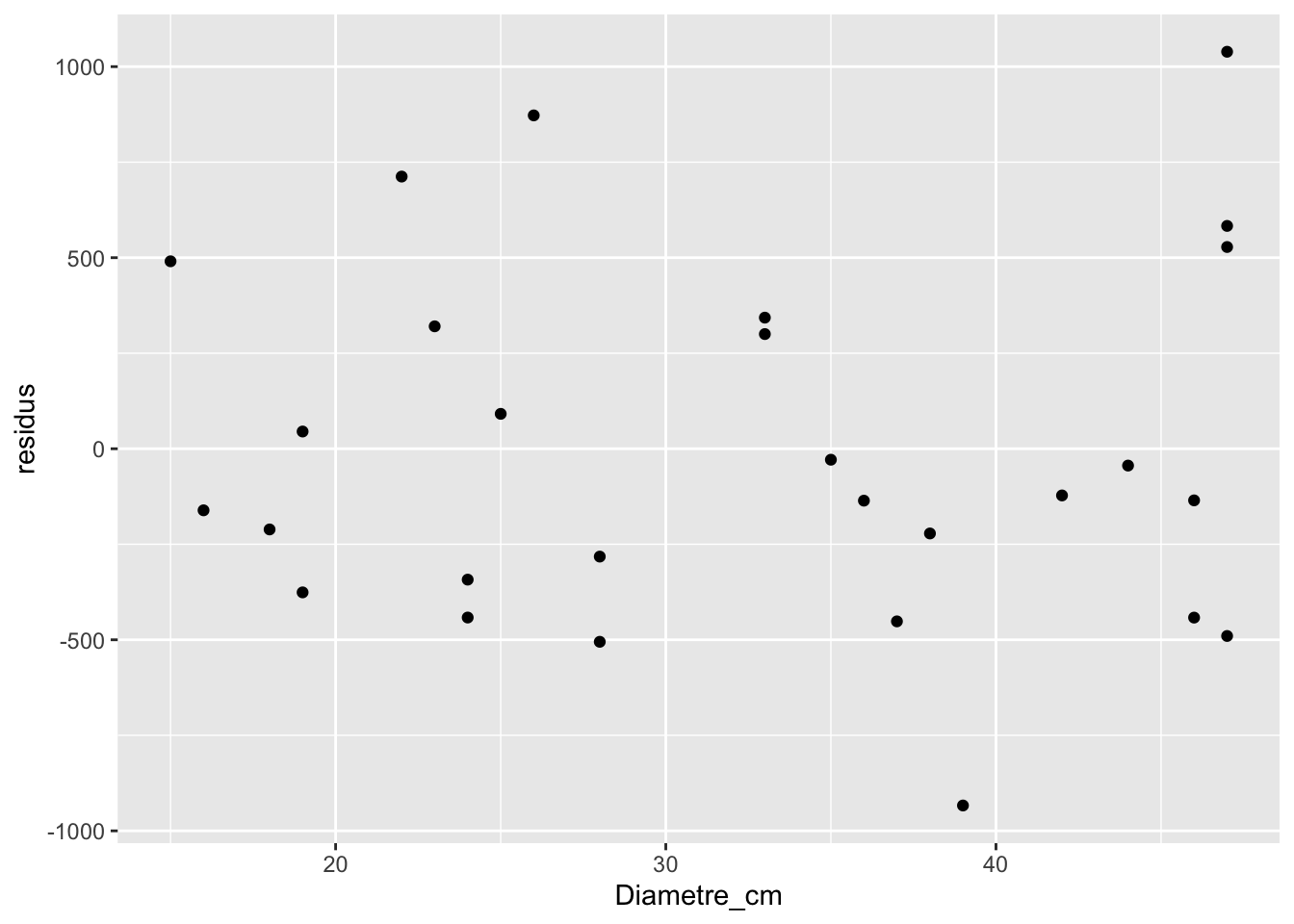
arbres |>ggplot(aes(x = Diametre_cm, y = residus)) +geom_point()
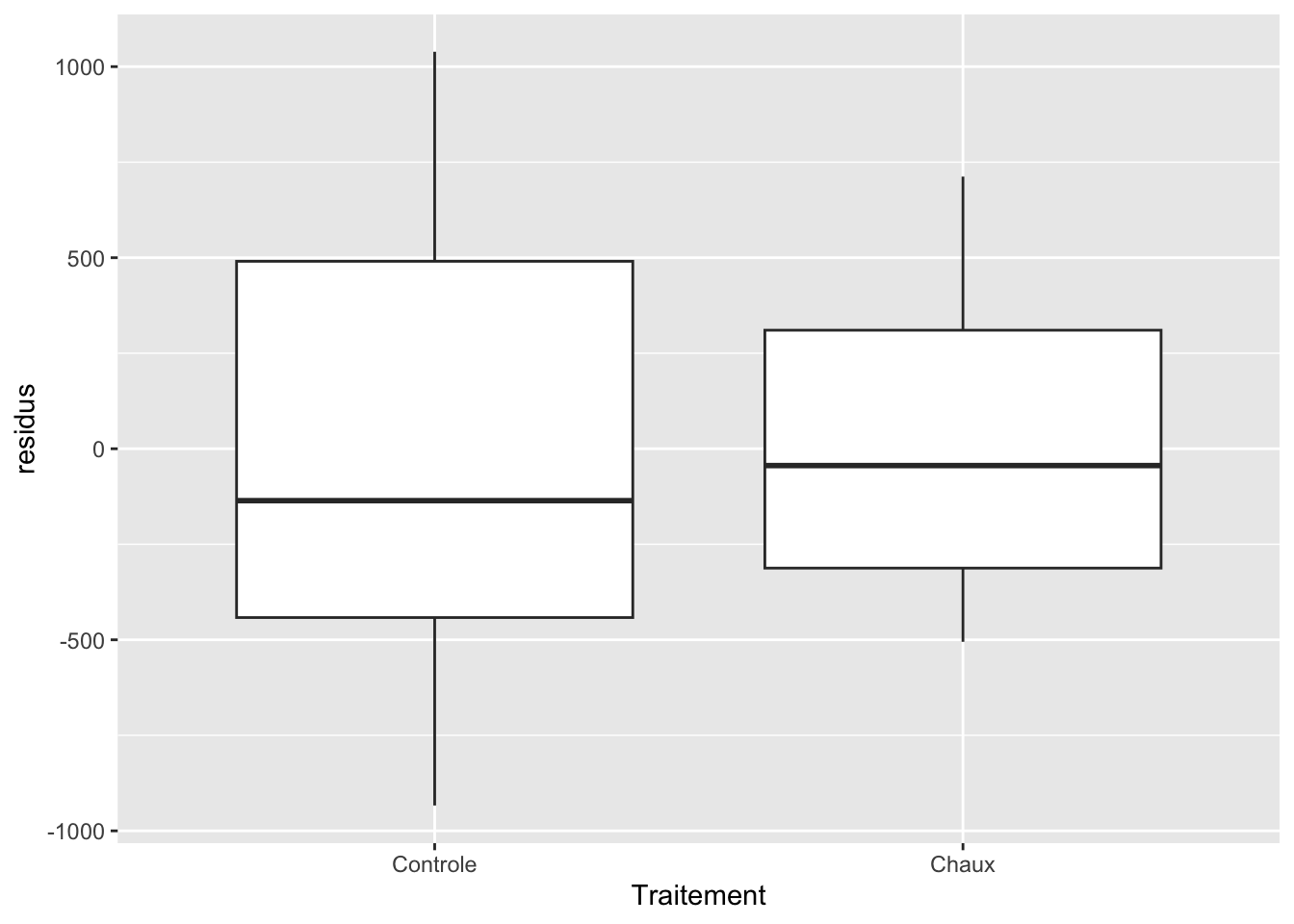
Et ils sont relativement homogènes à travers le gradient de diamètres. Mais maintenant que nous avons deux variables explicatives dans notre modèle, il faut valider l’homogénéité des résidus pour cette deuxième variable aussi. Comme il s’agit d’une variable qualitative, nous regarderons la répartition des résidus à l’aide d’un diagramme à moustache.
arbres |>ggplot(aes(x = Traitement, y = residus)) +geom_boxplot()
Les deux boîtes sont plutôt semblables, celle du traitement “Chaux” est légèrement plus étroite, mais pas de quoi s’alarmer compte tenu de la faible taille d’échantillon.
Il ne faut pas oublier de vérifier si certaines observations auraient plus influencer notre modèle de façon trop importante :
Il nous reste maintenant à valider l’assomption spécifique à l’ANOVA, soit l’homogénéité des pentes. La façon classique de tester cette assomption est d’ajouter un terme au modèle, qui servira à quantifier la différence de pente entre le groupe de référence (Controle) et l’autre groupe (Chaux).
On ajustera un nouveau modèle avec ce paramètre supplémentaire, et si il s’avère significatif, la pente ne sera pas considérée homogène entre les deux groupes et l’ANCOVA ne pourra pas être interprétée. Le modèle pour tester l’homogénéité des pentes sera donc le suivant :
\[
y = b_0+b_1x_1+b_2x_2+b_3x_1x_2
\]
Remarquez que ce nouveau paramètre (b3) est associé à la multiplication des variables x1 et x2. On nomme ce genre de paramètre une interaction, et on l’ajoute dans une formule R avec le “:”, comme ceci :
m_homogeneite <-lm(Graines~ Diametre_cm+ Traitement+ Traitement:Diametre_cm, data = arbres)summary(m_homogeneite)
Call:
lm(formula = Graines ~ Diametre_cm + Traitement + Traitement:Diametre_cm,
data = arbres)
Residuals:
Min 1Q Median 3Q Max
-921.1 -329.5 -112.8 337.7 1072.6
Coefficients:
Estimate Std. Error
(Intercept) 1077.794 453.401
Diametre_cm 96.289 12.613
TraitementChaux -1073.732 613.127
Diametre_cm:TraitementChaux 5.358 17.980
t value Pr(>|t|)
(Intercept) 2.377 0.0258 *
Diametre_cm 7.634 7.15e-08 ***
TraitementChaux -1.751 0.0927 .
Diametre_cm:TraitementChaux 0.298 0.7683
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 499.2 on 24 degrees of freedom
Multiple R-squared: 0.8734, Adjusted R-squared: 0.8575
F-statistic: 55.18 on 3 and 24 DF, p-value: 6.433e-11
Pour le moment, à l’étape de validation des assomptions, la seule partie qui nous intéresse est celle-ci :
soit le paramètre d’interaction (b3) discuté ci-haut. Comme ce dernier n’est pas significativement différent de zéro (p=0.768), on peut considérer nos pentes comme homogènes et interpréter notre modèle original.
On peut donc maintenant (enfin vous direz!) regarder les sorties de notre modèle d’ANCOVA :
summary(m)
Call:
lm(formula = Graines ~ Diametre_cm + Traitement, data = arbres)
Residuals:
Min 1Q Median 3Q Max
-933.6 -350.9 -128.7 326.1 1039.0
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 987.537 331.199 2.982 0.00631
Diametre_cm 98.926 8.823 11.212 3.04e-11
TraitementChaux -900.202 188.417 -4.778 6.63e-05
(Intercept) **
Diametre_cm ***
TraitementChaux ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 490 on 25 degrees of freedom
Multiple R-squared: 0.8729, Adjusted R-squared: 0.8627
F-statistic: 85.85 on 2 and 25 DF, p-value: 6.331e-12
Ces sorties s’interprètent exactement comme celles de la régression linéaire. À la différence que maintenant, notre modèle contient 3 paramètres (i.e. 3 lignes à la section coefficients) plutôt que 2.
Ce sont dans l’ordre nos paramètres b0 (Intercept), b1 (Diametre_cm) et b2 (TraitementChaux), soit respectivement l’ordonnée à l’origine, l’effet de la covariable et l’effet de notre variable qualitative. Comme discuté ci-haut, le paramètre b0 a peu d’interprétation biologique. Le paramètre b1 nous informe que chaque cm de diamètre de l’arbre augmente en moyenne de 98,9 graines la production de l’arbre. Enfin, le traitement de chaux diminue de 900,2 le nombre de graines produites par rapport aux arbres sans ce traitement.
Étape 5 : Rejeter ou non l’hypothèse nulle
Comme notre hypothèse portait sur paramètre b2, nous pouvons observer que sa valeur de t est de -4,778 et sa valeur de p est de 0,0000663. Comme cette valeur est plus petite que le seuil de signification de 0,05, on considère que l’effet du traitement de chaux est significativement différent de zéro.
On pourrait aussi, si on le désire, interpréter la valeur de p de notre paramètre Diametre_cm (b1), qui est aussi significativement différent de zéro.
Enfin, on voit que le r2 associé à notre modèle est de 0,87, ce qui est très élevé. Par contre, on ne sait pas si cette explication provient de l’effet de taille, du traitement de chaux ou d’une combinaison des deux. Tout ce que l’on sait, c’est que les deux ensemble expliquent 87 % de la variabilité du nombre de graines.
Étape 6 : Citer la taille de l’effet et son intervalle de confiance
Pour obtenir l’intervalle de confiance de nos paramètres, on utilise, comme pour la régression, la fonction confint, à laquelle on passe notre objet de résultat, comme ceci :
L’intervalle de confiance de notre paramètre d’intérêt (l’effet du traitement de chaux) va donc de -1288,25 à -512,15 graines.
On pourrait rapporter notre résultat comme ceci dans un rapport : «Nous avons effectué une analyse d’ANCOVA afin de d’évaluer l’effet du traitement de chaux sur la production de graines, tout en contrôlant pour le diamètre de l’arbre. Nous avons trouvé une diminution significative du nombre de graines, allant de 512,15 à 1288,25 graines de moins que le contrôle (IC 95%), ce qui était significativement différent de zéro (T25=-4,78, p=0,0000663)».
Pour présenter ce résultat de façon visuelle dans un rapport, on peut utiliser la même technique que pour la régression linéaire, soit d’utiliser la couche geom_abline pour tracer la droite de régression. Par contre, comme ici nous avons deux pentes avec deux ordonnées à l’origine différentes, nous devons utiliser la couche deux fois, comme ceci :
Notez que l’ordonnée à l’origine de la pente du traitement de chaux n’est pas -900. Elle à plutôt à 900 sous l’ordonnée à l’origine du niveau de référence. Il faut donc la placer à 987-900.
Vous remarquerez que j’ai fait bien attention ici de toujours utiliser le paramètre b1 pour la covariable et le paramètre b2 pour l’effet de la variable qualitative. Par contre, cet ordre est arbitraire. Vous auriez pu tout aussi bien mettre b1 pour la variable qualitative et b2 pour la quantitative. Soyez attentif à cette subtilité si jamais vous lisez sur le sujet ailleurs que dans mes notes de cours.
20.5 Exercice : l’ANCOVA
Pour vous entraîner à appliquer l’ANCOVA, je vous suggère avec le tableau de données sur les manchots de Palmer de répondre à la mise en situation suivante :
Nous avons vu dans les chapitres précédents que la longueur des ailes de manchots influençait leur poids. Nous aimerions maintenant savoir si il existe un dimorphisme sexuel chez les manchots, par exemple à savoir si les mâles et les femelles ont un poids différent. Nous voudrions donc corriger notre test entre les mâles et les femelles pour s’assurer que les différences de longueurs d’ailes sont correctement prises en compte dans notre comparaison du poids des manchots.