Dans les chapitres précédents (Chapitre 15,Chapitre 16), nous avons vu que pour modéliser la relation entre une variable quantitative et une variable qualitative, on devait utiliser une méthode statistique nommée ANOVA. Vous avez peut-être plutôt retenu que l’ANOVA est une méthode permettant de comparer 2+ variables quantitatives. Il s’agit en fait de deux façons différentes de décrire le même problème.
Nous avons aussi vu au Chapitre 18 que, lorsque l’on veut analyser la relation entre deux variables quantitatives, on doit plutôt utiliser la régression linéaire.
Aujourd’hui je vais vous révéler un grand secret : l’ANOVA et la régression linéaire sont en fait une seule et même procédure statistique. Eh oui! Si vous fouillez dans l’aide de la fonction aov dans R, vous y apprendrez qu’elle ne sert qu’à emballer (to wrap) la fonction lm et présenter les sorties comme on les attend dans une ANOVA.
Les deux méthodes (ANOVA et régression linéaire) ont été développées indépendamment l’une de l’autre et sont encore souvent enseignées de cette façon, car cela simplifie beaucoup leur compréhension, mais cette séparation n’est pas nécessaire. Cette révélation est d’ailleurs la clé pour comprendre comment combiner à la fois des variables quantitatives et qualitatives dans un même modèle, comme nous allons le faire dans ce chapitre.
29.2 Le secret est dans l’encodage
Pour pouvoir intégrer des variables qualitatives à un modèle de régression, il faut les transformer en chiffres, puisque c’est tout ce que la régression comprend. Il existe plusieurs façons de le faire, mais nous verrons dans ce cours uniquement la façon la plus commune : le dummy coding (désolé, je n’ai pas trouvé d’équivalent français intéressant à ce terme).
Cet encodage consiste à transformer notre variable qualitative de k valeurs (que l’on appellera désormais niveaux) en k-1 nouvelles variables qui contiennent les valeurs 0 ou 1 plutôt que du texte. Vous allez voir, avec un exemple, ça s’éclaircit…
Imaginons un tableau de données où nous avons une variable qualitative qui nous dit à quel animal correspond chaque ligne et que nous avons observé des chats, des chiens et des poissons :
Nom
Animal
Garfield
chat
Fido
chien
Hello Kitty
chat
Azraël
chat
Némo
poisson
L’encodage dummy transformera notre variable Animal en 2 nouvelles variables, soit animalChien et animalPoisson. Les lignes où nous avions effectivement un chien, la variable animalChien aura la valeur 1 et animalPoisson 0 et vice versa. Les lignes contenant un chat contiendront un 0 dans les deux variables. Voici le même tableau de données, mais avec les variables provenant de l’encodage dummy :
Nom
animalChien
animalPoisson
Garfield
0
0
Fido
1
0
Hello Kitty
0
0
Azraël
0
0
Némo
0
1
Vous aurez rarement à effectuer cet encodage vous-même, la plupart des fonctions statistiques de R le feront pour vous, mais il est très important de comprendre le fonctionnement pour bien interpréter les sorties et les éventuelles erreurs provenant du modèle, en particulier au niveau du manque de degrés de libertés.
29.3 Que se passera-t-il dans le modèle?
Comme nous l’avons vu, un des niveaux de notre variable qualitative n’aura pas de variable dummy correspondante (les chats dans notre exemple).
Important
La valeur de ce niveau manquant correspondra à l’ordonnée à l’origine de notre modèle.
On la nommera souvent niveau de référence. Le coefficient (syn. pente) associé à animalChien et animalPoisson nous informera respectivement de la différence entre un chien et un chat et de la différence entre un poisson et un chat.
Je le répète à nouveau car c’est la clé pour comprendre les variables qualitatives dans un modèle de régression multiple : tous les estimés de paramètres des variables dummy correspondent à des différences par rapport au niveau de référence (l’ordonnée à l’origine). Un estimé négatif pour animalChien ne signifie PAS une prédiction négative. Il signifie uniquement que la prédiction pour les chiens est plus petite que la prédiction pour les chats (notre référence).
29.4 Labo : Les variables qualitatives dans R
Nous avons discuté brièvement de ce sujet par le passé, mais dans R, il existe deux façons de stocker les variables qualitatives. Elles sont soit en format texte (chr), ou déjà encodées et prêtes à être entrées dans un modèle (factor).
Dans beaucoup de cas, cela ne fera pas vraiment de différence puisque beaucoup de fonctions R passent d’un format à l’autre sans vous en parler. Mais certaines fonctions comme la manipulation de texte s’effectuent mieux en format chr, alors que d’autres exigeront que vos variables soient en format factor, entre autres certaines fonctions de modélisation avancées.
Aussi, prenez note que par le passé, les fonctions qui créaient des tableaux de données convertissaient automatiquement les valeurs qualitatives en factor, mais qu’à partir de la version 4.0 de R, ce n’est plus le cas. Par contre, si vous utilisiez les fonctions fournies avec le tidyverse, alors les données sont toujours en format chr… Je sais, c’est le foutoir!
Ma recommandation est de travailler le plus possible vos données en format chr, et de les convertir au format factor à la toute dernière étape (ou presque…) avant de lancer votre modèle.
Comme nous avons discuté plus haut, l’encodage des variables qualitatives est fait de manière à ce qu’une des valeurs de notre variable soit considérée comme le niveau de référence. Par défaut, si on ne dit rien à R, il prendra la première valeur qu’il a trouvée dans le tableau comme référence.
Dans le tableau de données penguins, les variables d’espèce et de sexe sont déjà correctement encodées, mais nous ferons comme si elles ne l’étaient pas, pour que vous puissiez voir comment faire :
library(palmerpenguins)library(tidyverse)
── Attaching core tidyverse packages ──────────────────
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ───────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Pour connaître le niveau de référence d’un facteur dans R, on utilise la fonction levels. Le premier élément de chaque sortie est celui que R considère comme la référence pour cette variable. Le niveau de référence pour l’espèce sera donc “Adelie”, et celui pour le sexe sera “female”.
On peut changer le niveau de référence avec la fonction relevel, comme ceci :
Nos niveaux de référence sont maintenant “Gentoo” et “male”.
Vous remarquerez qu’il n’est pas nécessairement simple de déterminer quel devrait être le niveau de référence pour notre analyse. Parfois c’est très logique, par exemple quand on a des parcelles contrôles et d’autres avec des traitements, mais parfois c’est très arbitraire comme choix, comme ici avec nos espèces.
29.5 Attention aux degrés de liberté
À partir de maintenant, il faut se soucier plus attentivement des degrés de liberté de nos modèles lorsque nous ferons nos analyses.
Avertissement
Par le dummy coding, la régression linéaire ajuste un paramètre pour chacun des niveaux de chacune de nos variables qualitatives, moins un pour le niveau de référence.
Donc, même si dans notre modèle on inscrit quelque chose qui semble tout simple comme :
\[
\text{croissance = taille + espece}
\]
Si notre variable espece contient 8 valeurs différentes, notre modèle devra ajuster 7 paramètres différents pour l’espèce, en plus de l’ordonnée à l’origine et de la pente pour la taille. On utilisera 9 degrés de liberté. Le nombre de degrés de liberté nécessaires peut augmenter très rapidement.
En passant, sachez que pour que notre modèle soit estimé correctement, on recommande d’avoir au minimum 3 observations par niveau de notre variable qualitative (p. ex. 3 individus pour chaque espèce dans l’exemple précédent).
29.6 Labo : Les variables qualitatives dans une régression multiple
Pour ce laboratoire, nous allons modéliser les facteurs affectant le poids des manchots. Comme nous l’avons vu dans d’autres chapitres, la longueur des ailes est un facteur important contrôlant le poids des manchots. Nous allons donc conserver cette variable, mais aussi ajouter le sexe et l’espèce de l’individu, afin d’avoir un portrait plus global de la situation.
Nous passerons outre les étapes préliminaires de vérification des données pour simplifier ce chapitre, mais dans un vrai travail, il serait important de bien vérifier vos données, la forme des relations et les histogrammes de distributions avant de commencer. Il est aussi important avant de lancer la modélisation de bien réfléchir à quels niveaux des variables qualitatives serviront de référence. Ici, nous utiliserons “male” et “Gentoo”, comme nous l’avons déjà préparé ci-haut.
Voici donc comment nous pourrions ajuster un tel modèle dans R :
modele <-lm(body_mass_g ~ flipper_length_mm + sex + species, data = qualitatives)
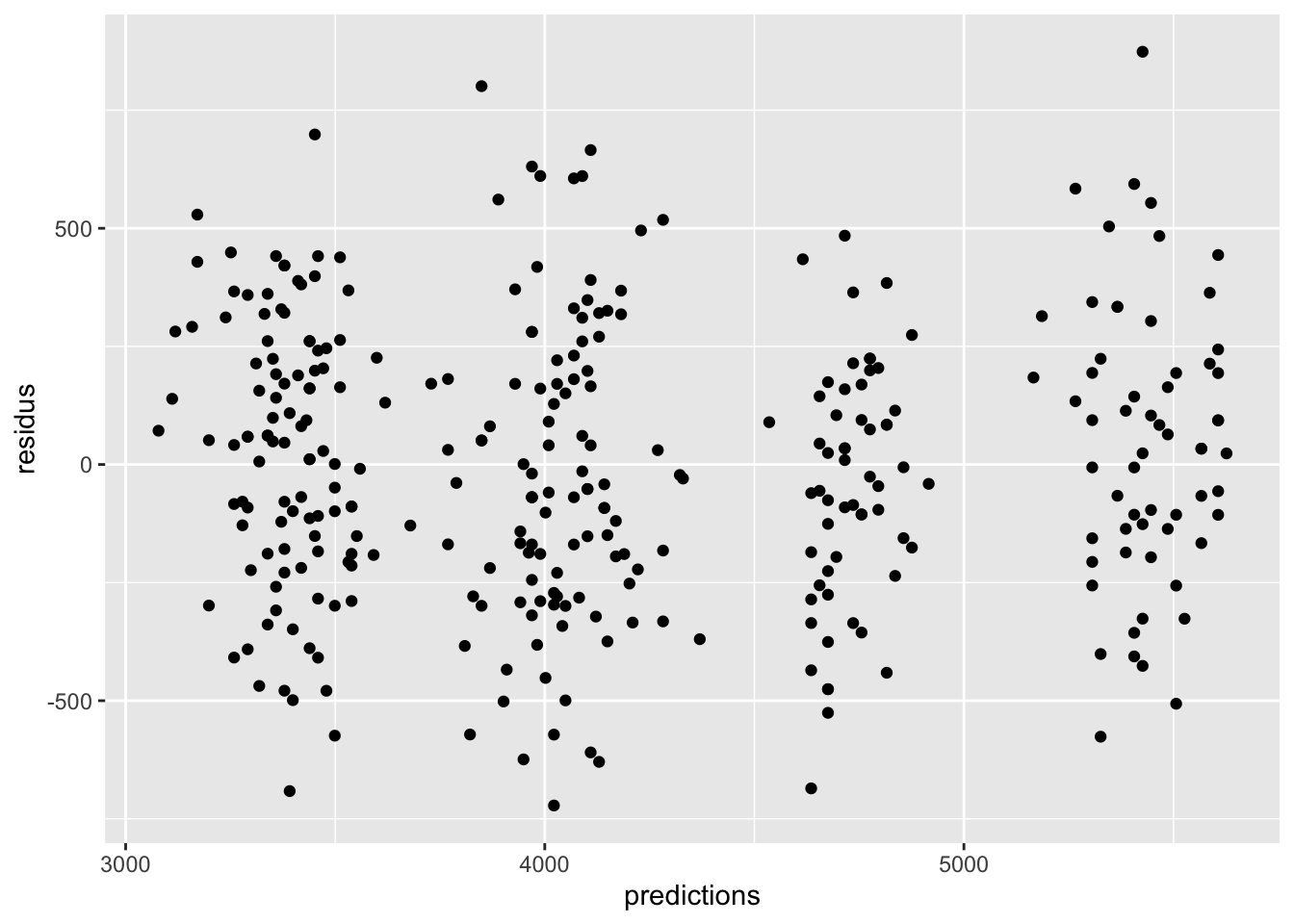
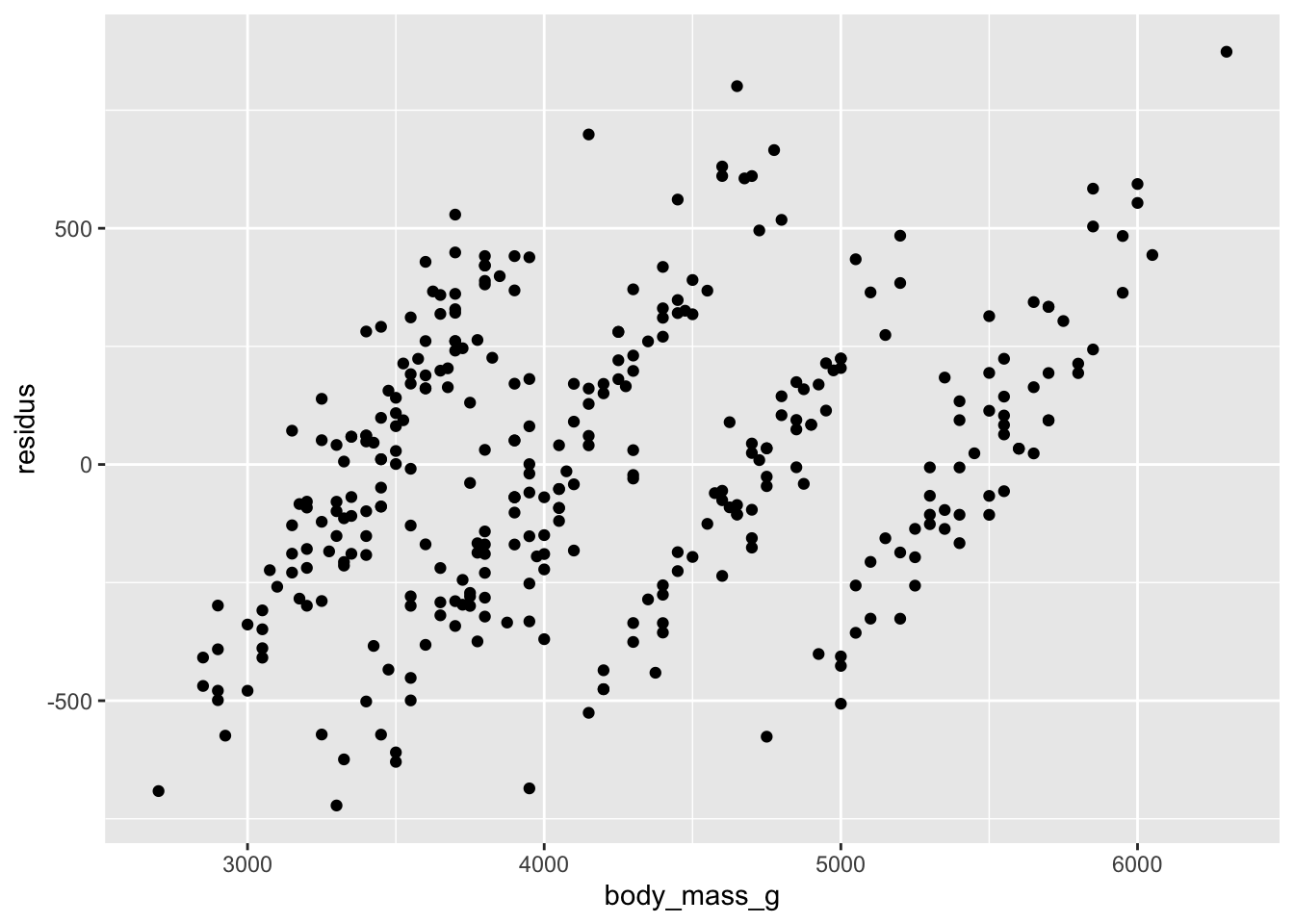
Ensuite, il faut, comme toujours, bien valider notre modèle avant de procéder à son interprétation :
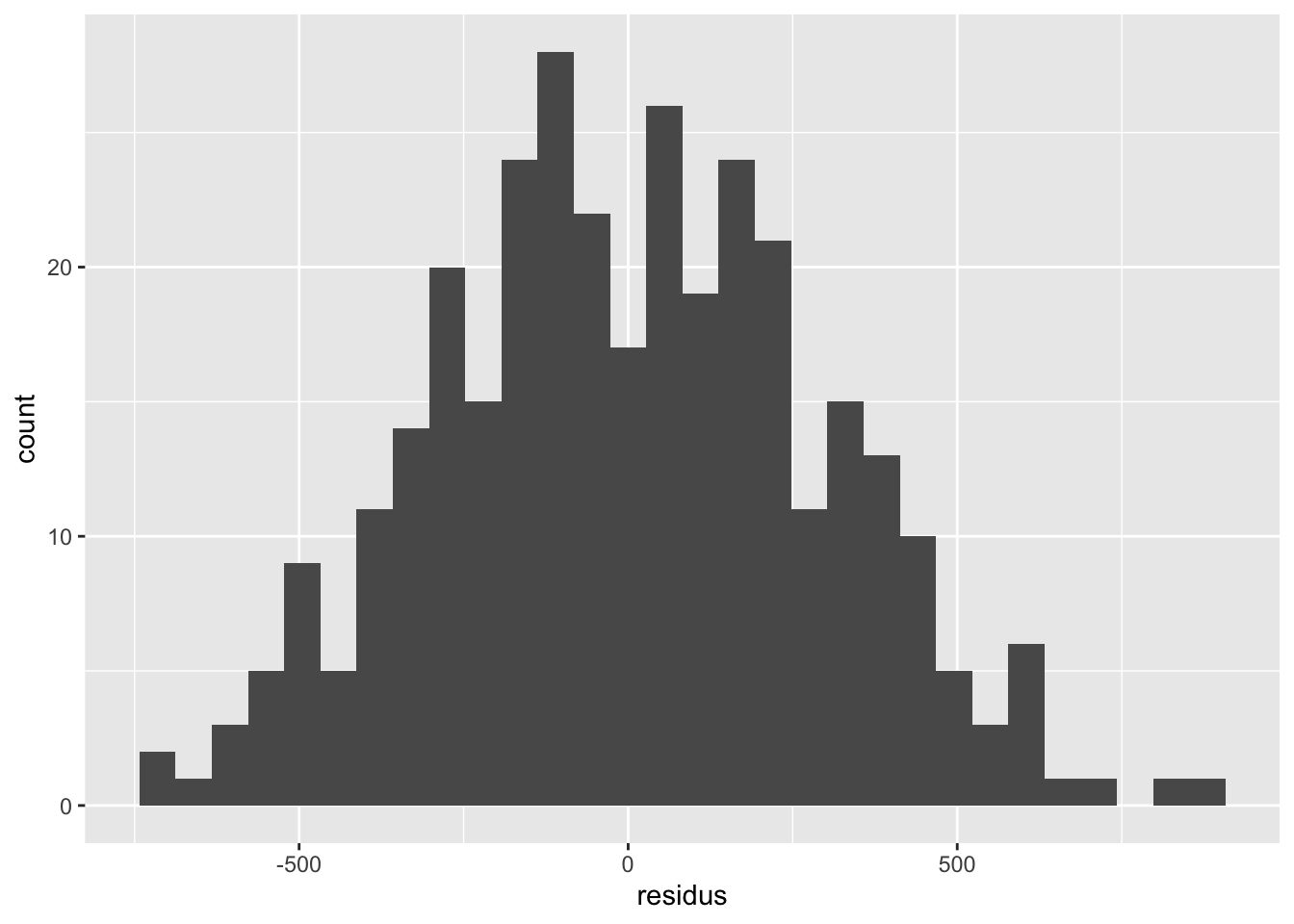
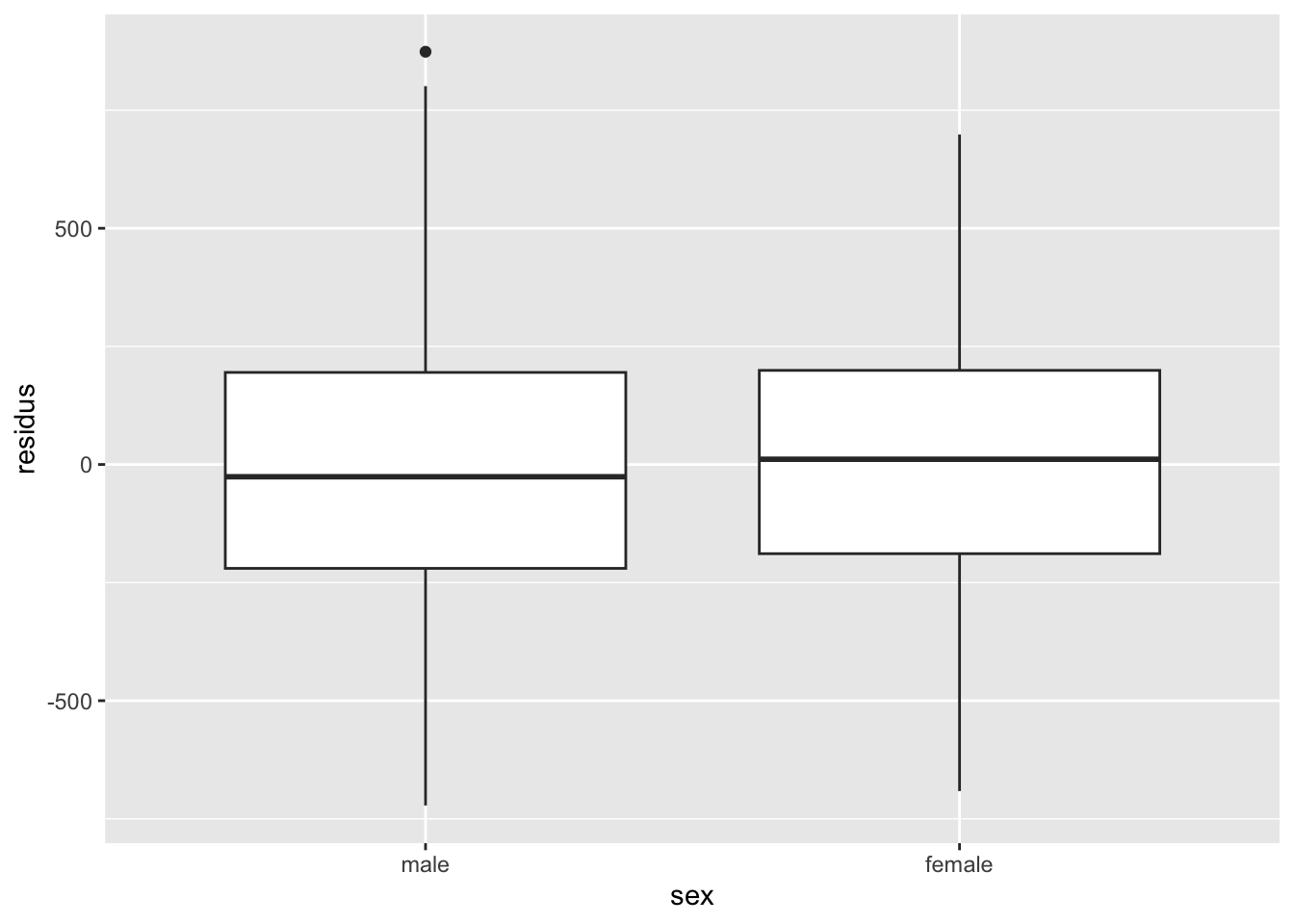
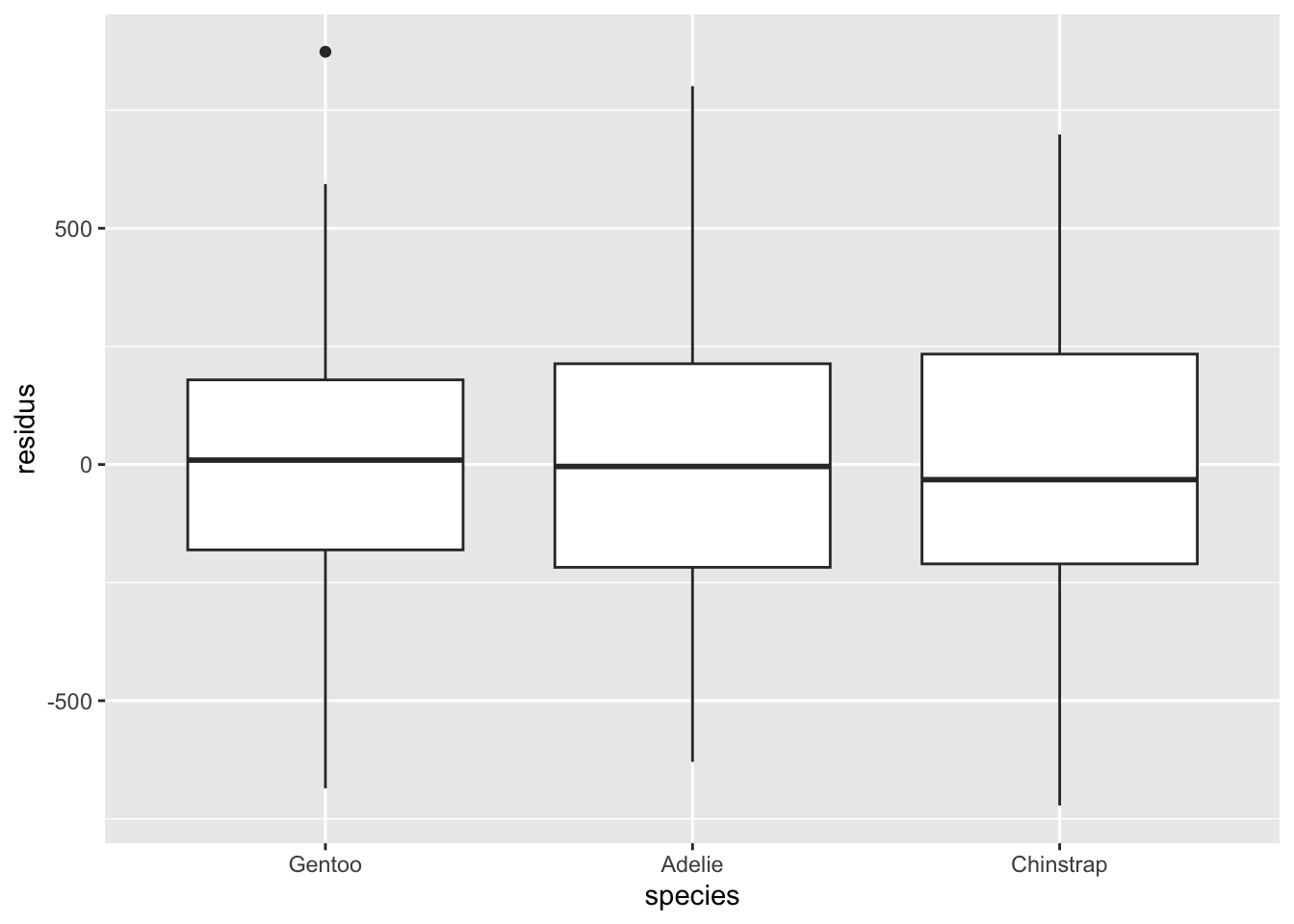
Remarquez bien que pour les variables qualitatives, l’inspection de l’homogénéité des résidus doit se faire avec des diagrammes à moustache plutôt que des nuages de points. On cherche dans ce cas à s’assurer que les boîtes ont à peu près la même taille, et sont à peu près toutes centrées sur zéro. On peut tolérer certaines différences, mais si c’est trop extrême, il y a probablement un problème avec notre modèle.
Il faut aussi s’assurer qu’aucune observation n’avait d’influence trop importante :
qualitatives |>filter(D>1)
# A tibble: 0 × 11
# ℹ 11 variables: species <fct>, island <fct>,
# bill_length_mm <dbl>, bill_depth_mm <dbl>,
# flipper_length_mm <int>, body_mass_g <int>,
# sex <fct>, year <int>, residus <dbl>,
# predictions <dbl>, D <dbl>
Et vérifier que la colinéarité entre nos variables était raisonnable :
library(car)
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
The following object is masked from 'package:purrr':
some
vif(modele)
GVIF Df GVIF^(1/(2*Df))
flipper_length_mm 6.045957 1 2.458853
sex 1.362260 1 1.167159
species 5.653123 2 1.541956
Remarquez qu’ici, la fonction vif nous présente une statistique nommée GVIF plutôt que le VIF auquel nous étions habitués. Ce changement est nécessaire parce que l’encodage des variables qualitatives (le dummy coding) dans le modèle génère plusieurs variables, qui sont artificiellement corrélées entre elles. Il faut donc utiliser un calcul alternatif nommé Generalized Variance Inflation Factor pour évaluer la colinéarité dans notre modèle1.
Nous avons vu dans le Chapitre 27 sur la régression multiple que la racine carrée du VIF représentait un facteur multiplicatif de l’erreur-type de chacun des paramètres. Pour les variables qualitatives, les statisticiens recommandent de remplacer la racine carrée par la racine 2*d.d.l. pour obtenir un facteur multiplicatif représentatif.
Une fois tous ces détails racontés, l’important de savoir est que la valeur de GVIF s’interprète exactement comme la valeur de VIF normale!
Ici, on ne s’inquiète pas trop pour le sexe et l’espèce, mais l’erreur-type du paramètre pour la longueur des ailes et près de deux fois et demi (2,46) plus important que si on n’avait pas d’ennui de collinéarité. Il serait donc important de nuancer nos conclusions concernant ce paramètre dans la présentation des résultats.
On peut maintenant regarder les résultats de notre modèle :
summary(modele)
Call:
lm(formula = body_mass_g ~ flipper_length_mm + sex + species,
data = qualitatives)
Residuals:
Min 1Q Median 3Q Max
-721.8 -195.7 -5.9 198.6 873.7
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1000.824 628.485 1.592 0.112
flipper_length_mm 20.025 2.846 7.037 1.15e-11
sexfemale -530.381 37.810 -14.027 < 2e-16
speciesAdelie -836.260 85.185 -9.817 < 2e-16
speciesChinstrap -923.894 75.511 -12.235 < 2e-16
(Intercept)
flipper_length_mm ***
sexfemale ***
speciesAdelie ***
speciesChinstrap ***
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 295.6 on 328 degrees of freedom
Multiple R-squared: 0.8669, Adjusted R-squared: 0.8653
F-statistic: 534 on 4 and 328 DF, p-value: < 2.2e-16
Les sorties sont au même format que pour la régression multiple, mais on a maintenant beaucoup plus de paramètres dans notre modèle (donc beaucoup plus de lignes dans notre sortie!).
La première ligne, comme à l’habitude est celle de l’ordonnée à l’origine (Intercept). Ici par contre, elle correspond non seulement à la valeur en Y lorsque toutes les variables quantitatives sont à zéro, mais aussi lorsque toutes les variables qualitatives sont à leur niveau de référence (ici species=“Gentoo” et sex=“male”).
On trouve d’abord la pente partielle associée à la longueur des ailes, qui nous indique que plus les ailes sont longues, plus le manchot sera lourd.
Dans la section suivante, on retrouve le paramètre décrivant la différence entre le sexe femelle et le sexe des référence (mâle). Puisque le coefficient est négatif, il nous indique que les femelles sont, en moyenne, 530 g plus légères que les mâles.
Enfin, dans la dernière section, on a les paramètres décrivant la différence de poids entre l’espèce Gentoo et les deux autres espèces. On constate que les manchots Adélie sont 836 g plus légers que les Gentoo, et que les manchots Chinstrap sont 923 g plus légers que les Gentoo.
Dans tous les cas, ces paramètres sont significativement différents de zéro, i.e. les différences et les pentes sont clairement différentes de zéro.
Note
Remarquez que le signe des paramètres dépend de la valeur de référence. Si le niveau de référence du sexe avait été femelle, on aurait eu un paramètre nommé sexmale, qui aurait eu la valeur +530.
Toutes les techniques de sélection de modèle vues dans le Chapitre 28 sont aussi valides ici.
Avertissement
Par contre, si vous prévoyez utiliser une approche basée sur l’explication de la variance et explorer la liste exhaustive de tous les modèles, il est important de savoir que la fonction regsubsets de la librairie leaps ne comprend pas l’encodage dummy.
Elle ne peut pas être utilisée si votre modèle comprend une variable qualitative. Par contre, avec une petite modification, on peut facilement exploiter la librairie MuMIn pour faire le même travail, par exemple :
library(MuMIn)modele <-lm(body_mass_g ~ flipper_length_mm + sex + species, data = qualitatives, na.action ="na.fail" )liste <-dredge(modele, extra="adjR^2")
Ici, le R2-ajusté aurait sélectionné le modèle contenant les 3 variables, et la technique basée sur l’AIC serait arrivée au même résultat.
Remarquez que j’ai dû refaire mon objet modele avec la mention na.action="na.fail" puisque je n’avais pas fait précédemment.
29.7 Le concept d’effet aléatoire
Il est possible de classifier les variables qualitatives en deux grands groupes : les effets fixes et les effets aléatoires. La différence est principalement au niveau de l’interprétation que nous voulons faire de la variable. Dans le cas d’effets fixes, la valeur estimée pour chaque niveau de la variable qualitative nous intéresse. Pour les effets aléatoires, la valeur de chaque niveau ne nous intéresse pas vraiment. Ce qui nous intéresse est de savoir comment l’effet peut être variable entre les différents niveaux.
Voici quelques pistes pour mieux reconnaître un effet fixe et un effet aléatoire :
Effet fixe :
Nous avons utilisé tous les niveaux disponibles de la variable
Si on répétait l’expérience, on réutiliserait probablement les mêmes niveaux
On ne veut pas extrapoler aux niveaux que nous n’avons pas observés
Un exemple classique serait une variable TypeDeFeuille contenant les valeurs “conifère” et “feuillu”
Effet aléatoire :
Nous n’avons utilisé qu’une partie (aléatoire) des niveaux disponibles
Si on répétait l’expérience, on utiliserait probablement des niveaux différents
Notre inférence s’applique à tous les niveaux disponibles, incluant ceux que nous n’avons pas observés.
Un exemple classique serait une variable Site
Si notre variable est Sexe et contient “Mâle”/”Femelle”/”Autre”, elle est clairement un effet fixe. Si notre variable se nomme Individu et contient le numéro du spécimen, elle est clairement un effet aléatoire.
Notez que la différence est uniquement conceptuelle. Une variable contenant le nom du lac étudié pourrait, pour un étudiant au doctorat, s’interpréter comme un effet aléatoire. Si il refaisait son expérience, il pourrait la faire ailleurs, etc. Par contre, si un biologiste d’un organisme de bassin versant faisait la même expérience, les valeurs individuelles de chaque lac pourraient l’intéresser. Il s’agirait alors d’un effet fixe.
Ce chapitre s’interessera uniquement aux variables qualitatives utilisées en effets fixes. Les effets aléatoires seront discutés dans le Chapitre 30 sur les modèles linéaires mixtes.
29.8 Les interactions
Le concept d’interaction en statistique possède une définition relativement simple, mais qui demande une certaine réflexion. On dit qu’il existe une interaction entre deux variables, lorsque l’effet d’une variable dépend de la valeur de l’autre. Notez que l’on parle ici d’interaction entre les variables explicatives. Il est implicite que toutes les variables explicatives interagissent avec la variable expliquée…
Dans le cas de variables qualitatives
Prenons l’exemple d’une expérience où l’on désire observer la productivité dans des parcelles de plantes et que l’on désire étudier l’effet de l’arrosage (“Avec”/”Sans”) et l’effet d’un ajout d’engrais (“Avec”/”Sans”). Nous avons deux variables qualitatives, qui ont chacune deux niveaux.
Nous avons mesuré les moyennes suivantes :
Sans engrais
Avec engrais
Sans arrosage
25 g m-2
50 g m-2
Avec arrosage
40 g m-2
?
Si il n’existe PAS d’interaction entre l’ajout d’engrais et l’arrosage sur la productivité, on devrait s’attendre à mesurer 65 g m-2 dans les parcelles avec engrais ET arrosage (25 g m-2 + 15 g m-2 pour l’effet de l’arrosage + 25 g m-2 pour l’effet de l’engrais). Par contre, si on mesure autre chose, par exemple 110 g m-2, alors il y a interaction entre les deux traitements. Les deux traitements ensemble n’ont pas le même effet que s’ils étaient appliqués indépendamment.
Notez que l’interaction pourrait aussi être négative, elle n’est pas obligée d’augmenter nécessairement l’effet.
Entre une variable qualitative et une variable quantitative
Si l’on reprend notre définition d’une interaction : l’effet d’une variable dépend de la valeur d’une autre, il est possible de comprendre ce qui survient lorsque l’on tente de modéliser l’interaction entre une variable qualitative et une variable quantitative. C’est comme poser la question : est-ce que la pente associée à notre variable quantitative sera la même pour chaque niveau de notre variable qualitative ou si elle changera selon la valeur que prend notre variable qualitative.
Nous avons déjà abordé ce genre de modèle sous l’appellation d’ANCOVA (voir Chapitre 20). L’ANCOVA n’est pas un modèle spécial en tant que tel. C’est uniquement l’étiquette donnée à un modèle de régression multiple qui contient une variable qualitative, une seule variable quantitative et leur interaction. Rien n’empêcherait dans un modèle d’avoir aussi d’autres variables. Mais on ne pourrait plus parler d’ANCOVA comme tel.
Dans le modèle statistique
Lorsque l’on désire modéliser une interaction dans une régression multiple, celle-ci sera ajoutée comme un nouveau terme au modèle, qui sera calculé par le logiciel comme la multiplication des termes dont on veut modéliser l’interaction.
Par exemple, si notre modèle contient les variables A et B : \[
\text{Y = A + B}
\] L’interaction entre ces deux termes sera ajoutée comme :
\[
\text{Y = A + B + A×B}
\]
On peut donc tester, par le principe des tests de F partiels (voir Chapitre 27), l’effet de l’ajout de ce terme d’interaction à notre modèle. Dans ce modèle, on peut donc tester 3 choses : est-ce que A est significatif, est-ce que B est significatif et est-ce que l’interaction entre A et B est significative.
Si cette interaction est significative, elle nous informe que l’effet des deux variables (A et B) n’est pas indépendant. Si tel est le cas, il devient hasardeux d’interpréter les pentes individuelles, puisque l’on vient de conclure qu’elles sont changeantes. On les conserve dans le modèle, mais on ne les interprète plus.
Important
Attention : il ne faut par contre jamais ajuster un modèle avec une interaction sans les deux variables correspondantes.
Quand mettre une interaction dans notre modèle?
Il n’y a pas de réponse simple à cette question. Elle dépend en premier lieu de votre question biologique. Parfois conceptuellement ça a du sens de tester une interaction, parfois non.
L’autre chose à se demander est : avons-nous suffisamment de degrés de liberté pour estimer cette interaction? Dans notre exemple précédent où nous avions ce modèle avec 8 espèces qui nécessitait 9 degrés de liberté :
\[
\text{croissance = taille + espece}
\]
Si nous ajoutons une interaction entre taille et espèce dans le modèle :
Nous aurons besoin à ce moment de 16 (!) degrés de liberté :
1 pour l’ordonnée à l’origine
1 pour la pente de la taille
7 pour les espèces (8 - 1)
7 pour les interactions taille x espèce (8 - 1)
29.9 Labo : Les interactions
Nous allons maintenant voir comment intégrer des interactions à nos modèles dans R. Comme ce chapitre commence à s’étirer un peu, nous n’allons pas valider le modèle dans cet exemple, mais dans la vraie, vous devrez le faire.
Les interactions dans R peuvent s’inscrire de deux façons, soit avec le :, ou soit avec le *.
La notation avec le : ajoute uniquement l’interaction au modèle. Nous devons manuellement ajouter aussi les termes simples, par exemple :
Y ~ X1 + X2 + X1:X2
La notation avec le * ajoute à la fois l’interaction et les deux termes simples au modèle. Le modèle précédent, peut par exemple s’écrire comme ceci :
Y ~ X1 * X2
Bien que la notation avec le * ait l’avantage d’être plus courte, je vous conseille d’appliquer celle avec le :, puisque sa façon plus longue d’écrire nous invite à penser à la quantité de paramètres que nous sommes en train d’ajouter au modèle.
Comme nous avons beaucoup de degrés de liberté, nous nous permettrons d’ajouter deux interactions à notre modèle. Tout d’abord, nous modéliserons une interaction qualitative-qualitative entre le sexe et l’espèce. Celle-ci nous permettra de savoir si la différence entre les mâles et les femelles varie entre les espèces. Nous en ajouterons aussi une deuxième, qualitative-quantitative cette fois, entre l’espèce et la longueur des ailes. Cette dernière nous permettra de savoir si la pente entre le poids et la longueur des ailes varie entre les espèces. Autrement dit, si avoir des ailes plus longues est plus payant chez certaines espèces que chez d’autres.
modele_avec_interactions <-lm( body_mass_g ~ flipper_length_mm + sex + species + sex:species + species:flipper_length_mm, data = qualitatives, na.action ="na.fail")summary(modele_avec_interactions)
Pour interpréter ce tableau, il faut bien réaliser que maintenant, l’estimé de paramètre associé à sexfemale n’est plus un estimé global. Il correspond maintenant à la différence mâle-femelle pour notre niveau de référence de la variable species (i.e. les manchots Gentoo). La ligne sexfemale:speciesChinstrap nous informe, par exemple, que la différence mâle-femelle chez les manchots Chinstrap est 403 g plus élevée que celle des manchots Gentoo. Autrement dit, chez les Gentoo, les femelles sont 597 g plus légères que chez les mâles, mais chez les manchots Chinstrap, les femelles ne sont que (-597 g + 403 g) 194 g plus légères.
Les lignes flipper_length_mm:speciesAdelie et flipper_length_mm:speciesChinstrap nous informent que la pente entre la taille du corps et la longueur des ailes est très sembable chez les 3 espèces. Celle pour les Gentoo est de 23.499 g/mm, celle pour les Adélie est (23.499-7.185) 16.313 g/mm et celle des manchots Chinstrap (23.499+3.175) es de 26.67 g/mm. Dans ce dernier cas, aucune des pentes de se distingue significativement de la pente de référence.
Comme les interactions sont un thème plutôt abstrait, il peut être utile de les visualiser pour mieux les comprendre. La fonction visreg est tout à fait appropriée pour ce genre d’exploration :
library(visreg)#| layout-ncol: 2visreg(modele_avec_interactions,"sex", by ="species")
visreg(modele_avec_interactions,"flipper_length_mm", by ="species")
On comprend mieux maintenant que les différences mâles-femelles sont presque inexisantes chez les manchots Chinstrap, mais très importantes dans les deux autres espèces. On voit aussi que les pentes poids-longueurs d’ailes sont très semblables entre les espèces. Les ordonnées à l’origine sont bien différentes, mais la pente comme tel ne se distingue pas vraiment.
Vous remarquerez peut-être que dans nos résultats, les différences entre les espèces (i.e. speciesAdelie et speciesChinstrap) ne sont plus considérées comme significativement différentes du niveau de référence. Cela arrive fréquemment, puisque maintenant, c’est l’interaction avec le sexe qui est significative. Il ne faut pas pour autant éliminer ce terme.
Prenez note aussi du fait que, bien que notre tableau de données contienne au départ 333 observations, il ne reste à notre modèle avec les interactions que 324 degrés de liberté, puisque nous devons ajuster 9 (!) paramètres pour répondre à notre question.
Enfin, on aurait pu aussi appliquer nos techniques de sélection de modèle sur ce modèles contenant les interaction :
Selon le R2-ajusté, le meilleur modèle serait celui contenant les deux interactions. Mais l’AIC, plus conservateur, aurait privilégié celui sans l’interaction entre la longueur des ailes et l’espèce. Ce dernier modèle serait, selon les poids d’Akaike, 2x plus probable que celui contenant les deux interactions (0.698/0.302=2.31).
29.10 Contenu optionnel : le modèle linéaire général
Nous avons vu dans ce chapitre que l’ANOVA et l’ANCOVA, peuvent être remplacées par une régression multiple dans laquelle on utilise le dummy coding et/ou les interactions. Ce qui est fascinant, c’est qu’en fait, l’ensemble des tests statistiques que nous avons vu ensemble jusqu’à maintenant (i.e. les chapitres Chapitre 12 à Chapitre 21) peuvent TOUS être remplacés par une régression multiple avec des variables qualitatives et/ou des interactions. C’est pourquoi on appelle cette approche le modèle linéaire général.
Par exemple, le test de T à deux échantillons peut facilement être remplacé par une régression linéaire, pour autant que l’on tourne les données au format long plutôt que large.
En réfléchissant en test de T, on aurait par exemple organisé nos données comme ceci :
Groupe A
Groupe B
12,5
13,2
11,8
14,5
…
…
On aurait pu ajuster dans R un tel modèle avec quelque chose comme :
t.test(GroupeA, GroupeB, var.equal =TRUE)
Mais on pourrait tout aussi bien organiser nos données comme ceci :
Groupe
Valeurs
A
12,5
A
11,8
B
13,2
B
14,5
…
…
Et coder notre modèle dans R comme cela :
lm(Valeurs ~ Groupe)
On obtiendrait intégralement la même valeur de p.
C’est fou hein?
Je me suis longtemps interrogé, à savoir si ça valait la peine d’enseigner toute cette panoplie de tests, quand au fond, les étudiants n’auraient besoin que du modèle linéaire général pour travailler.
Ma conclusion pour le moment est que, comme ces tests sont utilisés depuis plus d’une centaine d’années pour certains, il est important de les comprendre et de savoir les utiliser quand même. Ils sont aussi conceptuellement beaucoup plus faciles d’approche que le modèle linéaire général et font, en ce sens, une meilleure introduction aux biostatistiques.
Par contre, si le modèle linéaire général vous intrigue ou vous intéresse, je vous encourage fortement à consulter cet article, où l’auteur a décortiqué pour vous comment traduire des dizaines de tests statistiques connus au modèle linéaire général :
Vous remarquerez que dans certains cas, par exemple pour le test de khi-carré, on doit pousser un peu plus loin et utiliser un GLM à cause de l’assomption d’une distribution Poisson (plutôt que normale) des erreurs, mais l’idée générale demeure la même.
29.11 Exercice : Modéliser une variable qualitative et une interaction
Pour cet exercice, nous allons nous éloigner un peu de l’écologie est traiter d’un problème plus près de la santé publique : est-ce que le taux de cholestérol varie entre les états américains. Comme nous savons que le cholestérol a tendance à augmenter avec l’âge, nous aurons une sous-question à explorer, soit : est-ce que l’augmentation du cholestérol avec l’âge est la même entre les états américains.
Remarquez que le fichier est au format .data. Il doit donc être ouvert avec la fonction read_table2, plutôt qu’avec read_csv ou read_excel comme c’est souvent notre habitude.
Je vous demande donc 6 choses :
Chargez et vérifiez et préparez ces données
Visualisez dans un graphique la différence de pente âge-cholestérol dans les deux états américains
Effectuez une modélisation permettant de répondre à notre question principale et à notre sous-question
Validez ce modèle
Choisissez une technique de sélection du meilleur modèle et appliquez la
Interprétez les résultats pour répondre à nos deux questions
29.12 En résumé
L’ANOVA et la régression linéaire sont une seule et même procédure statistique (eh oui!).
Les variables qualitatives peuvent être transformées en plusieurs variables contenant des valeurs 0 ou 1 pour les entrer dans une régression.
Il est important de distinguer les effets aléatoires des effets fixes.
L’interaction (au sens statistique) peut être définie comme la non-indépendance des effets de deux variables.